 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-free LLM Merging for Multi-task Learning
Jun 14, 2025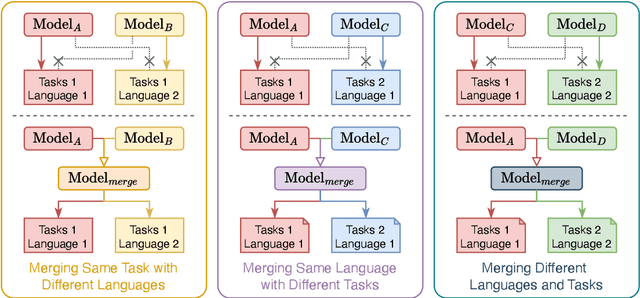
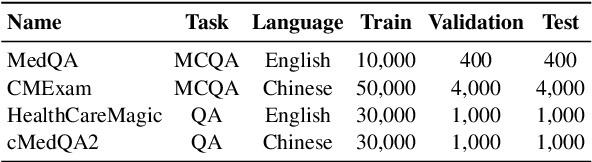
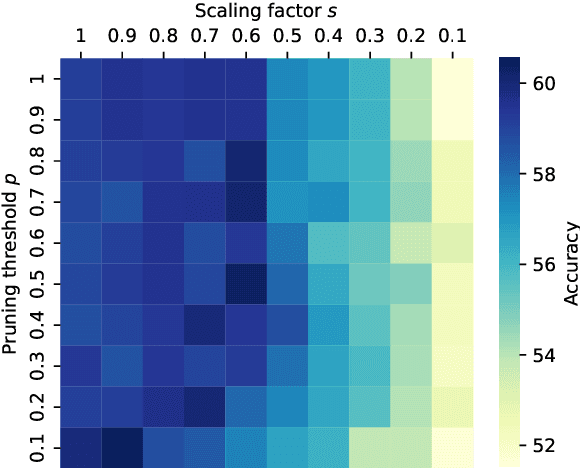
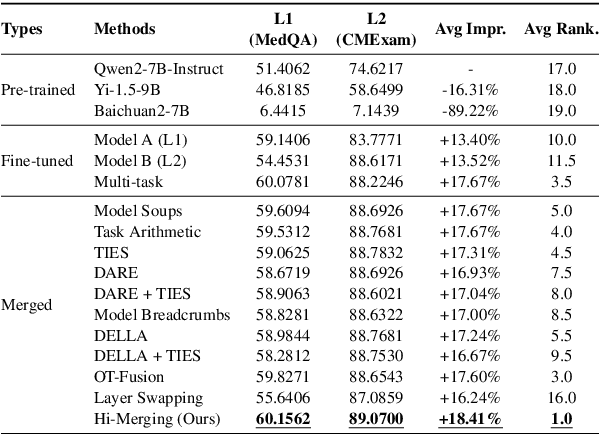
Large Language Models (LLMs) have demonstrated exceptional capabilities across diverse natural language processing (NLP) tasks. The release of open-source LLMs like LLaMA and Qwen has triggered the development of numerous fine-tuned models tailored for various tasks and languages. In this paper, we explore an important question: is it possible to combine these specialized models to create a unified model with multi-task capabilities. We introduces Hierarchical Iterative Merging (Hi-Merging), a training-free method for unifying different specialized LLMs into a single model. Specifically, Hi-Merging employs model-wise and layer-wise pruning and scaling, guided by contribution analysis, to mitigate parameter conflicts. Extensive experiments on multiple-choice and question-answering tasks in both Chinese and English validate Hi-Merging's ability for multi-task learning. The results demonstrate that Hi-Merging consistently outperforms existing merging techniques and surpasses the performance of models fine-tuned on combined datasets in most scenarios. Code is available at: https://github.com/Applied-Machine-Learning-Lab/Hi-Merging.
* 14 pages, 6 figures
Lightweight Embeddings with Graph Rewiring for Collaborative Filtering
May 25, 2025As recommendation services scale rapidly and their deployment now commonly involves resource-constrained edge devices, GNN-based recommender systems face significant challenges, including high embedding storage costs and runtime latency from graph propagations. Our previous work, LEGCF, effectively reduced embedding storage costs but struggled to maintain recommendation performance under stricter storage limits. Additionally, LEGCF did not address the extensive runtime computation costs associated with graph propagation, which involves heavy multiplication and accumulation operations (MACs). These challenges consequently hinder effective training and inference on resource-constrained edge devices. To address these limitations, we propose Lightweight Embeddings with Rewired Graph for Graph Collaborative Filtering (LERG), an improved extension of LEGCF. LERG retains LEGCFs compositional codebook structure but introduces quantization techniques to reduce the storage cost, enabling the inclusion of more meta-embeddings within the same storage. To optimize graph propagation, we pretrain the quantized compositional embedding table using the full interaction graph on resource-rich servers, after which a fine-tuning stage is engaged to identify and prune low-contribution entities via a gradient-free binary integer programming approach, constructing a rewired graph that excludes these entities (i.e., user/item nodes) from propagating signals. The quantized compositional embedding table with selective embedding participation and sparse rewired graph are transferred to edge devices which significantly reduce computation memory and inference time. Experiments on three public benchmark datasets, including an industry-scale dataset, demonstrate that LERG achieves superior recommendation performance while dramatically reducing storage and computation costs for graph-based recommendation services.
HMamba: Hyperbolic Mamba for Sequential Recommendation
May 14, 2025Sequential recommendation systems have become a cornerstone of personalized services, adept at modeling the temporal evolution of user preferences by capturing dynamic interaction sequences. Existing approaches predominantly rely on traditional models, including RNNs and Transformers. Despite their success in local pattern recognition, Transformer-based methods suffer from quadratic computational complexity and a tendency toward superficial attention patterns, limiting their ability to infer enduring preference hierarchies in sequential recommendation data. Recent advances in Mamba-based sequential models introduce linear-time efficiency but remain constrained by Euclidean geometry, failing to leverage the intrinsic hyperbolic structure of recommendation data. To bridge this gap, we propose Hyperbolic Mamba, a novel architecture that unifies the efficiency of Mamba's selective state space mechanism with hyperbolic geometry's hierarchical representational power. Our framework introduces (1) a hyperbolic selective state space that maintains curvature-aware sequence modeling and (2) stabilized Riemannian operations to enable scalable training. Experiments across four benchmarks demonstrate that Hyperbolic Mamba achieves 3-11% improvement while retaining Mamba's linear-time efficiency, enabling real-world deployment. This work establishes a new paradigm for efficient, hierarchy-aware sequential modeling.
Enhancing Treatment Effect Estimation via Active Learning: A Counterfactual Covering Perspective
May 08, 2025Although numerous complex algorithms for treatment effect estimation have been developed in recent years, their effectiveness remains limited when handling insufficiently labeled training sets due to the high cost of labeling the effect after treatment, e.g., expensive tumor imaging or biopsy procedures needed to evaluate treatment effects. Therefore, it becomes essential to actively incorporate more high-quality labeled data, all while adhering to a constrained labeling budget. To enable data-efficient treatment effect estimation, we formalize the problem through rigorous theoretical analysis within the active learning context, where the derived key measures -- \textit{factual} and \textit{counterfactual covering radius} determine the risk upper bound. To reduce the bound, we propose a greedy radius reduction algorithm, which excels under an idealized, balanced data distribution. To generalize to more realistic data distributions, we further propose FCCM, which transforms the optimization objective into the \textit{Factual} and \textit{Counterfactual Coverage Maximization} to ensure effective radius reduction during data acquisition. Furthermore, benchmarking FCCM against other baselines demonstrates its superiority across both fully synthetic and semi-synthetic datasets.
M2Rec: Multi-scale Mamba for Efficient Sequential Recommendation
May 07, 2025Sequential recommendation systems aim to predict users' next preferences based on their interaction histories, but existing approaches face critical limitations in efficiency and multi-scale pattern recognition. While Transformer-based methods struggle with quadratic computational complexity, recent Mamba-based models improve efficiency but fail to capture periodic user behaviors, leverage rich semantic information, or effectively fuse multimodal features. To address these challenges, we propose \model, a novel sequential recommendation framework that integrates multi-scale Mamba with Fourier analysis, Large Language Models (LLMs), and adaptive gating. First, we enhance Mamba with Fast Fourier Transform (FFT) to explicitly model periodic patterns in the frequency domain, separating meaningful trends from noise. Second, we incorporate LLM-based text embeddings to enrich sparse interaction data with semantic context from item descriptions. Finally, we introduce a learnable gate mechanism to dynamically balance temporal (Mamba), frequency (FFT), and semantic (LLM) features, ensuring harmonious multimodal fusion. Extensive experiments demonstrate that \model\ achieves state-of-the-art performance, improving Hit Rate@10 by 3.2\% over existing Mamba-based models while maintaining 20\% faster inference than Transformer baselines. Our results highlight the effectiveness of combining frequency analysis, semantic understanding, and adaptive fusion for sequential recommendation. Code and datasets are available at: https://anonymous.4open.science/r/M2Rec.
STAR-Rec: Making Peace with Length Variance and Pattern Diversity in Sequential Recommendation
May 06, 2025Recent deep sequential recommendation models often struggle to effectively model key characteristics of user behaviors, particularly in handling sequence length variations and capturing diverse interaction patterns. We propose STAR-Rec, a novel architecture that synergistically combines preference-aware attention and state-space modeling through a sequence-level mixture-of-experts framework. STAR-Rec addresses these challenges by: (1) employing preference-aware attention to capture both inherently similar item relationships and diverse preferences, (2) utilizing state-space modeling to efficiently process variable-length sequences with linear complexity, and (3) incorporating a mixture-of-experts component that adaptively routes different behavioral patterns to specialized experts, handling both focused category-specific browsing and diverse category exploration patterns. We theoretically demonstrate how the state space model and attention mechanisms can be naturally unified in recommendation scenarios, where SSM captures temporal dynamics through state compression while attention models both similar and diverse item relationships. Extensive experiments on four real-world datasets demonstrate that STAR-Rec consistently outperforms state-of-the-art sequential recommendation methods, particularly in scenarios involving diverse user behaviors and varying sequence lengths.
Multi-agents based User Values Mining for Recommendation
May 02, 2025



Recommender systems have rapidly evolved and become integral to many online services. However, existing systems sometimes produce unstable and unsatisfactory recommendations that fail to align with users' fundamental and long-term preferences. This is because they primarily focus on extracting shallow and short-term interests from user behavior data, which is inherently dynamic and challenging to model. Unlike these transient interests, user values are more stable and play a crucial role in shaping user behaviors, such as purchasing items and consuming content. Incorporating user values into recommender systems can help stabilize recommendation performance and ensure results better reflect users' latent preferences. However, acquiring user values is typically difficult and costly. To address this challenge, we leverage the strong language understanding, zero-shot inference, and generalization capabilities of Large Language Models (LLMs) to extract user values from users' historical interactions. Unfortunately, direct extraction using LLMs presents several challenges such as length constraints and hallucination. To overcome these issues, we propose ZOOM, a zero-shot multi-LLM collaborative framework for effective and accurate user value extraction. In ZOOM, we apply text summarization techniques to condense item content while preserving essential meaning. To mitigate hallucinations, ZOOM introduces two specialized agent roles: evaluators and supervisors, to collaboratively generate accurate user values. Extensive experiments on two widely used recommendation datasets with two state-of-the-art recommendation models demonstrate the effectiveness and generalization of our framework in automatic user value mining and recommendation performance improvement.
A Pre-Training and Adaptive Fine-Tuning Framework for Graph Anomaly Detection
Apr 19, 2025Graph anomaly detection (GAD) has garnered increasing attention in recent years, yet it remains challenging due to the scarcity of abnormal nodes and the high cost of label annotations. Graph pre-training, the two-stage learning paradigm, has emerged as an effective approach for label-efficient learning, largely benefiting from expressive neighborhood aggregation under the assumption of strong homophily. However, in GAD, anomalies typically exhibit high local heterophily, while normal nodes retain strong homophily, resulting in a complex homophily-heterophily mixture. To understand the impact of this mixed pattern on graph pre-training, we analyze it through the lens of spectral filtering and reveal that relying solely on a global low-pass filter is insufficient for GAD. We further provide a theoretical justification for the necessity of selectively applying appropriate filters to individual nodes. Building upon this insight, we propose PAF, a Pre-Training and Adaptive Fine-tuning framework specifically designed for GAD. In particular, we introduce joint training with low- and high-pass filters in the pre-training phase to capture the full spectrum of frequency information in node features. During fine-tuning, we devise a gated fusion network that adaptively combines node representations generated by both filters. Extensive experiments across ten benchmark datasets consistently demonstrate the effectiveness of PAF.
Towards Distribution Matching between Collaborative and Language Spaces for Generative Recommendation
Apr 10, 2025Generative recommendation aims to learn the underlying generative process over the entire item set to produce recommendations for users. Although it leverages non-linear probabilistic models to surpass the limited modeling capacity of linear factor models, it is often constrained by a trade-off between representation ability and tractability. With the rise of a new generation of generative methods based on pre-trained language models (LMs), incorporating LMs into general recommendation with implicit feedback has gained considerable attention. However, adapting them to generative recommendation remains challenging. The core reason lies in the mismatch between the input-output formats and semantics of generative models and LMs, making it challenging to achieve optimal alignment in the feature space. This work addresses this issue by proposing a model-agnostic generative recommendation framework called DMRec, which introduces a probabilistic meta-network to bridge the outputs of LMs with user interactions, thereby enabling an equivalent probabilistic modeling process. Subsequently, we design three cross-space distribution matching processes aimed at maximizing shared information while preserving the unique semantics of each space and filtering out irrelevant information. We apply DMRec to three different types of generative recommendation methods and conduct extensive experiments on three public datasets. The experimental results demonstrate that DMRec can effectively enhance the recommendation performance of these generative models, and it shows significant advantages over mainstream LM-enhanced recommendation methods.
Diversity-aware Dual-promotion Poisoning Attack on Sequential Recommendation
Apr 09, 2025



Sequential recommender systems (SRSs) excel in capturing users' dynamic interests, thus playing a key role in various industrial applications. The popularity of SRSs has also driven emerging research on their security aspects, where data poisoning attack for targeted item promotion is a typical example. Existing attack mechanisms primarily focus on increasing the ranks of target items in the recommendation list by injecting carefully crafted interactions (i.e., poisoning sequences), which comes at the cost of demoting users' real preferences. Consequently, noticeable recommendation accuracy drops are observed, restricting the stealthiness of the attack. Additionally, the generated poisoning sequences are prone to substantial repetition of target items, which is a result of the unitary objective of boosting their overall exposure and lack of effective diversity regularizations. Such homogeneity not only compromises the authenticity of these sequences, but also limits the attack effectiveness, as it ignores the opportunity to establish sequential dependencies between the target and many more items in the SRS. To address the issues outlined, we propose a Diversity-aware Dual-promotion Sequential Poisoning attack method named DDSP for SRSs. Specifically, by theoretically revealing the conflict between recommendation and existing attack objectives, we design a revamped attack objective that promotes the target item while maintaining the relevance of preferred items in a user's ranking list. We further develop a diversity-aware, auto-regressive poisoning sequence generator, where a re-ranking method is in place to sequentially pick the optimal items by integrating diversity constraints.