 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End 3D Dense Captioning with Vote2Cap-DETR
Jan 06, 2023



3D dense captioning aims to generate multiple captions localized with their associated object regions. Existing methods follow a sophisticated ``detect-then-describe'' pipeline equipped with numerous hand-crafted components. However, these hand-crafted components would yield suboptimal performance given cluttered object spatial and class distributions among different scenes. In this paper, we propose a simple-yet-effective transformer framework Vote2Cap-DETR based on recent popular \textbf{DE}tection \textbf{TR}ansformer (DETR). Compared with prior arts, our framework has several appealing advantages: 1) Without resorting to numerous hand-crafted components, our method is based on a full transformer encoder-decoder architecture with a learnable vote query driven object decoder, and a caption decoder that produces the dense captions in a set-prediction manner. 2) In contrast to the two-stage scheme, our method can perform detection and captioning in one-stage. 3) Without bells and whistles, extensive experiments on two commonly used datasets, ScanRefer and Nr3D, demonstrate that our Vote2Cap-DETR surpasses current state-of-the-arts by 11.13\% and 7.11\% in CIDEr@0.5IoU, respectively. Codes will be released soon.
Exploiting Semantic Role Contextualized Video Features for Multi-Instance Text-Video Retrieval EPIC-KITCHENS-100 Multi-Instance Retrieval Challenge 2022
Jun 29, 2022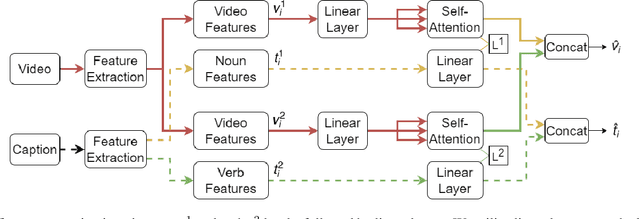
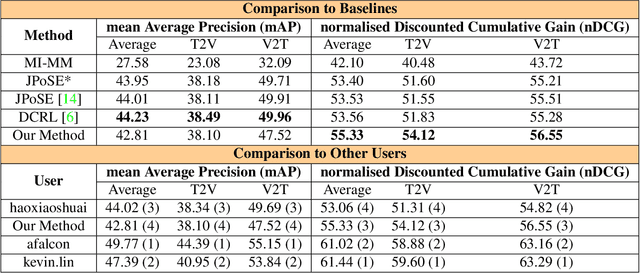
In this report, we present our approach for EPIC-KITCHENS-100 Multi-Instance Retrieval Challenge 2022. We first parse sentences into semantic roles corresponding to verbs and nouns; then utilize self-attentions to exploit semantic role contextualized video features along with textual features via triplet losses in multiple embedding spaces. Our method overpasses the strong baseline in normalized Discounted Cumulative Gain (nDCG), which is more valuable for semantic similarity. Our submission is ranked 3rd for nDCG and ranked 4th for mAP.
Semantic Role Aware Correlation Transformer for Text to Video Retrieval
Jun 26, 2022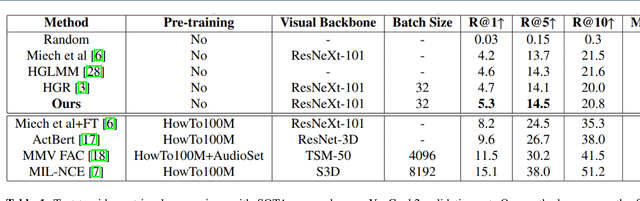

With the emergence of social media, voluminous video clips are uploaded every day, and retrieving the most relevant visual content with a language query becomes critical. Most approaches aim to learn a joint embedding space for plain textual and visual contents without adequately exploiting their intra-modality structures and inter-modality correlations. This paper proposes a novel transformer that explicitly disentangles the text and video into semantic roles of objects, spatial contexts and temporal contexts with an attention scheme to learn the intra- and inter-role correlations among the three roles to discover discriminative features for matching at different levels. The preliminary results on popular YouCook2 indicate that our approach surpasses a current state-of-the-art method, with a high margin in all metrics. It also overpasses two SOTA methods in terms of two metrics.
* Camera-ready for ICIP 2021
RoME: Role-aware Mixture-of-Expert Transformer for Text-to-Video Retrieval
Jun 26, 2022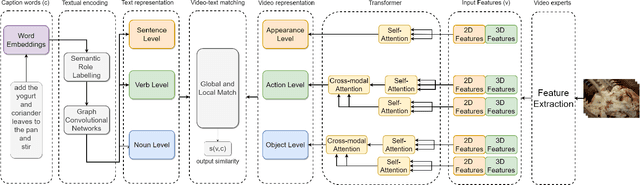
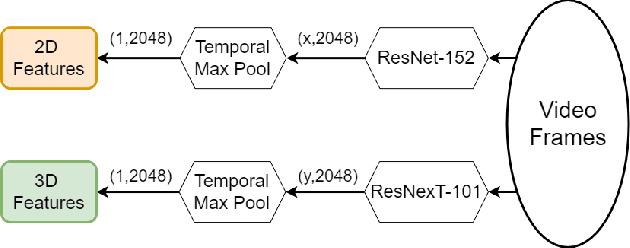
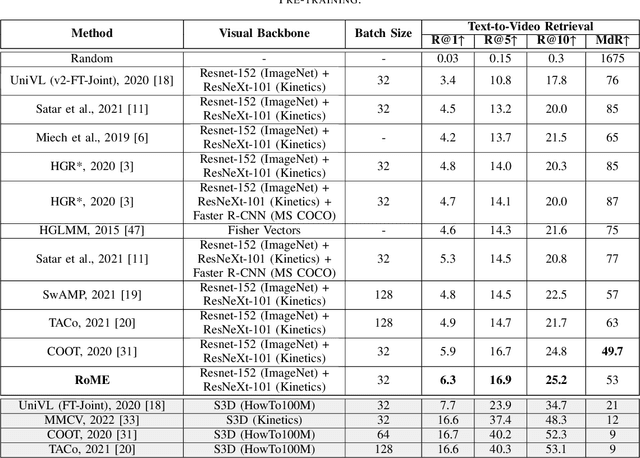
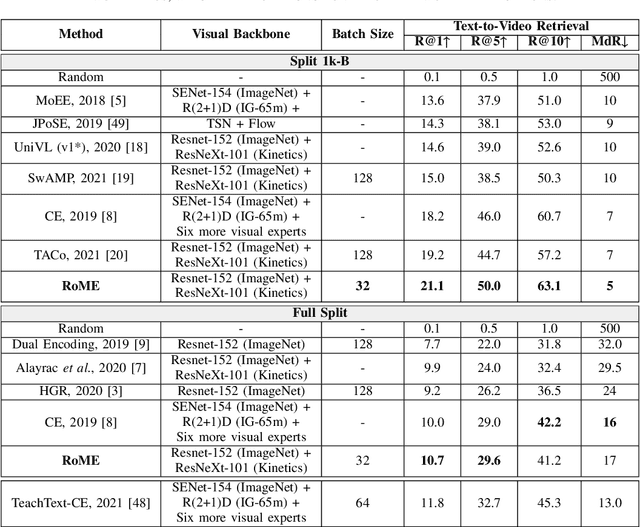
Seas of videos are uploaded daily with the popularity of social channels; thus, retrieving the most related video contents with user textual queries plays a more crucial role. Most methods consider only one joint embedding space between global visual and textual features without considering the local structures of each modality. Some other approaches consider multiple embedding spaces consisting of global and local features separately, ignoring rich inter-modality correlations. We propose a novel mixture-of-expert transformer RoME that disentangles the text and the video into three levels; the roles of spatial contexts, temporal contexts, and object contexts. We utilize a transformer-based attention mechanism to fully exploit visual and text embeddings at both global and local levels with mixture-of-experts for considering inter-modalities and structures' correlations. The results indicate that our method outperforms the state-of-the-art methods on the YouCook2 and MSR-VTT datasets, given the same visual backbone without pre-training. Finally, we conducted extensive ablation studies to elucidate our design choices.
OPQ: Compressing Deep Neural Networks with One-shot Pruning-Quantization
May 23, 2022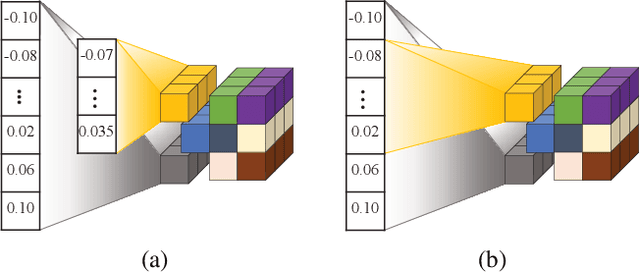
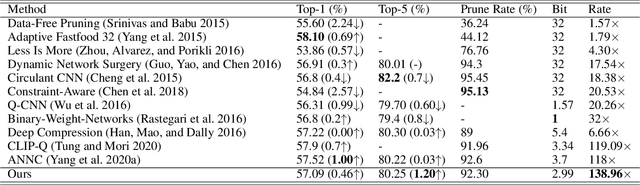
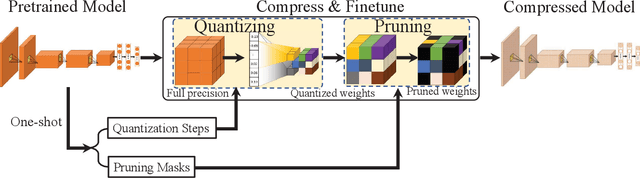

As Deep Neural Networks (DNNs) usually are overparameterized and have millions of weight parameters, it is challenging to deploy these large DNN models on resource-constrained hardware platforms, e.g., smartphones. Numerous network compression methods such as pruning and quantization are proposed to reduce the model size significantly, of which the key is to find suitable compression allocation (e.g., pruning sparsity and quantization codebook) of each layer. Existing solutions obtain the compression allocation in an iterative/manual fashion while finetuning the compressed model, thus suffering from the efficiency issue. Different from the prior art, we propose a novel One-shot Pruning-Quantization (OPQ) in this paper, which analytically solves the compression allocation with pre-trained weight parameters only. During finetuning, the compression module is fixed and only weight parameters are updated. To our knowledge, OPQ is the first work that reveals pre-trained model is sufficient for solving pruning and quantization simultaneously, without any complex iterative/manual optimization at the finetuning stage. Furthermore, we propose a unified channel-wise quantization method that enforces all channels of each layer to share a common codebook, which leads to low bit-rate allocation without introducing extra overhead brought by traditional channel-wise quantization. Comprehensive experiments on ImageNet with AlexNet/MobileNet-V1/ResNet-50 show that our method improves accuracy and training efficiency while obtains significantly higher compression rates compared to the state-of-the-art.
CRAFT: Cross-Attentional Flow Transformer for Robust Optical Flow
Mar 31, 2022
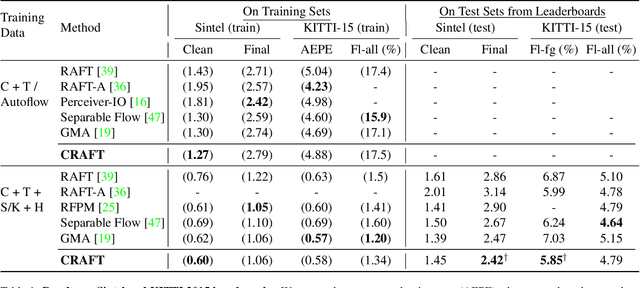
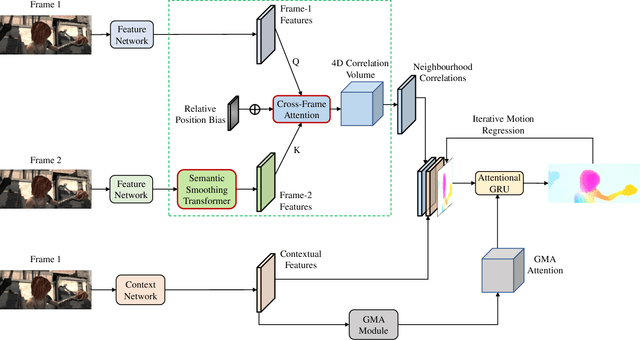
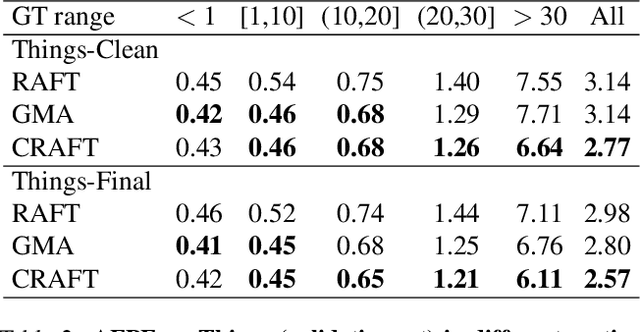
Optical flow estimation aims to find the 2D motion field by identifying corresponding pixels between two images. Despite the tremendous progress of deep learning-based optical flow methods, it remains a challenge to accurately estimate large displacements with motion blur. This is mainly because the correlation volume, the basis of pixel matching, is computed as the dot product of the convolutional features of the two images. The locality of convolutional features makes the computed correlations susceptible to various noises. On large displacements with motion blur, noisy correlations could cause severe errors in the estimated flow. To overcome this challenge, we propose a new architecture "CRoss-Attentional Flow Transformer" (CRAFT), aiming to revitalize the correlation volume computation. In CRAFT, a Semantic Smoothing Transformer layer transforms the features of one frame, making them more global and semantically stable. In addition, the dot-product correlations are replaced with transformer Cross-Frame Attention. This layer filters out feature noises through the Query and Key projections, and computes more accurate correlations. On Sintel (Final) and KITTI (foreground) benchmarks, CRAFT has achieved new state-of-the-art performance. Moreover, to test the robustness of different models on large motions, we designed an image shifting attack that shifts input images to generate large artificial motions. Under this attack, CRAFT performs much more robustly than two representative methods, RAFT and GMA. The code of CRAFT is is available at https://github.com/askerlee/craft.
Hierarchical Point Cloud Encoding and Decoding with Lightweight Self-Attention based Model
Feb 13, 2022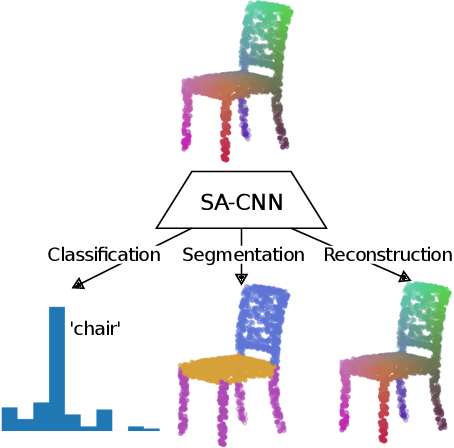
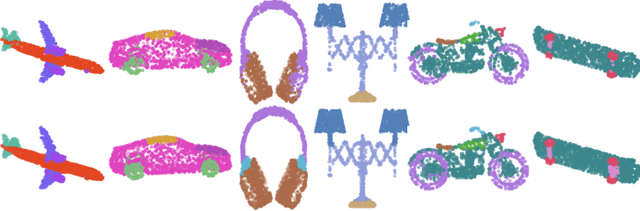

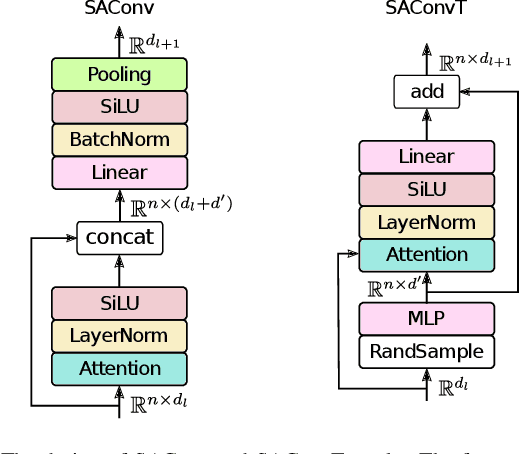
In this paper we present SA-CNN, a hierarchical and lightweight self-attention based encoding and decoding architecture for representation learning of point cloud data. The proposed SA-CNN introduces convolution and transposed convolution stacks to capture and generate contextual information among unordered 3D points. Following conventional hierarchical pipeline, the encoding process extracts feature in local-to-global manner, while the decoding process generates feature and point cloud in coarse-to-fine, multi-resolution stages. We demonstrate that SA-CNN is capable of a wide range of applications, namely classification, part segmentation, reconstruction, shape retrieval, and unsupervised classification. While achieving the state-of-the-art or comparable performance in the benchmarks, SA-CNN maintains its model complexity several order of magnitude lower than the others. In term of qualitative results, we visualize the multi-stage point cloud reconstructions and latent walks on rigid objects as well as deformable non-rigid human and robot models.
Point Cloud Instance Segmentation with Semi-supervised Bounding-Box Mining
Nov 30, 2021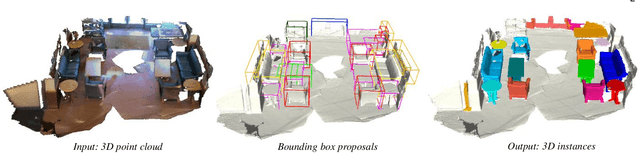
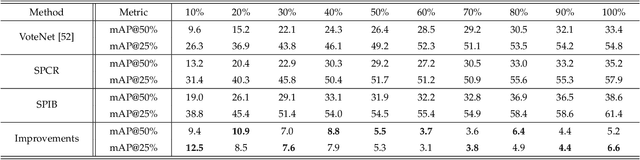
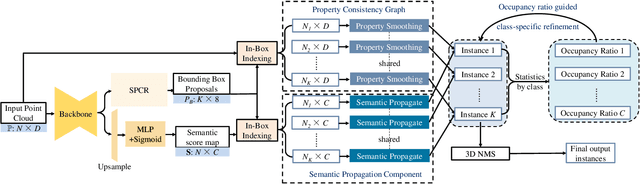
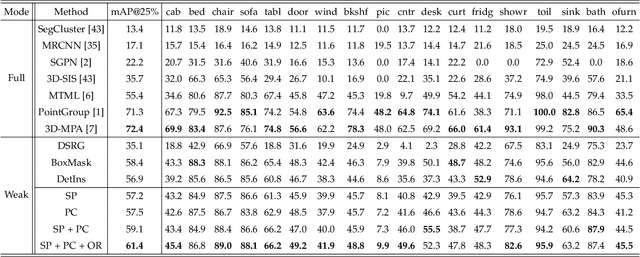
Point cloud instance segmentation has achieved huge progress with the emergence of deep learning. However, these methods are usually data-hungry with expensive and time-consuming dense point cloud annotations. To alleviate the annotation cost, unlabeled or weakly labeled data is still less explored in the task. In this paper, we introduce the first semi-supervised point cloud instance segmentation framework (SPIB) using both labeled and unlabelled bounding boxes as supervision. To be specific, our SPIB architecture involves a two-stage learning procedure. For stage one, a bounding box proposal generation network is trained under a semi-supervised setting with perturbation consistency regularization (SPCR). The regularization works by enforcing an invariance of the bounding box predictions over different perturbations applied to the input point clouds, to provide self-supervision for network learning. For stage two, the bounding box proposals with SPCR are grouped into some subsets, and the instance masks are mined inside each subset with a novel semantic propagation module and a property consistency graph module. Moreover, we introduce a novel occupancy ratio guided refinement module to refine the instance masks. Extensive experiments on the challenging ScanNet v2 dataset demonstrate our method can achieve competitive performance compared with the recent fully-supervised methods.
A Survey of Embodied AI: From Simulators to Research Tasks
Mar 14, 2021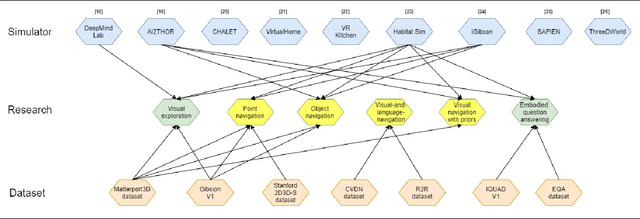
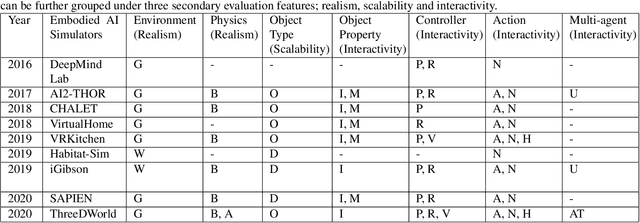


There has been an emerging paradigm shift from the era of "internet AI" to "embodied AI", whereby AI algorithms and agents no longer simply learn from datasets of images, videos or text curated primarily from the internet. Instead, they learn through embodied physical interactions with their environments, whether real or simulated. Consequently, there has been substantial growth in the demand for embodied AI simulators to support a diversity of embodied AI research tasks. This growing interest in embodied AI is beneficial to the greater pursuit of artificial general intelligence, but there is no contemporary and comprehensive survey of this field. This paper comprehensively surveys state-of-the-art embodied AI simulators and research, mapping connections between these. By benchmarking nine state-of-the-art embodied AI simulators in terms of seven features, this paper aims to understand the simulators in their provision for use in embodied AI research. Finally, based upon the simulators and a pyramidal hierarchy of embodied AI research tasks, this paper surveys the main research tasks in embodied AI -- visual exploration, visual navigation and embodied question answering (QA), covering the state-of-the-art approaches, evaluation and datasets.
Efficient Robotic Task Generalization Using Deep Model Fusion Reinforcement Learning
Dec 11, 2019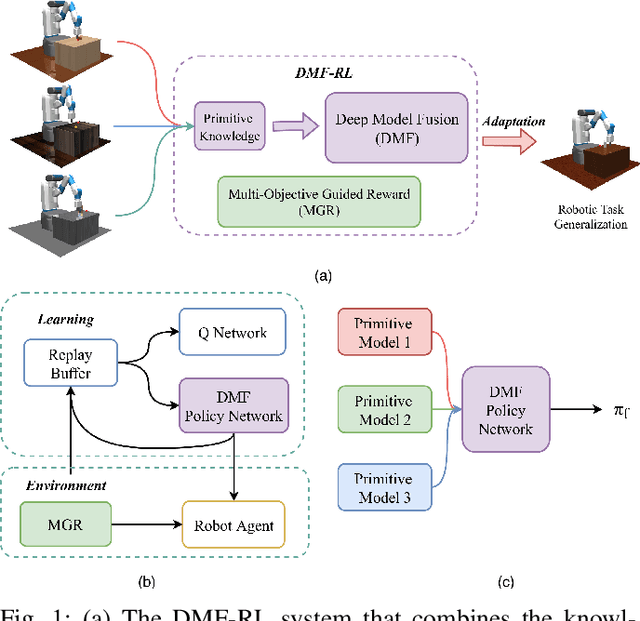
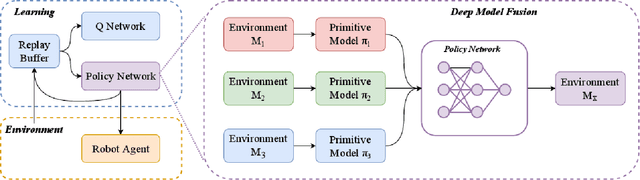
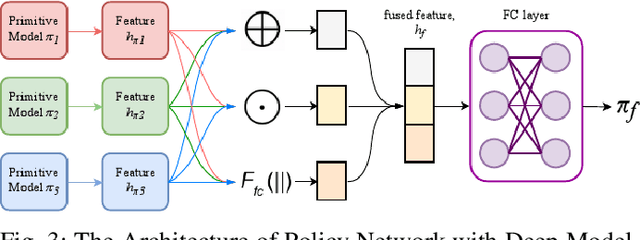
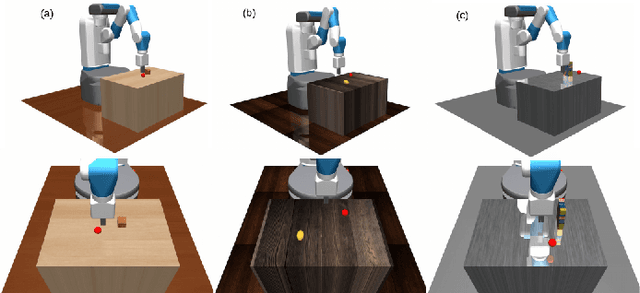
Learning-based methods have been used to pro-gram robotic tasks in recent years. However, extensive training is usually required not only for the initial task learning but also for generalizing the learned model to the same task but in different environments. In this paper, we propose a novel Deep Reinforcement Learning algorithm for efficient task generalization and environment adaptation in the robotic task learning problem. The proposed method is able to efficiently generalize the previously learned task by model fusion to solve the environment adaptation problem. The proposed Deep Model Fusion (DMF) method reuses and combines the previously trained model to improve the learning efficiency and results.Besides, we also introduce a Multi-objective Guided Reward(MGR) shaping technique to further improve training efficiency.The proposed method was benchmarked with previous methods in various environments to validate its effectiveness.