 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFiber Transmission Model with Parameterized Inputs based on GPT-PINN Neural Network
Aug 19, 2024



In this manuscript, a novelty principle driven fiber transmission model for short-distance transmission with parameterized inputs is put forward. By taking into the account of the previously proposed principle driven fiber model, the reduced basis expansion method and transforming the parameterized inputs into parameterized coefficients of the Nonlinear Schrodinger Equations, universal solutions with respect to inputs corresponding to different bit rates can all be obtained without the need of re-training the whole model. This model, once adopted, can have prominent advantages in both computation efficiency and physical background. Besides, this model can still be effectively trained without the needs of transmitted signals collected in advance. Tasks of on-off keying signals with bit rates ranging from 2Gbps to 50Gbps are adopted to demonstrate the fidelity of the model.
Principle Driven Parameterized Fiber Model based on GPT-PINN Neural Network
Aug 19, 2024In cater the need of Beyond 5G communications, large numbers of data driven artificial intelligence based fiber models has been put forward as to utilize artificial intelligence's regression ability to predict pulse evolution in fiber transmission at a much faster speed compared with the traditional split step Fourier method. In order to increase the physical interpretabiliy, principle driven fiber models have been proposed which inserts the Nonlinear Schodinger Equation into their loss functions. However, regardless of either principle driven or data driven models, they need to be re-trained the whole model under different transmission conditions. Unfortunately, this situation can be unavoidable when conducting the fiber communication optimization work. If the scale of different transmission conditions is large, then the whole model needs to be retrained large numbers of time with relatively large scale of parameters which may consume higher time costs. Computing efficiency will be dragged down as well. In order to address this problem, we propose the principle driven parameterized fiber model in this manuscript. This model breaks down the predicted NLSE solution with respect to one set of transmission condition into the linear combination of several eigen solutions which were outputted by each pre-trained principle driven fiber model via the reduced basis method. Therefore, the model can greatly alleviate the heavy burden of re-training since only the linear combination coefficients need to be found when changing the transmission condition. Not only strong physical interpretability can the model posses, but also higher computing efficiency can be obtained. Under the demonstration, the model's computational complexity is 0.0113% of split step Fourier method and 1% of the previously proposed principle driven fiber model.
Data-free Multi-label Image Recognition via LLM-powered Prompt Tuning
Mar 02, 2024This paper proposes a novel framework for multi-label image recognition without any training data, called data-free framework, which uses knowledge of pre-trained Large Language Model (LLM) to learn prompts to adapt pretrained Vision-Language Model (VLM) like CLIP to multilabel classification. Through asking LLM by well-designed questions, we acquire comprehensive knowledge about characteristics and contexts of objects, which provides valuable text descriptions for learning prompts. Then we propose a hierarchical prompt learning method by taking the multi-label dependency into consideration, wherein a subset of category-specific prompt tokens are shared when the corresponding objects exhibit similar attributes or are more likely to co-occur. Benefiting from the remarkable alignment between visual and linguistic semantics of CLIP, the hierarchical prompts learned from text descriptions are applied to perform classification of images during inference. Our framework presents a new way to explore the synergies between multiple pre-trained models for novel category recognition. Extensive experiments on three public datasets (MS-COCO, VOC2007, and NUS-WIDE) demonstrate that our method achieves better results than the state-of-the-art methods, especially outperforming the zero-shot multi-label recognition methods by 4.7% in mAP on MS-COCO.
REPOFUSE: Repository-Level Code Completion with Fused Dual Context
Feb 23, 2024



The success of language models in code assistance has spurred the proposal of repository-level code completion as a means to enhance prediction accuracy, utilizing the context from the entire codebase. However, this amplified context can inadvertently increase inference latency, potentially undermining the developer experience and deterring tool adoption - a challenge we termed the Context-Latency Conundrum. This paper introduces REPOFUSE, a pioneering solution designed to enhance repository-level code completion without the latency trade-off. REPOFUSE uniquely fuses two types of context: the analogy context, rooted in code analogies, and the rationale context, which encompasses in-depth semantic relationships. We propose a novel rank truncated generation (RTG) technique that efficiently condenses these contexts into prompts with restricted size. This enables REPOFUSE to deliver precise code completions while maintaining inference efficiency. Through testing with the CrossCodeEval suite, REPOFUSE has demonstrated a significant leap over existing models, achieving a 40.90% to 59.75% increase in exact match (EM) accuracy for code completions and a 26.8% enhancement in inference speed. Beyond experimental validation, REPOFUSE has been integrated into the workflow of a large enterprise, where it actively supports various coding tasks.
Top in Chinese Data Processing: English Code Models
Jan 25, 2024



While the alignment between tasks and training corpora is a fundamental consensus in the application of language models, our series of experiments and the metrics we designed reveal that code-based Large Language Models (LLMs) significantly outperform models trained on data that is closely matched to the tasks in non-coding Chinese tasks. Moreover, in tasks high sensitivity to Chinese hallucinations, models exhibiting fewer linguistic features of the Chinese language achieve better performance. Our experimental results can be easily replicated in Chinese data processing tasks, such as preparing data for Retrieval-Augmented Generation (RAG), by simply replacing the base model with a code-based model. Additionally, our research offers a distinct perspective for discussion on the philosophical "Chinese Room" thought experiment.
CodeFuse-13B: A Pretrained Multi-lingual Code Large Language Model
Oct 10, 2023Code Large Language Models (Code LLMs) have gained significant attention in the industry due to their wide applications in the full lifecycle of software engineering. However, the effectiveness of existing models in understanding non-English inputs for multi-lingual code-related tasks is still far from well studied. This paper introduces CodeFuse-13B, an open-sourced pre-trained code LLM. It is specifically designed for code-related tasks with both English and Chinese prompts and supports over 40 programming languages. CodeFuse achieves its effectiveness by utilizing a high quality pre-training dataset that is carefully filtered by program analyzers and optimized during the training process. Extensive experiments are conducted using real-world usage scenarios, the industry-standard benchmark HumanEval-x, and the specially designed CodeFuseEval for Chinese prompts. To assess the effectiveness of CodeFuse, we actively collected valuable human feedback from the AntGroup's software development process where CodeFuse has been successfully deployed. The results demonstrate that CodeFuse-13B achieves a HumanEval pass@1 score of 37.10%, positioning it as one of the top multi-lingual code LLMs with similar parameter sizes. In practical scenarios, such as code generation, code translation, code comments, and testcase generation, CodeFuse performs better than other models when confronted with Chinese prompts.
Capturing dynamical correlations using implicit neural representations
Apr 08, 2023The observation and description of collective excitations in solids is a fundamental issue when seeking to understand the physics of a many-body system. Analysis of these excitations is usually carried out by measuring the dynamical structure factor, S(Q, $\omega$), with inelastic neutron or x-ray scattering techniques and comparing this against a calculated dynamical model. Here, we develop an artificial intelligence framework which combines a neural network trained to mimic simulated data from a model Hamiltonian with automatic differentiation to recover unknown parameters from experimental data. We benchmark this approach on a Linear Spin Wave Theory (LSWT) simulator and advanced inelastic neutron scattering data from the square-lattice spin-1 antiferromagnet La$_2$NiO$_4$. We find that the model predicts the unknown parameters with excellent agreement relative to analytical fitting. In doing so, we illustrate the ability to build and train a differentiable model only once, which then can be applied in real-time to multi-dimensional scattering data, without the need for human-guided peak finding and fitting algorithms. This prototypical approach promises a new technology for this field to automatically detect and refine more advanced models for ordered quantum systems.
Sophisticated deep learning with on-chip optical diffractive tensor processing
Dec 20, 2022



The ever-growing deep learning technologies are making revolutionary changes for modern life. However, conventional computing architectures are designed to process sequential and digital programs, being extremely burdened with performing massive parallel and adaptive deep learning applications. Photonic integrated circuits provide an efficient approach to mitigate bandwidth limitations and power-wall brought by its electronic counterparts, showing great potential in ultrafast and energy-free high-performance computing. Here, we propose an optical computing architecture enabled by on-chip diffraction to implement convolutional acceleration, termed optical convolution unit (OCU). We demonstrate that any real-valued convolution kernels can be exploited by OCU with a prominent computational throughput boosting via the concept of structral re-parameterization. With OCU as the fundamental unit, we build an optical convolutional neural network (oCNN) to implement two popular deep learning tasks: classification and regression. For classification, Fashion-MNIST and CIFAR-4 datasets are tested with accuracy of 91.63% and 86.25%, respectively. For regression, we build an optical denoising convolutional neural network (oDnCNN) to handle Gaussian noise in gray scale images with noise level {\sigma} = 10, 15, 20, resulting clean images with average PSNR of 31.70dB, 29.39dB and 27.72dB, respectively. The proposed OCU presents remarkable performance of low energy consumption and high information density due to its fully passive nature and compact footprint, providing a highly parallel while lightweight solution for future computing architecture to handle high dimensional tensors in deep learning.
Passive Non-line-of-sight Imaging for Moving Targets with an Event Camera
Sep 27, 2022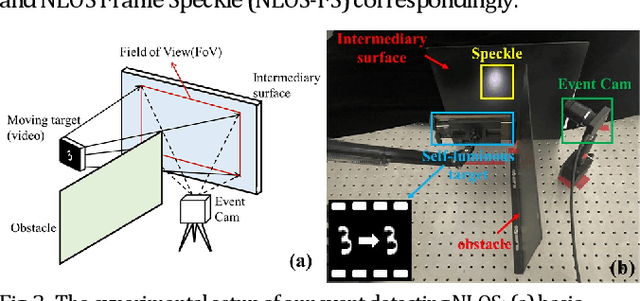



Non-line-of-sight (NLOS) imaging is an emerging technique for detecting objects behind obstacles or around corners. Recent studies on passive NLOS mainly focus on steady-state measurement and reconstruction methods, which show limitations in recognition of moving targets. To the best of our knowledge, we propose a novel event-based passive NLOS imaging method. We acquire asynchronous event-based data which contains detailed dynamic information of the NLOS target, and efficiently ease the degradation of speckle caused by movement. Besides, we create the first event-based NLOS imaging dataset, NLOS-ES, and the event-based feature is extracted by time-surface representation. We compare the reconstructions through event-based data with frame-based data. The event-based method performs well on PSNR and LPIPS, which is 20% and 10% better than frame-based method, while the data volume takes only 2% of traditional method.
Key frames assisted hybrid encoding for photorealistic compressive video sensing
Jul 26, 2022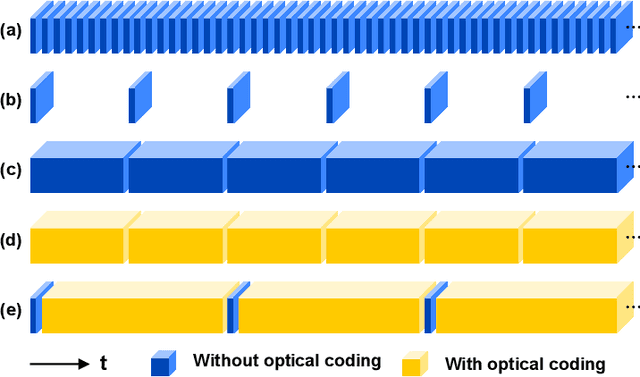
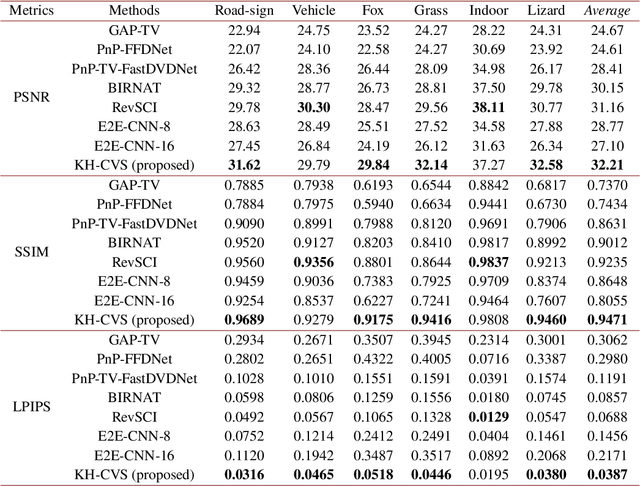
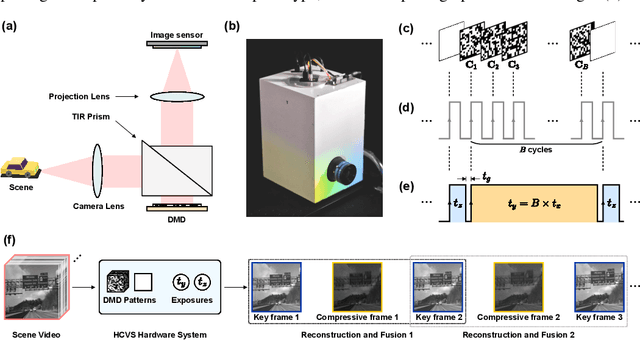
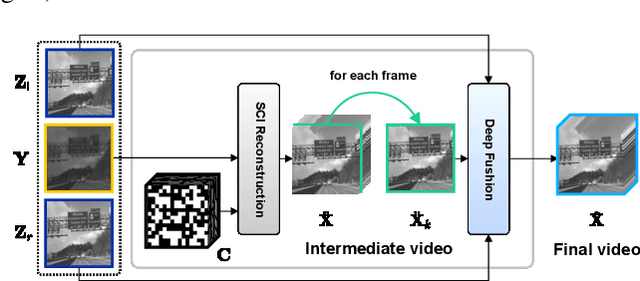
Snapshot compressive imaging (SCI) encodes high-speed scene video into a snapshot measurement and then computationally makes reconstructions, allowing for efficient high-dimensional data acquisition. Numerous algorithms, ranging from regularization-based optimization and deep learning, are being investigated to improve reconstruction quality, but they are still limited by the ill-posed and information-deficient nature of the standard SCI paradigm. To overcome these drawbacks, we propose a new key frames assisted hybrid encoding paradigm for compressive video sensing, termed KH-CVS, that alternatively captures short-exposure key frames without coding and long-exposure encoded compressive frames to jointly reconstruct photorealistic video. With the use of optical flow and spatial warping, a deep convolutional neural network framework is constructed to integrate the benefits of these two types of frames. Extensive experiments on both simulations and real data from the prototype we developed verify the superiority of the proposed method.