 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Wittgensteinian Representation Hypothesis: Is Language the Attractor of Multimodal Convergence?
May 10, 2026Understanding why independently trained neural networks from different modalities converge toward shared representations, and where this convergence leads, remains an open question in representation learning. All existing evidence relies on symmetric similarity measures, which can detect convergence but are structurally blind to its direction. We introduce directional convergence analysis using cycle-kNN, an asymmetric alignment measure, applied across dozens of independently trained unimodal models spanning point clouds, vision, and language. We uncover a consistent directional asymmetry: non-language modalities move toward the neighborhood structure of language significantly more than the reverse, and this pattern holds across all model families and scales--yet is entirely invisible to symmetric measures. Mechanistic analysis traces the directionality to feature density asymmetry, whereby language representations occupy the most compact regions of representational space. The Information Bottleneck framework provides a principled interpretation: optimization under compression drives representations toward discrete, compositional structures characteristic of language. We formalize this as the Wittgensteinian Representation Hypothesis: the semantic structure of language is the asymptotic attractor of multimodal representation convergence.
M$^2$-Miner: Multi-Agent Enhanced MCTS for Mobile GUI Agent Data Mining
Feb 05, 2026Graphical User Interface (GUI) agent is pivotal to advancing intelligent human-computer interaction paradigms. Constructing powerful GUI agents necessitates the large-scale annotation of high-quality user-behavior trajectory data (i.e., intent-trajectory pairs) for training. However, manual annotation methods and current GUI agent data mining approaches typically face three critical challenges: high construction cost, poor data quality, and low data richness. To address these issues, we propose M$^2$-Miner, the first low-cost and automated mobile GUI agent data-mining framework based on Monte Carlo Tree Search (MCTS). For better data mining efficiency and quality, we present a collaborative multi-agent framework, comprising InferAgent, OrchestraAgent, and JudgeAgent for guidance, acceleration, and evaluation. To further enhance the efficiency of mining and enrich intent diversity, we design an intent recycling strategy to extract extra valuable interaction trajectories. Additionally, a progressive model-in-the-loop training strategy is introduced to improve the success rate of data mining. Extensive experiments have demonstrated that the GUI agent fine-tuned using our mined data achieves state-of-the-art performance on several commonly used mobile GUI benchmarks. Our work will be released to facilitate the community research.
SparkUI-Parser: Enhancing GUI Perception with Robust Grounding and Parsing
Sep 05, 2025The existing Multimodal Large Language Models (MLLMs) for GUI perception have made great progress. However, the following challenges still exist in prior methods: 1) They model discrete coordinates based on text autoregressive mechanism, which results in lower grounding accuracy and slower inference speed. 2) They can only locate predefined sets of elements and are not capable of parsing the entire interface, which hampers the broad application and support for downstream tasks. To address the above issues, we propose SparkUI-Parser, a novel end-to-end framework where higher localization precision and fine-grained parsing capability of the entire interface are simultaneously achieved. Specifically, instead of using probability-based discrete modeling, we perform continuous modeling of coordinates based on a pre-trained Multimodal Large Language Model (MLLM) with an additional token router and coordinate decoder. This effectively mitigates the limitations inherent in the discrete output characteristics and the token-by-token generation process of MLLMs, consequently boosting both the accuracy and the inference speed. To further enhance robustness, a rejection mechanism based on a modified Hungarian matching algorithm is introduced, which empowers the model to identify and reject non-existent elements, thereby reducing false positives. Moreover, we present ScreenParse, a rigorously constructed benchmark to systematically assess structural perception capabilities of GUI models across diverse scenarios. Extensive experiments demonstrate that our approach consistently outperforms SOTA methods on ScreenSpot, ScreenSpot-v2, CAGUI-Grounding and ScreenParse benchmarks. The resources are available at https://github.com/antgroup/SparkUI-Parser.
Efficient Video Face Enhancement with Enhanced Spatial-Temporal Consistency
Nov 25, 2024



As a very common type of video, face videos often appear in movies, talk shows, live broadcasts, and other scenes. Real-world online videos are often plagued by degradations such as blurring and quantization noise, due to the high compression ratio caused by high communication costs and limited transmission bandwidth. These degradations have a particularly serious impact on face videos because the human visual system is highly sensitive to facial details. Despite the significant advancement in video face enhancement, current methods still suffer from $i)$ long processing time and $ii)$ inconsistent spatial-temporal visual effects (e.g., flickering). This study proposes a novel and efficient blind video face enhancement method to overcome the above two challenges, restoring high-quality videos from their compressed low-quality versions with an effective de-flickering mechanism. In particular, the proposed method develops upon a 3D-VQGAN backbone associated with spatial-temporal codebooks recording high-quality portrait features and residual-based temporal information. We develop a two-stage learning framework for the model. In Stage \Rmnum{1}, we learn the model with a regularizer mitigating the codebook collapse problem. In Stage \Rmnum{2}, we learn two transformers to lookup code from the codebooks and further update the encoder of low-quality videos. Experiments conducted on the VFHQ-Test dataset demonstrate that our method surpasses the current state-of-the-art blind face video restoration and de-flickering methods on both efficiency and effectiveness. Code is available at \url{https://github.com/Dixin-Lab/BFVR-STC}.
MVBIND: Self-Supervised Music Recommendation For Videos Via Embedding Space Binding
May 15, 2024



Recent years have witnessed the rapid development of short videos, which usually contain both visual and audio modalities. Background music is important to the short videos, which can significantly influence the emotions of the viewers. However, at present, the background music of short videos is generally chosen by the video producer, and there is a lack of automatic music recommendation methods for short videos. This paper introduces MVBind, an innovative Music-Video embedding space Binding model for cross-modal retrieval. MVBind operates as a self-supervised approach, acquiring inherent knowledge of intermodal relationships directly from data, without the need of manual annotations. Additionally, to compensate the lack of a corresponding musical-visual pair dataset for short videos, we construct a dataset, SVM-10K(Short Video with Music-10K), which mainly consists of meticulously selected short videos. On this dataset, MVBind manifests significantly improved performance compared to other baseline methods. The constructed dataset and code will be released to facilitate future research.
Key frames assisted hybrid encoding for photorealistic compressive video sensing
Jul 26, 2022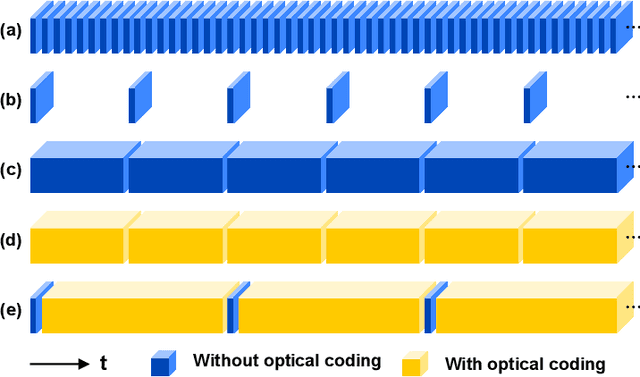
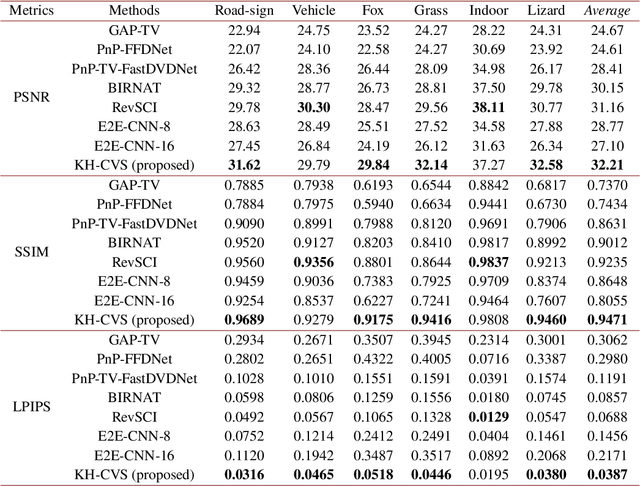
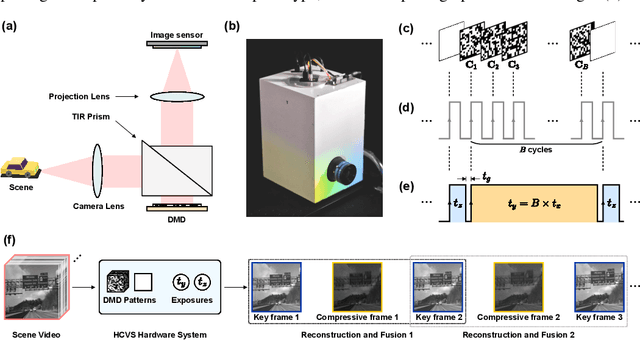
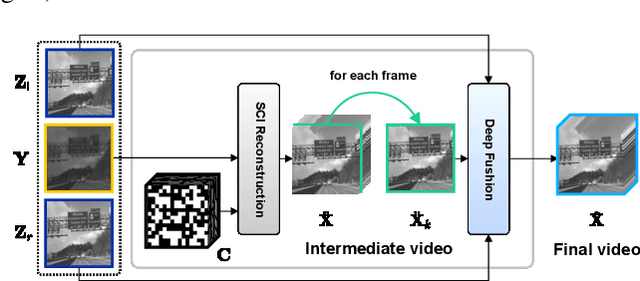
Snapshot compressive imaging (SCI) encodes high-speed scene video into a snapshot measurement and then computationally makes reconstructions, allowing for efficient high-dimensional data acquisition. Numerous algorithms, ranging from regularization-based optimization and deep learning, are being investigated to improve reconstruction quality, but they are still limited by the ill-posed and information-deficient nature of the standard SCI paradigm. To overcome these drawbacks, we propose a new key frames assisted hybrid encoding paradigm for compressive video sensing, termed KH-CVS, that alternatively captures short-exposure key frames without coding and long-exposure encoded compressive frames to jointly reconstruct photorealistic video. With the use of optical flow and spatial warping, a deep convolutional neural network framework is constructed to integrate the benefits of these two types of frames. Extensive experiments on both simulations and real data from the prototype we developed verify the superiority of the proposed method.