 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamVoice: Text-Guided Voice Conversion
Jun 24, 2024


Generative voice technologies are rapidly evolving, offering opportunities for more personalized and inclusive experiences. Traditional one-shot voice conversion (VC) requires a target recording during inference, limiting ease of usage in generating desired voice timbres. Text-guided generation offers an intuitive solution to convert voices to desired "DreamVoices" according to the users' needs. Our paper presents two major contributions to VC technology: (1) DreamVoiceDB, a robust dataset of voice timbre annotations for 900 speakers from VCTK and LibriTTS. (2) Two text-guided VC methods: DreamVC, an end-to-end diffusion-based text-guided VC model; and DreamVG, a versatile text-to-voice generation plugin that can be combined with any one-shot VC models. The experimental results demonstrate that our proposed methods trained on the DreamVoiceDB dataset generate voice timbres accurately aligned with the text prompt and achieve high-quality VC.
Noise-robust Speech Separation with Fast Generative Correction
Jun 11, 2024Speech separation, the task of isolating multiple speech sources from a mixed audio signal, remains challenging in noisy environments. In this paper, we propose a generative correction method to enhance the output of a discriminative separator. By leveraging a generative corrector based on a diffusion model, we refine the separation process for single-channel mixture speech by removing noises and perceptually unnatural distortions. Furthermore, we optimize the generative model using a predictive loss to streamline the diffusion model's reverse process into a single step and rectify any associated errors by the reverse process. Our method achieves state-of-the-art performance on the in-domain Libri2Mix noisy dataset, and out-of-domain WSJ with a variety of noises, improving SI-SNR by 22-35% relative to SepFormer, demonstrating robustness and strong generalization capabilities.
Enhancing Zero-shot Text-to-Speech Synthesis with Human Feedback
Jun 02, 2024In recent years, text-to-speech (TTS) technology has witnessed impressive advancements, particularly with large-scale training datasets, showcasing human-level speech quality and impressive zero-shot capabilities on unseen speakers. However, despite human subjective evaluations, such as the mean opinion score (MOS), remaining the gold standard for assessing the quality of synthetic speech, even state-of-the-art TTS approaches have kept human feedback isolated from training that resulted in mismatched training objectives and evaluation metrics. In this work, we investigate a novel topic of integrating subjective human evaluation into the TTS training loop. Inspired by the recent success of reinforcement learning from human feedback, we propose a comprehensive sampling-annotating-learning framework tailored to TTS optimization, namely uncertainty-aware optimization (UNO). Specifically, UNO eliminates the need for a reward model or preference data by directly maximizing the utility of speech generations while considering the uncertainty that lies in the inherent variability in subjective human speech perception and evaluations. Experimental results of both subjective and objective evaluations demonstrate that UNO considerably improves the zero-shot performance of TTS models in terms of MOS, word error rate, and speaker similarity. Additionally, we present a remarkable ability of UNO that it can adapt to the desired speaking style in emotional TTS seamlessly and flexibly.
Asynchronous and Segmented Bidirectional Encoding for NMT
Feb 19, 2024With the rapid advancement of Neural Machine Translation (NMT), enhancing translation efficiency and quality has become a focal point of research. Despite the commendable performance of general models such as the Transformer in various aspects, they still fall short in processing long sentences and fully leveraging bidirectional contextual information. This paper introduces an improved model based on the Transformer, implementing an asynchronous and segmented bidirectional decoding strategy aimed at elevating translation efficiency and accuracy. Compared to traditional unidirectional translations from left-to-right or right-to-left, our method demonstrates heightened efficiency and improved translation quality, particularly in handling long sentences. Experimental results on the IWSLT2017 dataset confirm the effectiveness of our approach in accelerating translation and increasing accuracy, especially surpassing traditional unidirectional strategies in long sentence translation. Furthermore, this study analyzes the impact of sentence length on decoding outcomes and explores the model's performance in various scenarios. The findings of this research not only provide an effective encoding strategy for the NMT field but also pave new avenues and directions for future studies.
Efficient Reinforcemen Learning via Decoupling Exploration and Utilization
Jan 17, 2024Deep neural network(DNN) generalization is limited by the over-reliance of current offline reinforcement learning techniques on conservative processing of existing datasets. This method frequently results in algorithms that settle for suboptimal solutions that only adjust to a certain dataset. Similarly, in online reinforcement learning, the previously imposed punitive pessimism also deprives the model of its exploratory potential. Our research proposes a novel framework, Optimistic and Pessimistic Actor Reinforcement Learning (OPARL). OPARL employs a unique dual-actor approach: an optimistic actor dedicated to exploration and a pessimistic actor focused on utilization, thereby effectively differentiating between exploration and utilization strategies. This unique combination in reinforcement learning methods fosters a more balanced and efficient approach. It enables the optimization of policies that focus on actions yielding high rewards through pessimistic utilization strategies, while also ensuring extensive state coverage via optimistic exploration. Experiments and theoretical study demonstrates OPARL improves agents' capacities for application and exploration. In the most tasks of DMControl benchmark and Mujoco environment, OPARL performed better than state-of-the-art methods. Our code has released on https://github.com/yydsok/OPARL
Improving fairness for spoken language understanding in atypical speech with Text-to-Speech
Nov 16, 2023



Spoken language understanding (SLU) systems often exhibit suboptimal performance in processing atypical speech, typically caused by neurological conditions and motor impairments. Recent advancements in Text-to-Speech (TTS) synthesis-based augmentation for more fair SLU have struggled to accurately capture the unique vocal characteristics of atypical speakers, largely due to insufficient data. To address this issue, we present a novel data augmentation method for atypical speakers by finetuning a TTS model, called Aty-TTS. Aty-TTS models speaker and atypical characteristics via knowledge transferring from a voice conversion model. Then, we use the augmented data to train SLU models adapted to atypical speech. To train these data augmentation models and evaluate the resulting SLU systems, we have collected a new atypical speech dataset containing intent annotation. Both objective and subjective assessments validate that Aty-TTS is capable of generating high-quality atypical speech. Furthermore, it serves as an effective data augmentation strategy, contributing to more fair SLU systems that can better accommodate individuals with atypical speech patterns.
DPM-TSE: A Diffusion Probabilistic Model for Target Sound Extraction
Oct 10, 2023


Common target sound extraction (TSE) approaches primarily relied on discriminative approaches in order to separate the target sound while minimizing interference from the unwanted sources, with varying success in separating the target from the background. This study introduces DPM-TSE, a first generative method based on diffusion probabilistic modeling (DPM) for target sound extraction, to achieve both cleaner target renderings as well as improved separability from unwanted sounds. The technique also tackles common background noise issues with DPM by introducing a correction method for noise schedules and sample steps. This approach is evaluated using both objective and subjective quality metrics on the FSD Kaggle 2018 dataset. The results show that DPM-TSE has a significant improvement in perceived quality in terms of target extraction and purity.
DuTa-VC: A Duration-aware Typical-to-atypical Voice Conversion Approach with Diffusion Probabilistic Model
Jun 18, 2023



We present a novel typical-to-atypical voice conversion approach (DuTa-VC), which (i) can be trained with nonparallel data (ii) first introduces diffusion probabilistic model (iii) preserves the target speaker identity (iv) is aware of the phoneme duration of the target speaker. DuTa-VC consists of three parts: an encoder transforms the source mel-spectrogram into a duration-modified speaker-independent mel-spectrogram, a decoder performs the reverse diffusion to generate the target mel-spectrogram, and a vocoder is applied to reconstruct the waveform. Objective evaluations conducted on the UASpeech show that DuTa-VC is able to capture severity characteristics of dysarthric speech, reserves speaker identity, and significantly improves dysarthric speech recognition as a data augmentation. Subjective evaluations by two expert speech pathologists validate that DuTa-VC can preserve the severity and type of dysarthria of the target speakers in the synthesized speech.
Benchmarking Large Language Models on CMExam -- A Comprehensive Chinese Medical Exam Dataset
Jun 08, 2023



Recent advancements in large language models (LLMs) have transformed the field of question answering (QA). However, evaluating LLMs in the medical field is challenging due to the lack of standardized and comprehensive datasets. To address this gap, we introduce CMExam, sourced from the Chinese National Medical Licensing Examination. CMExam consists of 60K+ multiple-choice questions for standardized and objective evaluations, as well as solution explanations for model reasoning evaluation in an open-ended manner. For in-depth analyses of LLMs, we invited medical professionals to label five additional question-wise annotations, including disease groups, clinical departments, medical disciplines, areas of competency, and question difficulty levels. Alongside the dataset, we further conducted thorough experiments with representative LLMs and QA algorithms on CMExam. The results show that GPT-4 had the best accuracy of 61.6% and a weighted F1 score of 0.617. These results highlight a great disparity when compared to human accuracy, which stood at 71.6%. For explanation tasks, while LLMs could generate relevant reasoning and demonstrate improved performance after finetuning, they fall short of a desired standard, indicating ample room for improvement. To the best of our knowledge, CMExam is the first Chinese medical exam dataset to provide comprehensive medical annotations. The experiments and findings of LLM evaluation also provide valuable insights into the challenges and potential solutions in developing Chinese medical QA systems and LLM evaluation pipelines. The dataset and relevant code are available at https://github.com/williamliujl/CMExam.
NoreSpeech: Knowledge Distillation based Conditional Diffusion Model for Noise-robust Expressive TTS
Nov 04, 2022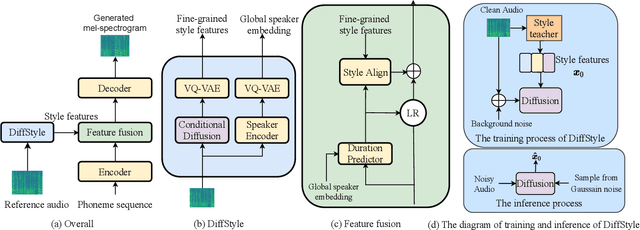
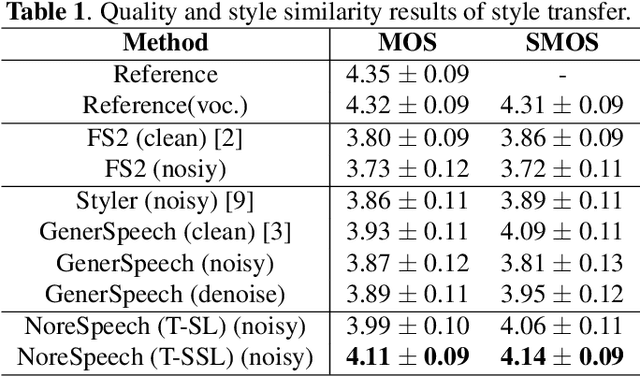

Expressive text-to-speech (TTS) can synthesize a new speaking style by imiating prosody and timbre from a reference audio, which faces the following challenges: (1) The highly dynamic prosody information in the reference audio is difficult to extract, especially, when the reference audio contains background noise. (2) The TTS systems should have good generalization for unseen speaking styles. In this paper, we present a \textbf{no}ise-\textbf{r}obust \textbf{e}xpressive TTS model (NoreSpeech), which can robustly transfer speaking style in a noisy reference utterance to synthesized speech. Specifically, our NoreSpeech includes several components: (1) a novel DiffStyle module, which leverages powerful probabilistic denoising diffusion models to learn noise-agnostic speaking style features from a teacher model by knowledge distillation; (2) a VQ-VAE block, which maps the style features into a controllable quantized latent space for improving the generalization of style transfer; and (3) a straight-forward but effective parameter-free text-style alignment module, which enables NoreSpeech to transfer style to a textual input from a length-mismatched reference utterance. Experiments demonstrate that NoreSpeech is more effective than previous expressive TTS models in noise environments. Audio samples and code are available at: \href{http://dongchaoyang.top/NoreSpeech\_demo/}{http://dongchaoyang.top/NoreSpeech\_demo/}