 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAT-SAM: Conditional Tuning Network for Few-Shot Adaptation of Segmentation Anything Model
Feb 06, 2024



The recent Segment Anything Model (SAM) has demonstrated remarkable zero-shot capability and flexible geometric prompting in general image segmentation. However, SAM often struggles when handling various unconventional images, such as aerial, medical, and non-RGB images. This paper presents CAT-SAM, a ConditionAl Tuning network that adapts SAM toward various unconventional target tasks with just few-shot target samples. CAT-SAM freezes the entire SAM and adapts its mask decoder and image encoder simultaneously with a small number of learnable parameters. The core design is a prompt bridge structure that enables decoder-conditioned joint tuning of the heavyweight image encoder and the lightweight mask decoder. The bridging maps the prompt token of the mask decoder to the image encoder, fostering synergic adaptation of the encoder and the decoder with mutual benefits. We develop two representative tuning strategies for the image encoder which leads to two CAT-SAM variants: one injecting learnable prompt tokens in the input space and the other inserting lightweight adapter networks. Extensive experiments over 11 unconventional tasks show that both CAT-SAM variants achieve superior target segmentation performance consistently even under the very challenging one-shot adaptation setup. Project page: \url{https://xiaoaoran.github.io/projects/CAT-SAM}
Estimating 3D Uncertainty Field: Quantifying Uncertainty for Neural Radiance Fields
Nov 03, 2023Current methods based on Neural Radiance Fields (NeRF) significantly lack the capacity to quantify uncertainty in their predictions, particularly on the unseen space including the occluded and outside scene content. This limitation hinders their extensive applications in robotics, where the reliability of model predictions has to be considered for tasks such as robotic exploration and planning in unknown environments. To address this, we propose a novel approach to estimate a 3D Uncertainty Field based on the learned incomplete scene geometry, which explicitly identifies these unseen regions. By considering the accumulated transmittance along each camera ray, our Uncertainty Field infers 2D pixel-wise uncertainty, exhibiting high values for rays directly casting towards occluded or outside the scene content. To quantify the uncertainty on the learned surface, we model a stochastic radiance field. Our experiments demonstrate that our approach is the only one that can explicitly reason about high uncertainty both on 3D unseen regions and its involved 2D rendered pixels, compared with recent methods. Furthermore, we illustrate that our designed uncertainty field is ideally suited for real-world robotics tasks, such as next-best-view selection.
3D Semantic Segmentation in the Wild: Learning Generalized Models for Adverse-Condition Point Clouds
Apr 03, 2023



Robust point cloud parsing under all-weather conditions is crucial to level-5 autonomy in autonomous driving. However, how to learn a universal 3D semantic segmentation (3DSS) model is largely neglected as most existing benchmarks are dominated by point clouds captured under normal weather. We introduce SemanticSTF, an adverse-weather point cloud dataset that provides dense point-level annotations and allows to study 3DSS under various adverse weather conditions. We study all-weather 3DSS modeling under two setups: 1) domain adaptive 3DSS that adapts from normal-weather data to adverse-weather data; 2) domain generalizable 3DSS that learns all-weather 3DSS models from normal-weather data. Our studies reveal the challenge while existing 3DSS methods encounter adverse-weather data, showing the great value of SemanticSTF in steering the future endeavor along this very meaningful research direction. In addition, we design a domain randomization technique that alternatively randomizes the geometry styles of point clouds and aggregates their embeddings, ultimately leading to a generalizable model that can improve 3DSS under various adverse weather effectively. The SemanticSTF and related codes are available at \url{https://github.com/xiaoaoran/SemanticSTF}.
Grasp-Oriented Fine-grained Cloth Segmentation without Real Supervision
Oct 06, 2021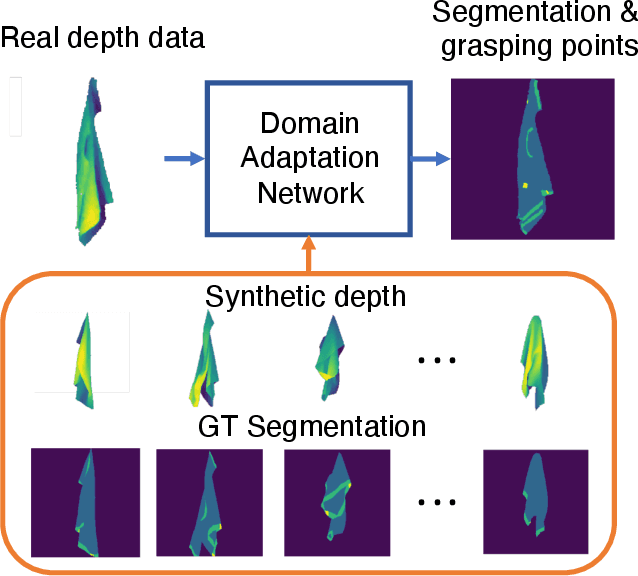
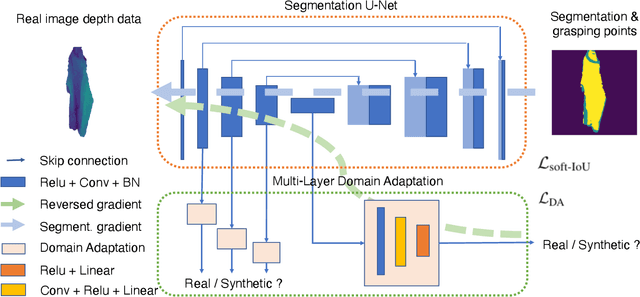

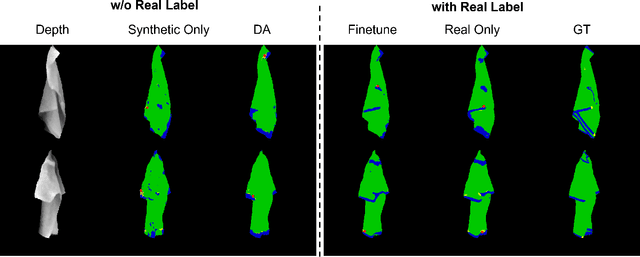
Automatically detecting graspable regions from a single depth image is a key ingredient in cloth manipulation. The large variability of cloth deformations has motivated most of the current approaches to focus on identifying specific grasping points rather than semantic parts, as the appearance and depth variations of local regions are smaller and easier to model than the larger ones. However, tasks like cloth folding or assisted dressing require recognising larger segments, such as semantic edges that carry more information than points. The first goal of this paper is therefore to tackle the problem of fine-grained region detection in deformed clothes using only a depth image. As a proof of concept, we implement an approach for T-shirts, and define up to 6 semantic regions of varying extent, including edges on the neckline, sleeve cuffs, and hem, plus top and bottom grasping points. We introduce a U-net based network to segment and label these parts. The second contribution of our work is concerned with the level of supervision that we require to train the proposed network. While most approaches learn to detect grasping points by combining real and synthetic annotations, in this work we defy the limitations of the synthetic data, and propose a multilayered domain adaptation (DA) strategy that does not use real annotations at all. We thoroughly evaluate our approach on real depth images of a T-shirt annotated with fine-grained labels. We show that training our network solely with synthetic data and the proposed DA yields results competitive with models trained on real data.
Multi-agent Interactive Prediction under Challenging Driving Scenarios
Sep 24, 2019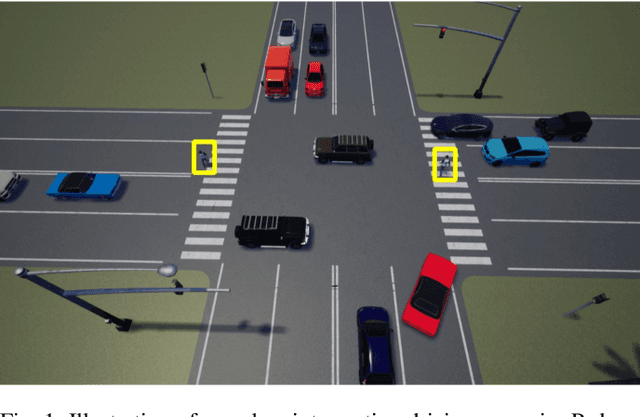
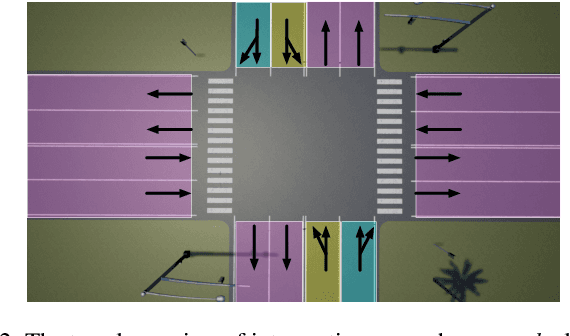
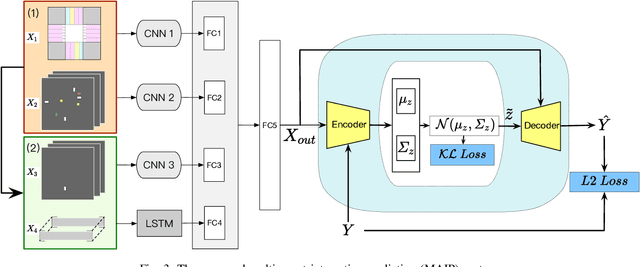
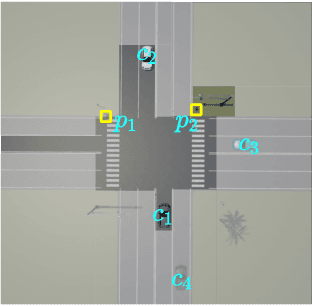
In order to drive safely on the road, autonomous vehicle is expected to predict future outcomes of its surrounding environment and react properly. In fact, many researchers have been focused on solving behavioral prediction problems for autonomous vehicles. However, very few of them consider multi-agent prediction under challenging driving scenarios such as urban environment. In this paper, we proposed a prediction method that is able to predict various complicated driving scenarios where heterogeneous road entities, signal lights, and static map information are taken into account. Moreover, the proposed multi-agent interactive prediction (MAIP) system is capable of simultaneously predicting any number of road entities while considering their mutual interactions. A case study of a simulated challenging urban intersection scenario is provided to demonstrate the performance and capability of the proposed prediction system.