 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAViL: Masked Audio-Video Learners
Dec 15, 2022



We present Masked Audio-Video Learners (MAViL) to train audio-visual representations. Our approach learns with three complementary forms of self-supervision: (1) reconstruction of masked audio and video input data, (2) intra- and inter-modal contrastive learning with masking, and (3) self-training by reconstructing joint audio-video contextualized features learned from the first two objectives. Pre-training with MAViL not only enables the model to perform well in audio-visual classification and retrieval tasks but also improves representations of each modality in isolation, without using information from the other modality for fine-tuning or inference. Empirically, MAViL sets a new state-of-the-art on AudioSet (53.1 mAP) and VGGSound (67.1% accuracy). For the first time, a self-supervised audio-visual model outperforms ones that use external supervision on these benchmarks. Code will be available soon.
Scaling Language-Image Pre-training via Masking
Dec 01, 2022



We present Fast Language-Image Pre-training (FLIP), a simple and more efficient method for training CLIP. Our method randomly masks out and removes a large portion of image patches during training. Masking allows us to learn from more image-text pairs given the same wall-clock time and contrast more samples per iteration with similar memory footprint. It leads to a favorable trade-off between accuracy and training time. In our experiments on 400 million image-text pairs, FLIP improves both accuracy and speed over the no-masking baseline. On a large diversity of downstream tasks, FLIP dominantly outperforms the CLIP counterparts trained on the same data. Facilitated by the speedup, we explore the scaling behavior of increasing the model size, data size, or training length, and report encouraging results and comparisons. We hope that our work will foster future research on scaling vision-language learning.
Castling-ViT: Compressing Self-Attention via Switching Towards Linear-Angular Attention During Vision Transformer Inference
Nov 18, 2022



Vision Transformers (ViTs) have shown impressive performance but still require a high computation cost as compared to convolutional neural networks (CNNs), due to the global similarity measurements and thus a quadratic complexity with the input tokens. Existing efficient ViTs adopt local attention (e.g., Swin) or linear attention (e.g., Performer), which sacrifice ViTs' capabilities of capturing either global or local context. In this work, we ask an important research question: Can ViTs learn both global and local context while being more efficient during inference? To this end, we propose a framework called Castling-ViT, which trains ViTs using both linear-angular attention and masked softmax-based quadratic attention, but then switches to having only linear angular attention during ViT inference. Our Castling-ViT leverages angular kernels to measure the similarities between queries and keys via spectral angles. And we further simplify it with two techniques: (1) a novel linear-angular attention mechanism: we decompose the angular kernels into linear terms and high-order residuals, and only keep the linear terms; and (2) we adopt two parameterized modules to approximate high-order residuals: a depthwise convolution and an auxiliary masked softmax attention to help learn both global and local information, where the masks for softmax attention are regularized to gradually become zeros and thus incur no overhead during ViT inference. Extensive experiments and ablation studies on three tasks consistently validate the effectiveness of the proposed Castling-ViT, e.g., achieving up to a 1.8% higher accuracy or 40% MACs reduction on ImageNet classification and 1.2 higher mAP on COCO detection under comparable FLOPs, as compared to ViTs with vanilla softmax-based attentions.
Masked Autoencoders As Spatiotemporal Learners
May 18, 2022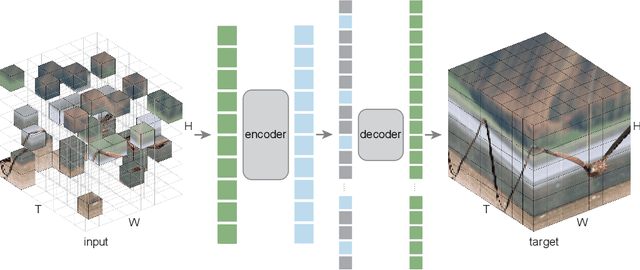



This paper studies a conceptually simple extension of Masked Autoencoders (MAE) to spatiotemporal representation learning from videos. We randomly mask out spacetime patches in videos and learn an autoencoder to reconstruct them in pixels. Interestingly, we show that our MAE method can learn strong representations with almost no inductive bias on spacetime (only except for patch and positional embeddings), and spacetime-agnostic random masking performs the best. We observe that the optimal masking ratio is as high as 90% (vs. 75% on images), supporting the hypothesis that this ratio is related to information redundancy of the data. A high masking ratio leads to a large speedup, e.g., > 4x in wall-clock time or even more. We report competitive results on several challenging video datasets using vanilla Vision Transformers. We observe that MAE can outperform supervised pre-training by large margins. We further report encouraging results of training on real-world, uncurated Instagram data. Our study suggests that the general framework of masked autoencoding (BERT, MAE, etc.) can be a unified methodology for representation learning with minimal domain knowledge.
On the Importance of Asymmetry for Siamese Representation Learning
Apr 01, 2022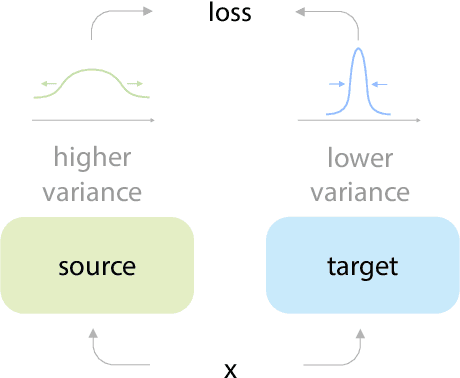

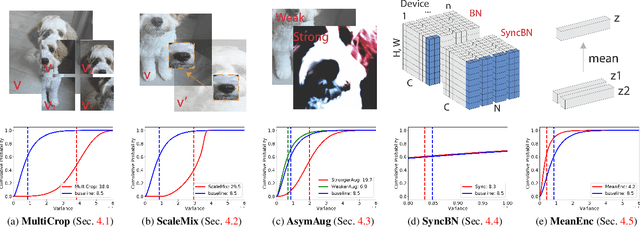
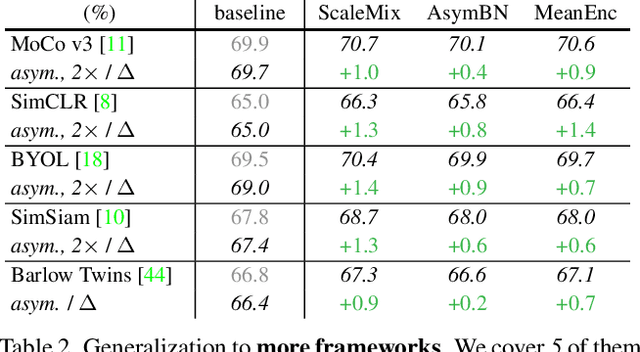
Many recent self-supervised frameworks for visual representation learning are based on certain forms of Siamese networks. Such networks are conceptually symmetric with two parallel encoders, but often practically asymmetric as numerous mechanisms are devised to break the symmetry. In this work, we conduct a formal study on the importance of asymmetry by explicitly distinguishing the two encoders within the network -- one produces source encodings and the other targets. Our key insight is keeping a relatively lower variance in target than source generally benefits learning. This is empirically justified by our results from five case studies covering different variance-oriented designs, and is aligned with our preliminary theoretical analysis on the baseline. Moreover, we find the improvements from asymmetric designs generalize well to longer training schedules, multiple other frameworks and newer backbones. Finally, the combined effect of several asymmetric designs achieves a state-of-the-art accuracy on ImageNet linear probing and competitive results on downstream transfer. We hope our exploration will inspire more research in exploiting asymmetry for Siamese representation learning.
Unified Transformer Tracker for Object Tracking
Mar 29, 2022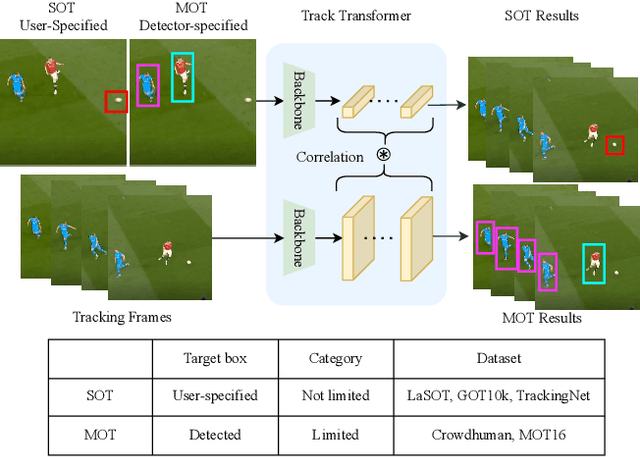
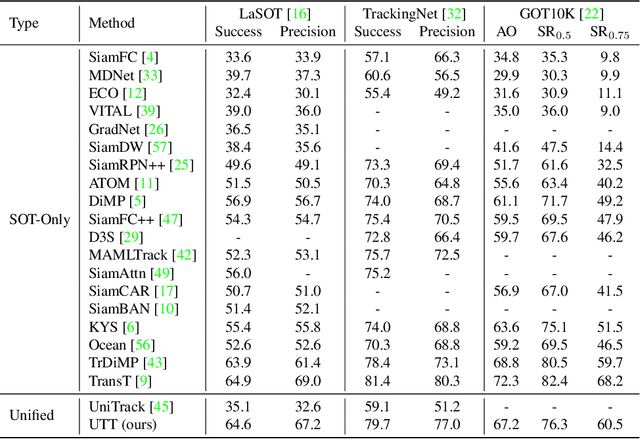
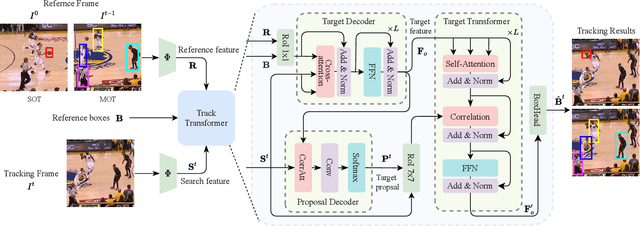
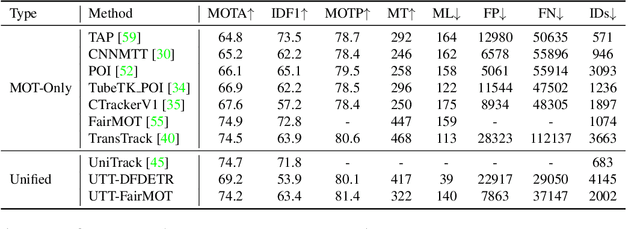
As an important area in computer vision, object tracking has formed two separate communities that respectively study Single Object Tracking (SOT) and Multiple Object Tracking (MOT). However, current methods in one tracking scenario are not easily adapted to the other due to the divergent training datasets and tracking objects of both tasks. Although UniTrack \cite{wang2021different} demonstrates that a shared appearance model with multiple heads can be used to tackle individual tracking tasks, it fails to exploit the large-scale tracking datasets for training and performs poorly on single object tracking. In this work, we present the Unified Transformer Tracker (UTT) to address tracking problems in different scenarios with one paradigm. A track transformer is developed in our UTT to track the target in both SOT and MOT. The correlation between the target and tracking frame features is exploited to localize the target. We demonstrate that both SOT and MOT tasks can be solved within this framework. The model can be simultaneously end-to-end trained by alternatively optimizing the SOT and MOT objectives on the datasets of individual tasks. Extensive experiments are conducted on several benchmarks with a unified model trained on SOT and MOT datasets. Code will be available at https://github.com/Flowerfan/Trackron.
MeMViT: Memory-Augmented Multiscale Vision Transformer for Efficient Long-Term Video Recognition
Jan 20, 2022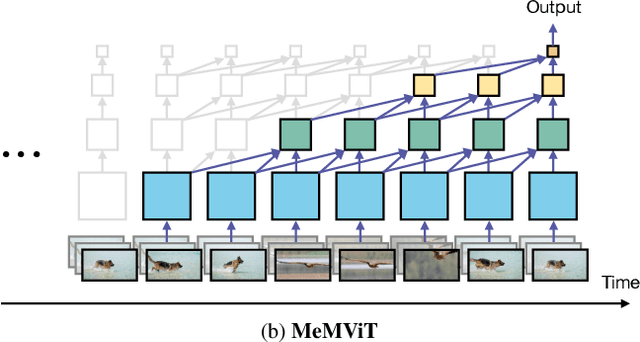

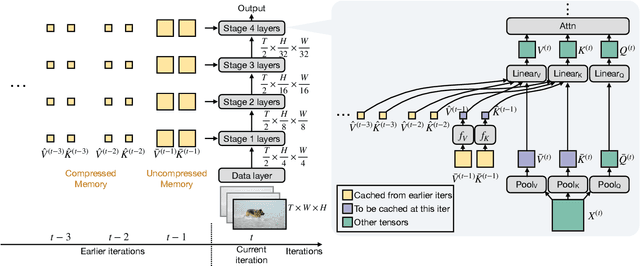

While today's video recognition systems parse snapshots or short clips accurately, they cannot connect the dots and reason across a longer range of time yet. Most existing video architectures can only process <5 seconds of a video without hitting the computation or memory bottlenecks. In this paper, we propose a new strategy to overcome this challenge. Instead of trying to process more frames at once like most existing methods, we propose to process videos in an online fashion and cache "memory" at each iteration. Through the memory, the model can reference prior context for long-term modeling, with only a marginal cost. Based on this idea, we build MeMViT, a Memory-augmented Multiscale Vision Transformer, that has a temporal support 30x longer than existing models with only 4.5% more compute; traditional methods need >3,000% more compute to do the same. On a wide range of settings, the increased temporal support enabled by MeMViT brings large gains in recognition accuracy consistently. MeMViT obtains state-of-the-art results on the AVA, EPIC-Kitchens-100 action classification, and action anticipation datasets. Code and models will be made publicly available.
Masked Feature Prediction for Self-Supervised Visual Pre-Training
Dec 16, 2021

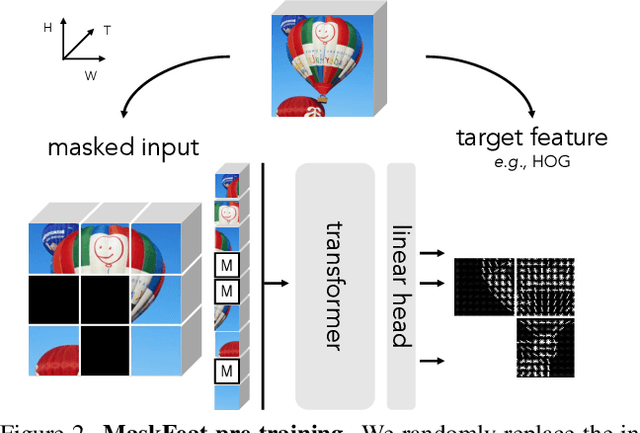
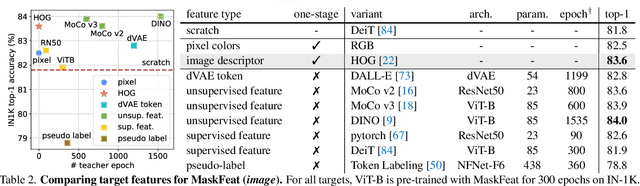
We present Masked Feature Prediction (MaskFeat) for self-supervised pre-training of video models. Our approach first randomly masks out a portion of the input sequence and then predicts the feature of the masked regions. We study five different types of features and find Histograms of Oriented Gradients (HOG), a hand-crafted feature descriptor, works particularly well in terms of both performance and efficiency. We observe that the local contrast normalization in HOG is essential for good results, which is in line with earlier work using HOG for visual recognition. Our approach can learn abundant visual knowledge and drive large-scale Transformer-based models. Without using extra model weights or supervision, MaskFeat pre-trained on unlabeled videos achieves unprecedented results of 86.7% with MViT-L on Kinetics-400, 88.3% on Kinetics-600, 80.4% on Kinetics-700, 38.8 mAP on AVA, and 75.0% on SSv2. MaskFeat further generalizes to image input, which can be interpreted as a video with a single frame and obtains competitive results on ImageNet.
Improved Multiscale Vision Transformers for Classification and Detection
Dec 02, 2021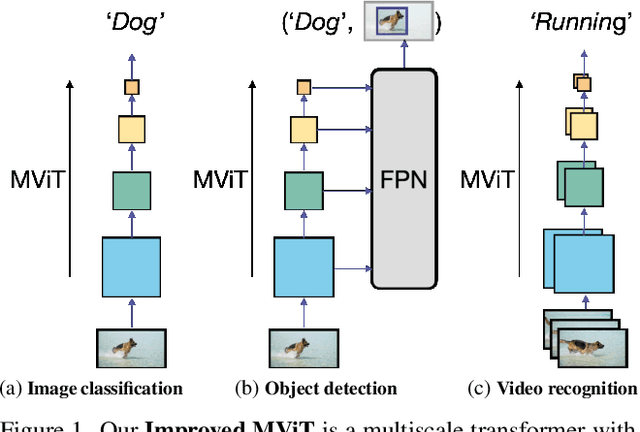
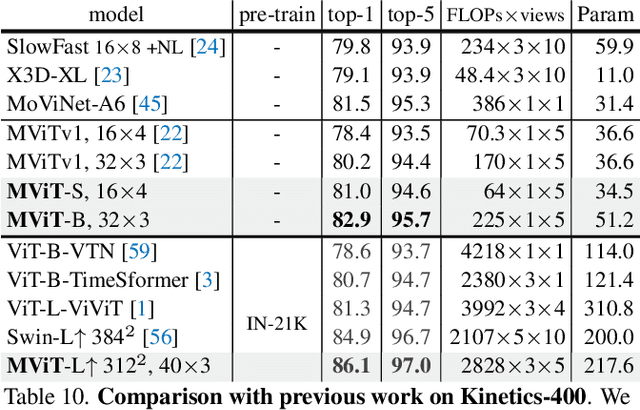
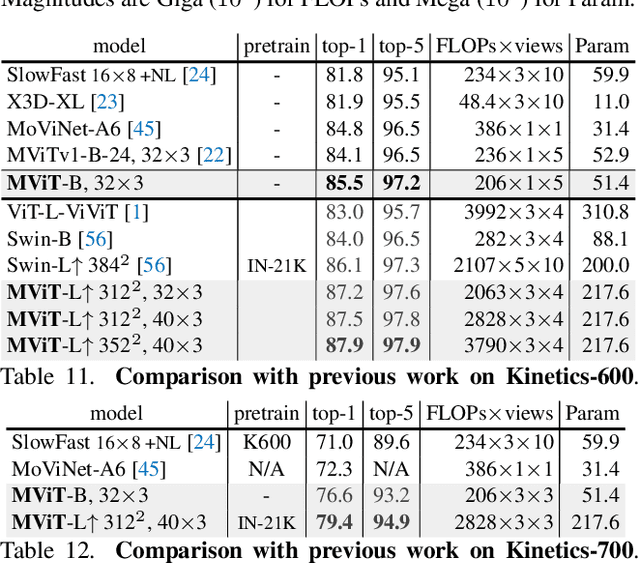
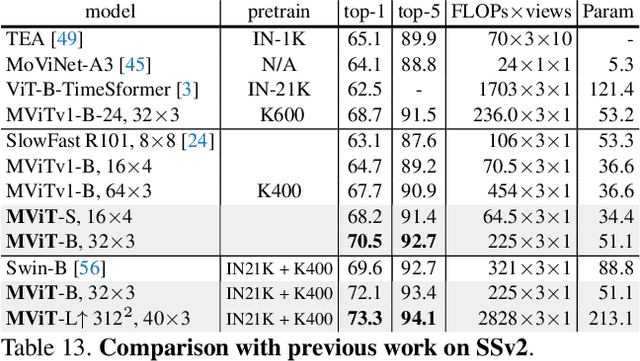
In this paper, we study Multiscale Vision Transformers (MViT) as a unified architecture for image and video classification, as well as object detection. We present an improved version of MViT that incorporates decomposed relative positional embeddings and residual pooling connections. We instantiate this architecture in five sizes and evaluate it for ImageNet classification, COCO detection and Kinetics video recognition where it outperforms prior work. We further compare MViTs' pooling attention to window attention mechanisms where it outperforms the latter in accuracy/compute. Without bells-and-whistles, MViT has state-of-the-art performance in 3 domains: 88.8% accuracy on ImageNet classification, 56.1 box AP on COCO object detection as well as 86.1% on Kinetics-400 video classification. Code and models will be made publicly available.
PyTorchVideo: A Deep Learning Library for Video Understanding
Nov 18, 2021
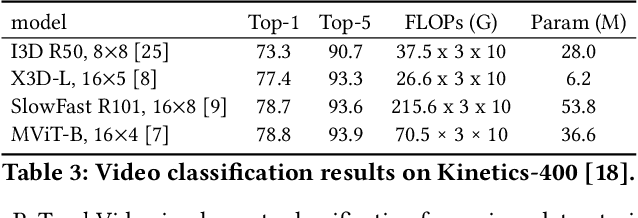

We introduce PyTorchVideo, an open-source deep-learning library that provides a rich set of modular, efficient, and reproducible components for a variety of video understanding tasks, including classification, detection, self-supervised learning, and low-level processing. The library covers a full stack of video understanding tools including multimodal data loading, transformations, and models that reproduce state-of-the-art performance. PyTorchVideo further supports hardware acceleration that enables real-time inference on mobile devices. The library is based on PyTorch and can be used by any training framework; for example, PyTorchLightning, PySlowFast, or Classy Vision. PyTorchVideo is available at https://pytorchvideo.org/