 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHao Ding
Context Uncertainty in Contextual Bandits with Applications to Recommender Systems
Feb 16, 2022
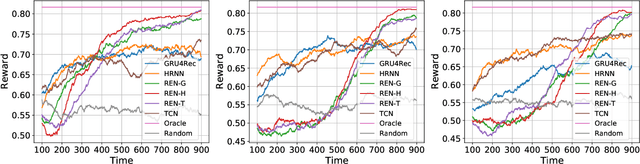
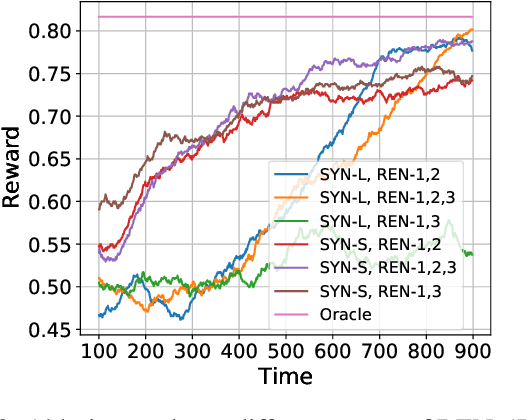
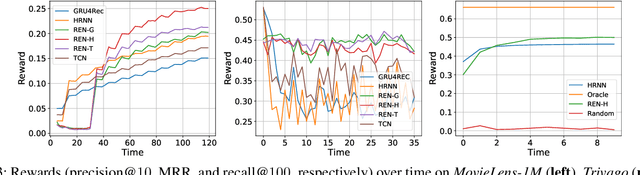
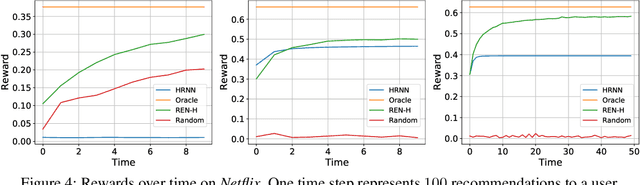
Recurrent neural networks have proven effective in modeling sequential user feedbacks for recommender systems. However, they usually focus solely on item relevance and fail to effectively explore diverse items for users, therefore harming the system performance in the long run. To address this problem, we propose a new type of recurrent neural networks, dubbed recurrent exploration networks (REN), to jointly perform representation learning and effective exploration in the latent space. REN tries to balance relevance and exploration while taking into account the uncertainty in the representations. Our theoretical analysis shows that REN can preserve the rate-optimal sublinear regret even when there exists uncertainty in the learned representations. Our empirical study demonstrates that REN can achieve satisfactory long-term rewards on both synthetic and real-world recommendation datasets, outperforming state-of-the-art models.
On the Sins of Image Synthesis Loss for Self-supervised Depth Estimation
Sep 13, 2021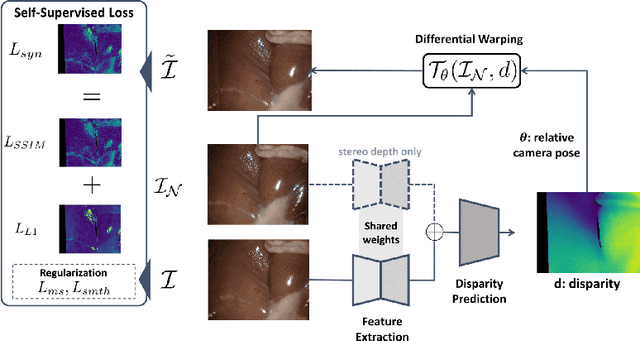
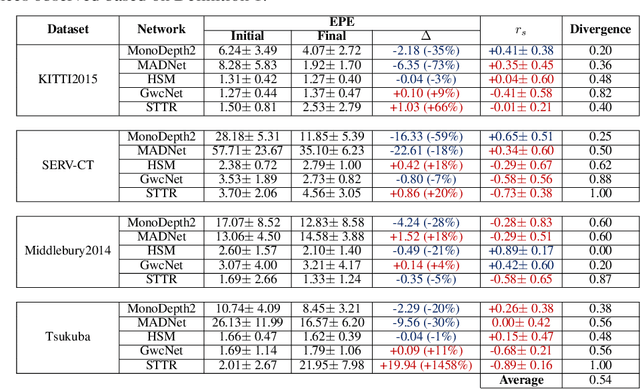
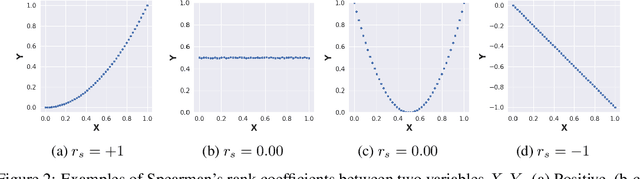
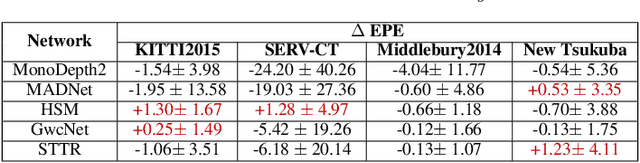
Scene depth estimation from stereo and monocular imagery is critical for extracting 3D information for downstream tasks such as scene understanding. Recently, learning-based methods for depth estimation have received much attention due to their high performance and flexibility in hardware choice. However, collecting ground truth data for supervised training of these algorithms is costly or outright impossible. This circumstance suggests a need for alternative learning approaches that do not require corresponding depth measurements. Indeed, self-supervised learning of depth estimation provides an increasingly popular alternative. It is based on the idea that observed frames can be synthesized from neighboring frames if accurate depth of the scene is known - or in this case, estimated. We show empirically that - contrary to common belief - improvements in image synthesis do not necessitate improvement in depth estimation. Rather, optimizing for image synthesis can result in diverging performance with respect to the main prediction objective - depth. We attribute this diverging phenomenon to aleatoric uncertainties, which originate from data. Based on our experiments on four datasets (spanning street, indoor, and medical) and five architectures (monocular and stereo), we conclude that this diverging phenomenon is independent of the dataset domain and not mitigated by commonly used regularization techniques. To underscore the importance of this finding, we include a survey of methods which use image synthesis, totaling 127 papers over the last six years. This observed divergence has not been previously reported or studied in depth, suggesting room for future improvement of self-supervised approaches which might be impacted the finding.
Influence Selection for Active Learning
Aug 20, 2021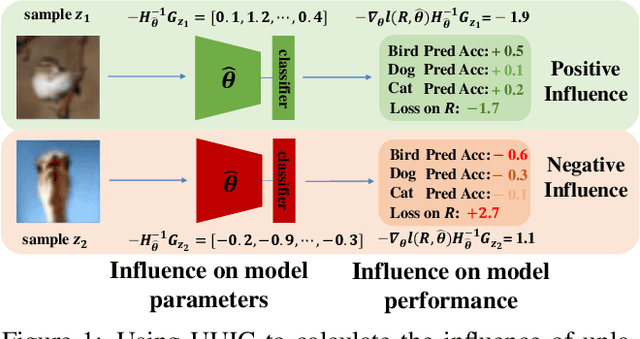
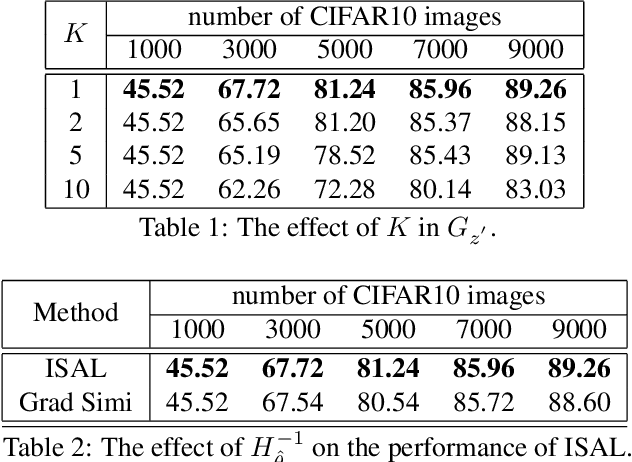
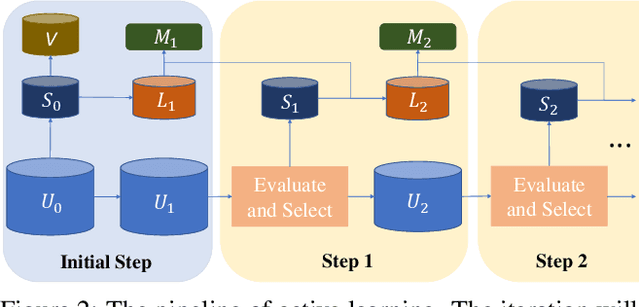
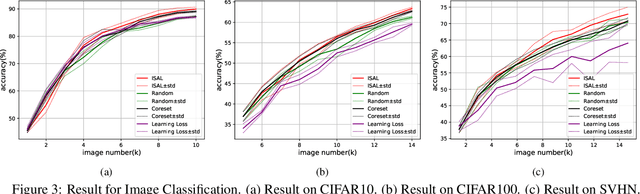
The existing active learning methods select the samples by evaluating the sample's uncertainty or its effect on the diversity of labeled datasets based on different task-specific or model-specific criteria. In this paper, we propose the Influence Selection for Active Learning(ISAL) which selects the unlabeled samples that can provide the most positive Influence on model performance. To obtain the Influence of the unlabeled sample in the active learning scenario, we design the Untrained Unlabeled sample Influence Calculation(UUIC) to estimate the unlabeled sample's expected gradient with which we calculate its Influence. To prove the effectiveness of UUIC, we provide both theoretical and experimental analyses. Since the UUIC just depends on the model gradients, which can be obtained easily from any neural network, our active learning algorithm is task-agnostic and model-agnostic. ISAL achieves state-of-the-art performance in different active learning settings for different tasks with different datasets. Compared with previous methods, our method decreases the annotation cost at least by 12%, 13% and 16% on CIFAR10, VOC2012 and COCO, respectively.
Zero-Shot Recommender Systems
May 18, 2021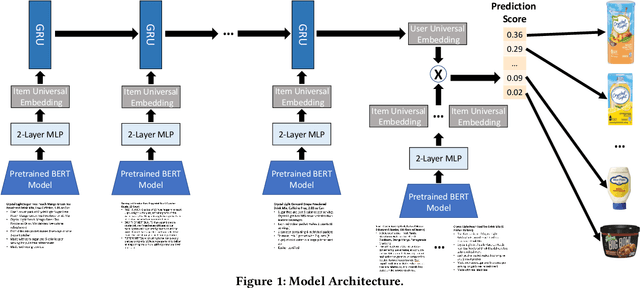

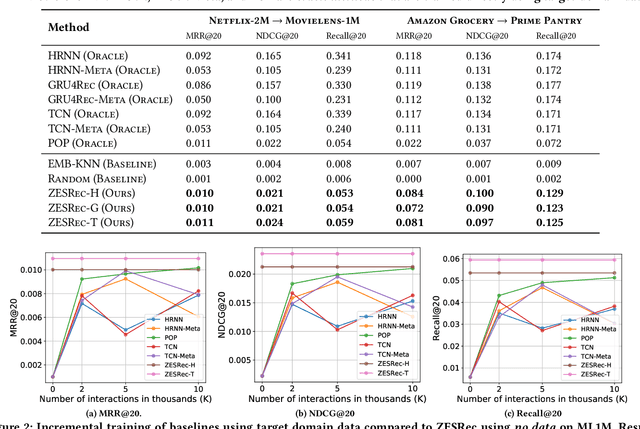
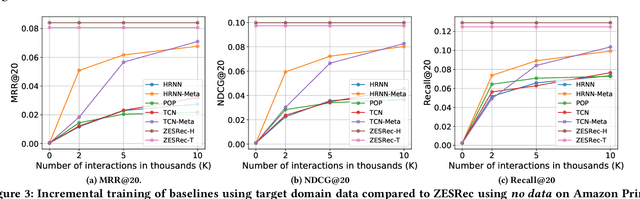
Performance of recommender systems (RS) relies heavily on the amount of training data available. This poses a chicken-and-egg problem for early-stage products, whose amount of data, in turn, relies on the performance of their RS. On the other hand, zero-shot learning promises some degree of generalization from an old dataset to an entirely new dataset. In this paper, we explore the possibility of zero-shot learning in RS. We develop an algorithm, dubbed ZEro-Shot Recommenders (ZESRec), that is trained on an old dataset and generalize to a new one where there are neither overlapping users nor overlapping items, a setting that contrasts typical cross-domain RS that has either overlapping users or items. Different from categorical item indices, i.e., item ID, in previous methods, ZESRec uses items' natural-language descriptions (or description embeddings) as their continuous indices, and therefore naturally generalize to any unseen items. In terms of users, ZESRec builds upon recent advances on sequential RS to represent users using their interactions with items, thereby generalizing to unseen users as well. We study two pairs of real-world RS datasets and demonstrate that ZESRec can successfully enable recommendations in such a zero-shot setting, opening up new opportunities for resolving the chicken-and-egg problem for data-scarce startups or early-stage products.
Cross-View Image Synthesis with Deformable Convolution and Attention Mechanism
Jul 20, 2020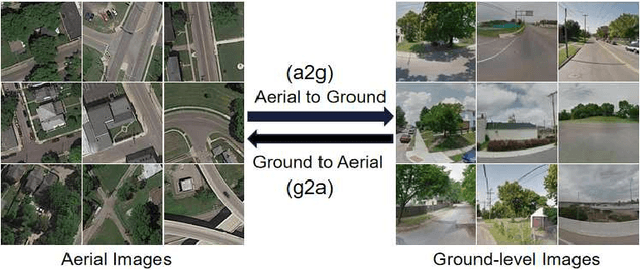
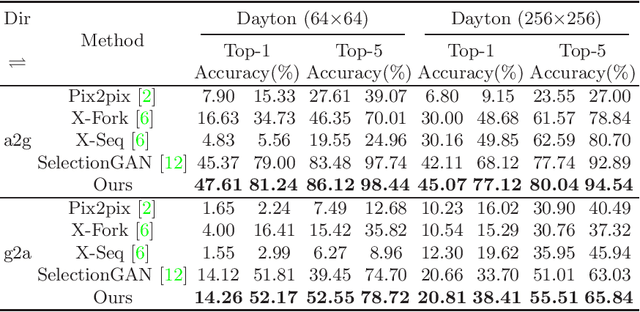
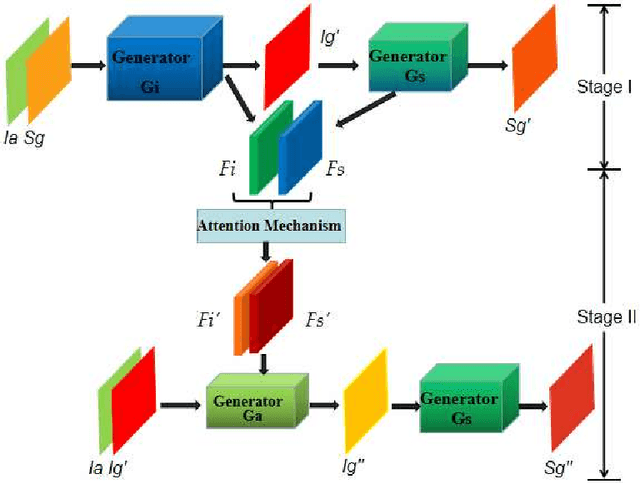
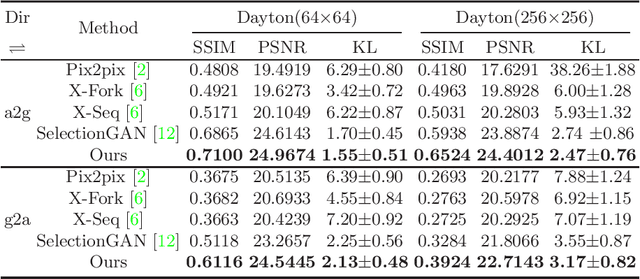
Learning to generate natural scenes has always been a daunting task in computer vision. This is even more laborious when generating images with very different views. When the views are very different, the view fields have little overlap or objects are occluded, leading the task very challenging. In this paper, we propose to use Generative Adversarial Networks(GANs) based on a deformable convolution and attention mechanism to solve the problem of cross-view image synthesis (see Fig.1). It is difficult to understand and transform scenes appearance and semantic information from another view, thus we use deformed convolution in the U-net network to improve the network's ability to extract features of objects at different scales. Moreover, to better learn the correspondence between images from different views, we apply an attention mechanism to refine the intermediate feature map thus generating more realistic images. A large number of experiments on different size images on the Dayton dataset[1] show that our model can produce better results than state-of-the-art methods.
Shape-aware Feature Extraction for Instance Segmentation
Nov 25, 2019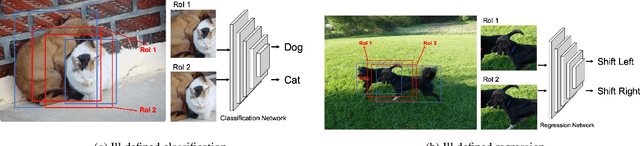
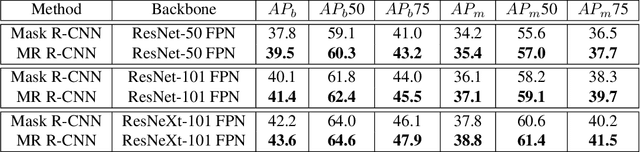

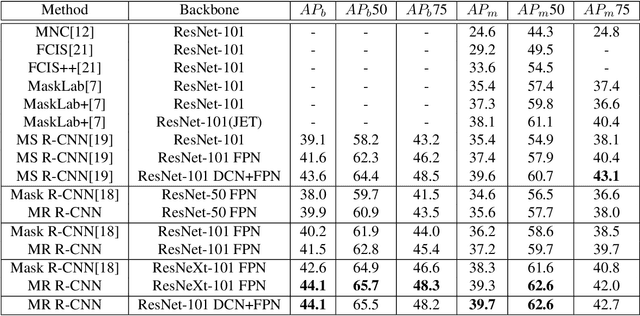
Modern instance segmentation approaches mainly adopt a sequential paradigm - ``detect then segment'', as popularized by Mask R-CNN, which have achieved considerable progress. However, they usually struggle to segment huddled instances, i.e., instances which are crowded together. The essential reason is the detection step is only learned under box-level supervision. Without the guidance from the mask-level supervision, the features extracted from the regions containing huddled instances are noisy and ambiguous, which makes the detection problem ill-posed. To address this issue, we propose a new region-of-interest (RoI) feature extraction strategy, named Shape-aware RoIAlign, which focuses feature extraction within a region aligned well with the shape of the instance-of-interest rather than a rectangular RoI. We instantiate Shape-aware RoIAlign by introducing a novel refining module built upon Mask R-CNN, which takes the mask predicted by Mask R-CNN as the region to guide the computation of Shape-aware RoIAlign. Based on the RoI features re-computed by Shape-aware RoIAlign, the refining module updates the bounding box as well as the mask predicted by Mask R-CNN. Experimental results show that the refining module equipped with Shape-aware RoIAlign achieves consistent and remarkable improvements than Mask R-CNN models with different backbones, respectively, on the challenging COCO dataset. The code will be released.
Unsupervised Inductive Whole-Graph Embedding by Preserving Graph Proximity
Apr 01, 2019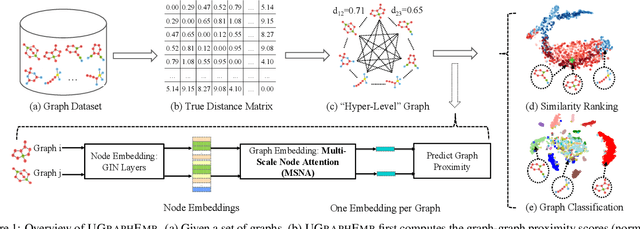
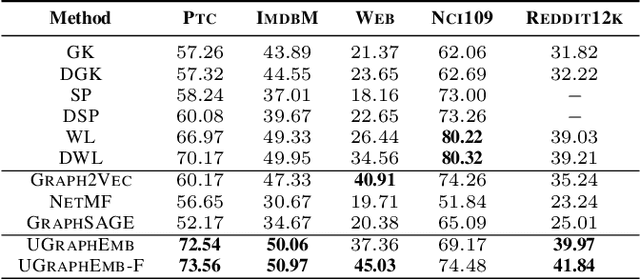
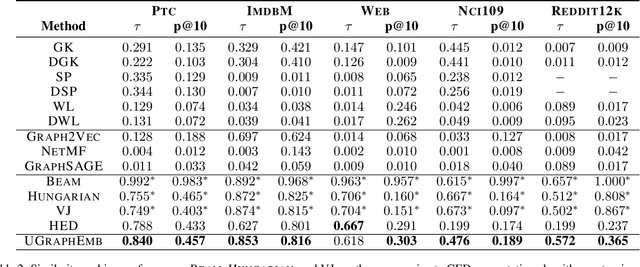

We introduce a novel approach to graph-level representation learning, which is to embed an entire graph into a vector space where the embeddings of two graphs preserve their graph-graph proximity. Our approach, UGRAPHEMB, is a general framework that provides a novel means to performing graph-level embedding in a completely unsupervised and inductive manner. The learned neural network can be considered as a function that receives any graph as input, either seen or unseen in the training set, and transforms it into an embedding. A novel graph-level embedding generation mechanism called Multi-Scale Node Attention (MSNA), is proposed. Experiments on five real graph datasets show that UGRAPHEMB achieves competitive accuracy in the tasks of graph classification, similarity ranking, and graph visualization.
Convolutional Set Matching for Graph Similarity
Oct 23, 2018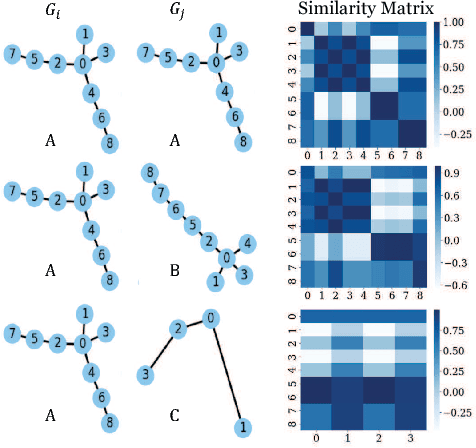
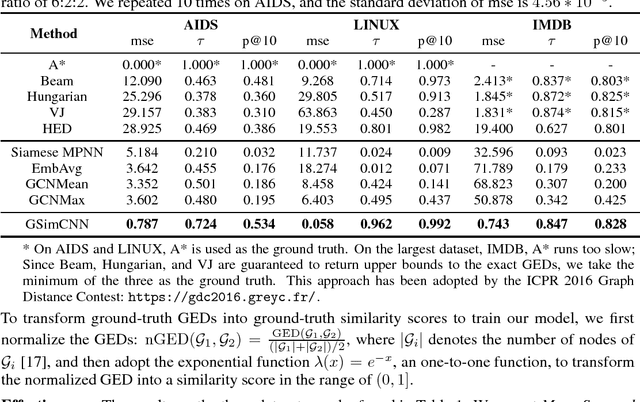

We introduce GSimCNN (Graph Similarity Computation via Convolutional Neural Networks) for predicting the similarity score between two graphs. As the core operation of graph similarity search, pairwise graph similarity computation is a challenging problem due to the NP-hard nature of computing many graph distance/similarity metrics. We demonstrate our model using the Graph Edit Distance (GED) as the example metric. Experiments on three real graph datasets demonstrate that our model achieves the state-of-the-art performance on graph similarity search.
Graph Edit Distance Computation via Graph Neural Networks
Oct 03, 2018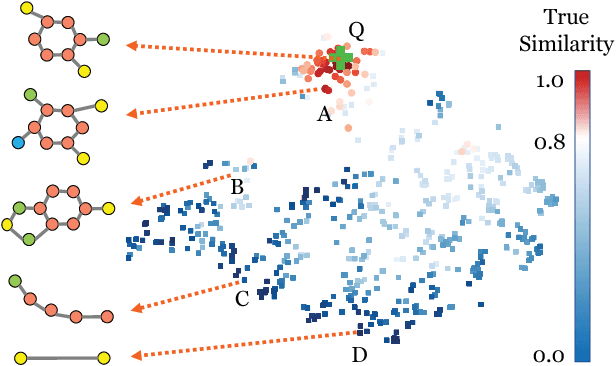

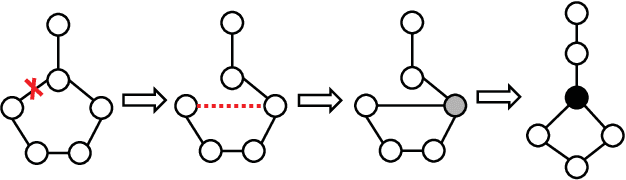
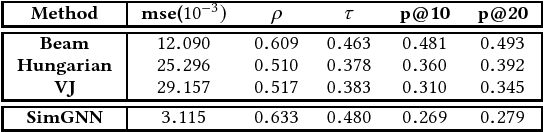
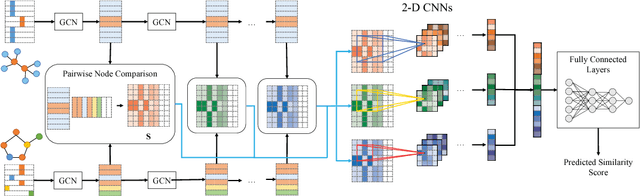
Graph similarity search is among the most important graph-based applications, e.g. finding the chemical compounds that are most similar to a query compound. Graph similarity/distance computation, such as Graph Edit Distance (GED) and Maximum Common Subgraph (MCS), is the core operation of graph similarity search and many other applications, but very costly to compute in practice. Inspired by the recent success of neural network approaches to several graph applications, such as node or graph classification, we propose a novel neural network based approach to address this classic yet challenging graph problem, aiming to alleviate the computational burden while preserving a good performance. The proposed approach, called SimGNN, combines two strategies. First, we design a learnable embedding function that maps every graph into an embedding vector, which provides a global summary of a graph. A novel attention mechanism is proposed to emphasize the important nodes with respect to a specific similarity metric. Second, we design a pairwise node comparison method to supplement the graph-level embeddings with fine-grained node-level information. Our model can be trained in an end-to-end fashion, achieves better generalization on unseen graphs, and in the worst case runs in quadratic time with respect to the number of nodes in two graphs. Taking GED computation as an example, experimental results on three real graph datasets demonstrate the effectiveness and efficiency of our approach. Specifically, our model achieves smaller error rate and great time reduction compared against a series of baselines, including several approximation algorithms on GED computation, and many existing graph neural network based models. Our study suggests SimGNN provides a new direction for future research on graph similarity computation and graph similarity search.