 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenome-Anchored Foundation Model Embeddings Improve Molecular Prediction from Histology Images
Jun 24, 2025

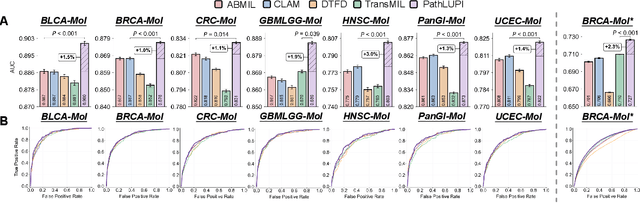

Precision oncology requires accurate molecular insights, yet obtaining these directly from genomics is costly and time-consuming for broad clinical use. Predicting complex molecular features and patient prognosis directly from routine whole-slide images (WSI) remains a major challenge for current deep learning methods. Here we introduce PathLUPI, which uses transcriptomic privileged information during training to extract genome-anchored histological embeddings, enabling effective molecular prediction using only WSIs at inference. Through extensive evaluation across 49 molecular oncology tasks using 11,257 cases among 20 cohorts, PathLUPI demonstrated superior performance compared to conventional methods trained solely on WSIs. Crucially, it achieves AUC $\geq$ 0.80 in 14 of the biomarker prediction and molecular subtyping tasks and C-index $\geq$ 0.70 in survival cohorts of 5 major cancer types. Moreover, PathLUPI embeddings reveal distinct cellular morphological signatures associated with specific genotypes and related biological pathways within WSIs. By effectively encoding molecular context to refine WSI representations, PathLUPI overcomes a key limitation of existing models and offers a novel strategy to bridge molecular insights with routine pathology workflows for wider clinical application.
Vision as a Dialect: Unifying Visual Understanding and Generation via Text-Aligned Representations
Jun 23, 2025



This paper presents a multimodal framework that attempts to unify visual understanding and generation within a shared discrete semantic representation. At its core is the Text-Aligned Tokenizer (TA-Tok), which converts images into discrete tokens using a text-aligned codebook projected from a large language model's (LLM) vocabulary. By integrating vision and text into a unified space with an expanded vocabulary, our multimodal LLM, Tar, enables cross-modal input and output through a shared interface, without the need for modality-specific designs. Additionally, we propose scale-adaptive encoding and decoding to balance efficiency and visual detail, along with a generative de-tokenizer to produce high-fidelity visual outputs. To address diverse decoding needs, we utilize two complementary de-tokenizers: a fast autoregressive model and a diffusion-based model. To enhance modality fusion, we investigate advanced pre-training tasks, demonstrating improvements in both visual understanding and generation. Experiments across benchmarks show that Tar matches or surpasses existing multimodal LLM methods, achieving faster convergence and greater training efficiency. Code, models, and data are available at https://tar.csuhan.com
EmbodiedPlace: Learning Mixture-of-Features with Embodied Constraints for Visual Place Recognition
Jun 16, 2025Visual Place Recognition (VPR) is a scene-oriented image retrieval problem in computer vision in which re-ranking based on local features is commonly employed to improve performance. In robotics, VPR is also referred to as Loop Closure Detection, which emphasizes spatial-temporal verification within a sequence. However, designing local features specifically for VPR is impractical, and relying on motion sequences imposes limitations. Inspired by these observations, we propose a novel, simple re-ranking method that refines global features through a Mixture-of-Features (MoF) approach under embodied constraints. First, we analyze the practical feasibility of embodied constraints in VPR and categorize them according to existing datasets, which include GPS tags, sequential timestamps, local feature matching, and self-similarity matrices. We then propose a learning-based MoF weight-computation approach, utilizing a multi-metric loss function. Experiments demonstrate that our method improves the state-of-the-art (SOTA) performance on public datasets with minimal additional computational overhead. For instance, with only 25 KB of additional parameters and a processing time of 10 microseconds per frame, our method achieves a 0.9\% improvement over a DINOv2-based baseline performance on the Pitts-30k test set.
MT-PCR: A Hybrid Mamba-Transformer with Spatial Serialization for Hierarchical Point Cloud Registration
Jun 16, 2025Point cloud registration (PCR) is a fundamental task in 3D computer vision and robotics. Most existing learning-based PCR methods rely on Transformers, which suffer from quadratic computational complexity. This limitation restricts the resolution of point clouds that can be processed, inevitably leading to information loss. In contrast, Mamba-a recently proposed model based on state space models (SSMs)-achieves linear computational complexity while maintaining strong long-range contextual modeling capabilities. However, directly applying Mamba to PCR tasks yields suboptimal performance due to the unordered and irregular nature of point cloud data. To address this challenge, we propose MT-PCR, the first point cloud registration framework that integrates both Mamba and Transformer modules. Specifically, we serialize point cloud features using Z-order space-filling curves to enforce spatial locality, enabling Mamba to better model the geometric structure of the input. Additionally, we remove the order indicator module commonly used in Mamba-based sequence modeling, leads to improved performance in our setting. The serialized features are then processed by an optimized Mamba encoder, followed by a Transformer refinement stage. Extensive experiments on multiple benchmarks demonstrate that MT-PCR outperforms Transformer-based and concurrent state-of-the-art methods in both accuracy and efficiency, significantly reducing while GPU memory usage and FLOPs.
SuperPlace: The Renaissance of Classical Feature Aggregation for Visual Place Recognition in the Era of Foundation Models
Jun 16, 2025Recent visual place recognition (VPR) approaches have leveraged foundation models (FM) and introduced novel aggregation techniques. However, these methods have failed to fully exploit key concepts of FM, such as the effective utilization of extensive training sets, and they have overlooked the potential of classical aggregation methods, such as GeM and NetVLAD. Building on these insights, we revive classical feature aggregation methods and develop more fundamental VPR models, collectively termed SuperPlace. First, we introduce a supervised label alignment method that enables training across various VPR datasets within a unified framework. Second, we propose G$^2$M, a compact feature aggregation method utilizing two GeMs, where one GeM learns the principal components of feature maps along the channel dimension and calibrates the output of the other. Third, we propose the secondary fine-tuning (FT$^2$) strategy for NetVLAD-Linear (NVL). NetVLAD first learns feature vectors in a high-dimensional space and then compresses them into a lower-dimensional space via a single linear layer. Extensive experiments highlight our contributions and demonstrate the superiority of SuperPlace. Specifically, G$^2$M achieves promising results with only one-tenth of the feature dimensions compared to recent methods. Moreover, NVL-FT$^2$ ranks first on the MSLS leaderboard.
Improving Multimodal Learning Balance and Sufficiency through Data Remixing
Jun 16, 2025
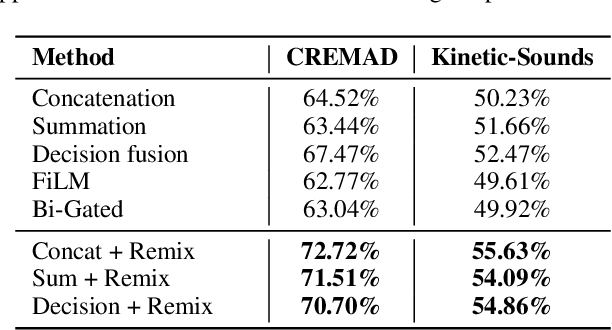


Different modalities hold considerable gaps in optimization trajectories, including speeds and paths, which lead to modality laziness and modality clash when jointly training multimodal models, resulting in insufficient and imbalanced multimodal learning. Existing methods focus on enforcing the weak modality by adding modality-specific optimization objectives, aligning their optimization speeds, or decomposing multimodal learning to enhance unimodal learning. These methods fail to achieve both unimodal sufficiency and multimodal balance. In this paper, we, for the first time, address both concerns by proposing multimodal Data Remixing, including decoupling multimodal data and filtering hard samples for each modality to mitigate modality imbalance; and then batch-level reassembling to align the gradient directions and avoid cross-modal interference, thus enhancing unimodal learning sufficiency. Experimental results demonstrate that our method can be seamlessly integrated with existing approaches, improving accuracy by approximately 6.50%$\uparrow$ on CREMAD and 3.41%$\uparrow$ on Kinetic-Sounds, without training set expansion or additional computational overhead during inference. The source code is available at https://github.com/MatthewMaxy/Remix_ICML2025.
Macro Graph of Experts for Billion-Scale Multi-Task Recommendation
Jun 12, 2025Graph-based multi-task learning at billion-scale presents a significant challenge, as different tasks correspond to distinct billion-scale graphs. Traditional multi-task learning methods often neglect these graph structures, relying solely on individual user and item embeddings. However, disregarding graph structures overlooks substantial potential for improving performance. In this paper, we introduce the Macro Graph of Expert (MGOE) framework, the first approach capable of leveraging macro graph embeddings to capture task-specific macro features while modeling the correlations between task-specific experts. Specifically, we propose the concept of a Macro Graph Bottom, which, for the first time, enables multi-task learning models to incorporate graph information effectively. We design the Macro Prediction Tower to dynamically integrate macro knowledge across tasks. MGOE has been deployed at scale, powering multi-task learning for the homepage of a leading billion-scale recommender system. Extensive offline experiments conducted on three public benchmark datasets demonstrate its superiority over state-of-the-art multi-task learning methods, establishing MGOE as a breakthrough in multi-task graph-based recommendation. Furthermore, online A/B tests confirm the superiority of MGOE in billion-scale recommender systems.
CXR-LT 2024: A MICCAI challenge on long-tailed, multi-label, and zero-shot disease classification from chest X-ray
Jun 09, 2025The CXR-LT series is a community-driven initiative designed to enhance lung disease classification using chest X-rays (CXR). It tackles challenges in open long-tailed lung disease classification and enhances the measurability of state-of-the-art techniques. The first event, CXR-LT 2023, aimed to achieve these goals by providing high-quality benchmark CXR data for model development and conducting comprehensive evaluations to identify ongoing issues impacting lung disease classification performance. Building on the success of CXR-LT 2023, the CXR-LT 2024 expands the dataset to 377,110 chest X-rays (CXRs) and 45 disease labels, including 19 new rare disease findings. It also introduces a new focus on zero-shot learning to address limitations identified in the previous event. Specifically, CXR-LT 2024 features three tasks: (i) long-tailed classification on a large, noisy test set, (ii) long-tailed classification on a manually annotated "gold standard" subset, and (iii) zero-shot generalization to five previously unseen disease findings. This paper provides an overview of CXR-LT 2024, detailing the data curation process and consolidating state-of-the-art solutions, including the use of multimodal models for rare disease detection, advanced generative approaches to handle noisy labels, and zero-shot learning strategies for unseen diseases. Additionally, the expanded dataset enhances disease coverage to better represent real-world clinical settings, offering a valuable resource for future research. By synthesizing the insights and innovations of participating teams, we aim to advance the development of clinically realistic and generalizable diagnostic models for chest radiography.
SDP-CROWN: Efficient Bound Propagation for Neural Network Verification with Tightness of Semidefinite Programming
Jun 07, 2025Neural network verifiers based on linear bound propagation scale impressively to massive models but can be surprisingly loose when neuron coupling is crucial. Conversely, semidefinite programming (SDP) verifiers capture inter-neuron coupling naturally, but their cubic complexity restricts them to only small models. In this paper, we propose SDP-CROWN, a novel hybrid verification framework that combines the tightness of SDP relaxations with the scalability of bound-propagation verifiers. At the core of SDP-CROWN is a new linear bound, derived via SDP principles, that explicitly captures $\ell_{2}$-norm-based inter-neuron coupling while adding only one extra parameter per layer. This bound can be integrated seamlessly into any linear bound-propagation pipeline, preserving the inherent scalability of such methods yet significantly improving tightness. In theory, we prove that our inter-neuron bound can be up to a factor of $\sqrt{n}$ tighter than traditional per-neuron bounds. In practice, when incorporated into the state-of-the-art $\alpha$-CROWN verifier, we observe markedly improved verification performance on large models with up to 65 thousand neurons and 2.47 million parameters, achieving tightness that approaches that of costly SDP-based methods.
SeedVR2: One-Step Video Restoration via Diffusion Adversarial Post-Training
Jun 05, 2025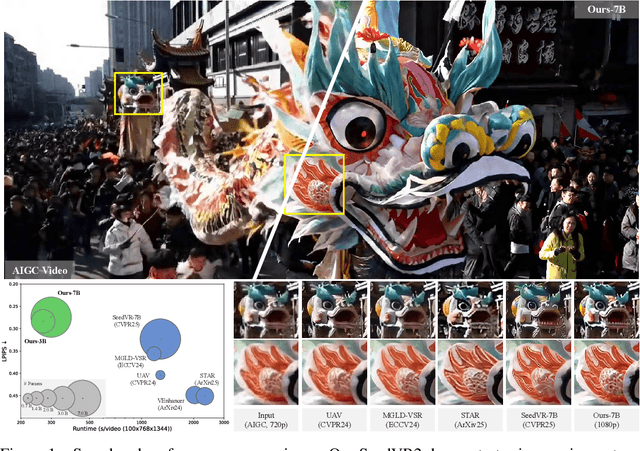
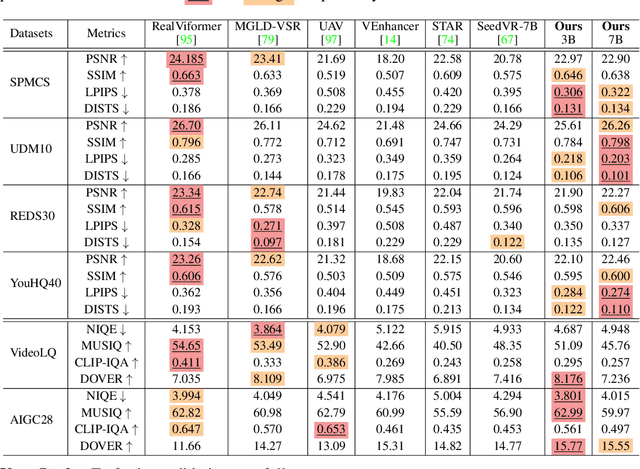
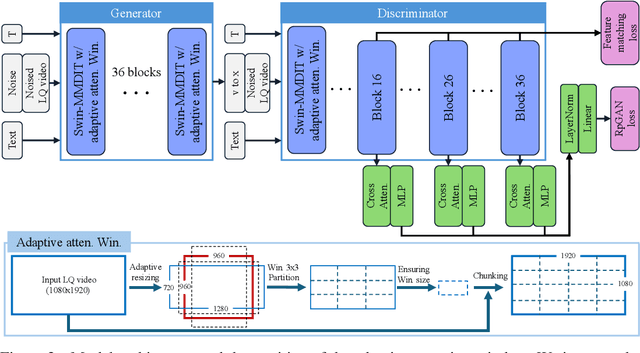
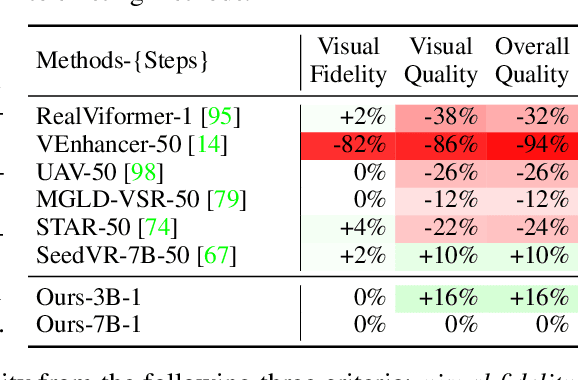
Recent advances in diffusion-based video restoration (VR) demonstrate significant improvement in visual quality, yet yield a prohibitive computational cost during inference. While several distillation-based approaches have exhibited the potential of one-step image restoration, extending existing approaches to VR remains challenging and underexplored, particularly when dealing with high-resolution video in real-world settings. In this work, we propose a one-step diffusion-based VR model, termed as SeedVR2, which performs adversarial VR training against real data. To handle the challenging high-resolution VR within a single step, we introduce several enhancements to both model architecture and training procedures. Specifically, an adaptive window attention mechanism is proposed, where the window size is dynamically adjusted to fit the output resolutions, avoiding window inconsistency observed under high-resolution VR using window attention with a predefined window size. To stabilize and improve the adversarial post-training towards VR, we further verify the effectiveness of a series of losses, including a proposed feature matching loss without significantly sacrificing training efficiency. Extensive experiments show that SeedVR2 can achieve comparable or even better performance compared with existing VR approaches in a single step.