 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViT-EnsembleAttack: Augmenting Ensemble Models for Stronger Adversarial Transferability in Vision Transformers
Aug 17, 2025Ensemble-based attacks have been proven to be effective in enhancing adversarial transferability by aggregating the outputs of models with various architectures. However, existing research primarily focuses on refining ensemble weights or optimizing the ensemble path, overlooking the exploration of ensemble models to enhance the transferability of adversarial attacks. To address this gap, we propose applying adversarial augmentation to the surrogate models, aiming to boost overall generalization of ensemble models and reduce the risk of adversarial overfitting. Meanwhile, observing that ensemble Vision Transformers (ViTs) gain less attention, we propose ViT-EnsembleAttack based on the idea of model adversarial augmentation, the first ensemble-based attack method tailored for ViTs to the best of our knowledge. Our approach generates augmented models for each surrogate ViT using three strategies: Multi-head dropping, Attention score scaling, and MLP feature mixing, with the associated parameters optimized by Bayesian optimization. These adversarially augmented models are ensembled to generate adversarial examples. Furthermore, we introduce Automatic Reweighting and Step Size Enlargement modules to boost transferability. Extensive experiments demonstrate that ViT-EnsembleAttack significantly enhances the adversarial transferability of ensemble-based attacks on ViTs, outperforming existing methods by a substantial margin. Code is available at https://github.com/Trustworthy-AI-Group/TransferAttack.
MISO: Multiresolution Submap Optimization for Efficient Globally Consistent Neural Implicit Reconstruction
Apr 27, 2025



Neural implicit representations have had a significant impact on simultaneous localization and mapping (SLAM) by enabling robots to build continuous, differentiable, and high-fidelity 3D maps from sensor data. However, as the scale and complexity of the environment increase, neural SLAM approaches face renewed challenges in the back-end optimization process to keep up with runtime requirements and maintain global consistency. We introduce MISO, a hierarchical optimization approach that leverages multiresolution submaps to achieve efficient and scalable neural implicit reconstruction. For local SLAM within each submap, we develop a hierarchical optimization scheme with learned initialization that substantially reduces the time needed to optimize the implicit submap features. To correct estimation drift globally, we develop a hierarchical method to align and fuse the multiresolution submaps, leading to substantial acceleration by avoiding the need to decode the full scene geometry. MISO significantly improves computational efficiency and estimation accuracy of neural signed distance function (SDF) SLAM on large-scale real-world benchmarks.
PKF: Probabilistic Data Association Kalman Filter for Multi-Object Tracking
Nov 10, 2024In this paper, we derive a new Kalman filter with probabilistic data association between measurements and states. We formulate a variational inference problem to approximate the posterior density of the state conditioned on the measurement data. We view the unknown data association as a latent variable and apply Expectation Maximization (EM) to obtain a filter with update step in the same form as the Kalman filter but with expanded measurement vector of all potential associations. We show that the association probabilities can be computed as permanents of matrices with measurement likelihood entries. We also propose an ambiguity check that associates only a subset of ambiguous measurements and states probabilistically, thus reducing the association time and preventing low-probability measurements from harming the estimation accuracy. Experiments in simulation show that our filter achieves lower tracking errors than the well-established joint probabilistic data association filter (JPDAF), while running at comparable rate. We also demonstrate the effectiveness of our filter in multi-object tracking (MOT) on multiple real-world datasets, including MOT17, MOT20, and DanceTrack. We achieve better higher order tracking accuracy (HOTA) than previous Kalman-filter methods and remain real-time. Associating only bounding boxes without deep features or velocities, our method ranks top-10 on both MOT17 and MOT20 in terms of HOTA. Given offline detections, our algorithm tracks at 250+ fps on a single laptop CPU. Code is available at https://github.com/hwcao17/pkf.
Multi-Robot Object SLAM using Distributed Variational Inference
Apr 28, 2024



Multi-robot simultaneous localization and mapping (SLAM) enables a robot team to achieve coordinated tasks relying on a common map. However, centralized processing of robot observations is undesirable because it creates a single point of failure and requires pre-existing infrastructure and significant multi-hop communication throughput. This paper formulates multi-robot object SLAM as a variational inference problem over a communication graph. We impose a consensus constraint on the objects maintained by different nodes to ensure agreement on a common map. To solve the problem, we develop a distributed mirror descent algorithm with a regularization term enforcing consensus. Using Gaussian distributions in the algorithm, we derive a distributed multi-state constraint Kalman filter (MSCKF) for multi-robot object SLAM. Experiments on real and simulated data show that our method improves the trajectory and object estimates, compared to individual-robot SLAM, while achieving better scaling to large robot teams, compared to centralized multi-robot SLAM. Code is available at https://github.com/intrepidChw/distributed_msckf.
Two-Stage Grasping: A New Bin Picking Framework for Small Objects
Mar 07, 2023This paper proposes a novel bin picking framework, two-stage grasping, aiming at precise grasping of cluttered small objects. Object density estimation and rough grasping are conducted in the first stage. Fine segmentation, detection, grasping, and pushing are performed in the second stage. A small object bin picking system has been realized to exhibit the concept of two-stage grasping. Experiments have shown the effectiveness of the proposed framework. Unlike traditional bin picking methods focusing on vision-based grasping planning using classic frameworks, the challenges of picking cluttered small objects can be solved by the proposed new framework with simple vision detection and planning.
Codebook Based Two-Time Scale Resource Allocation Design for IRS-Assisted eMBB-URLLC Systems
Aug 07, 2022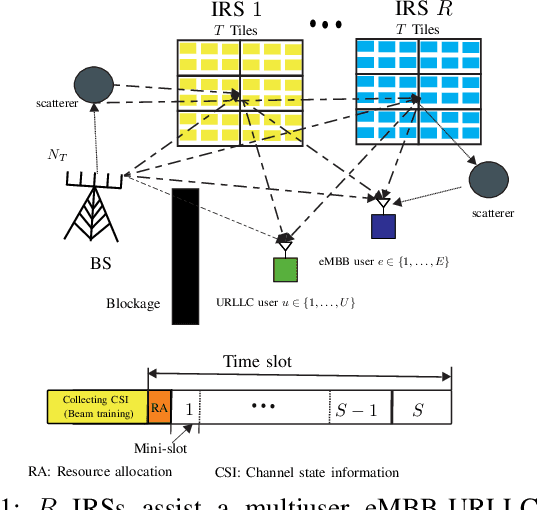
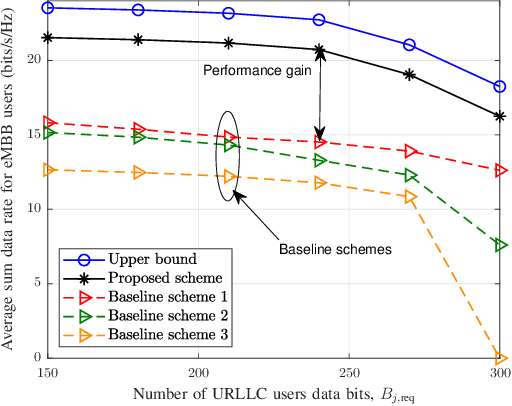
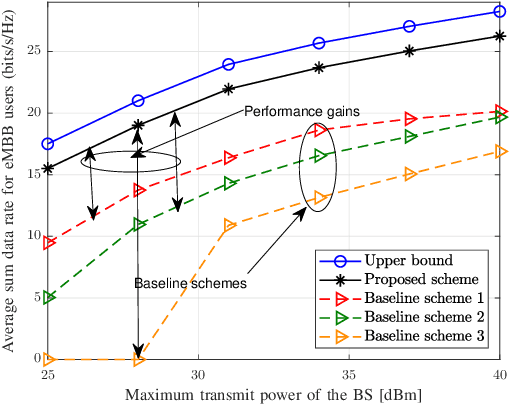
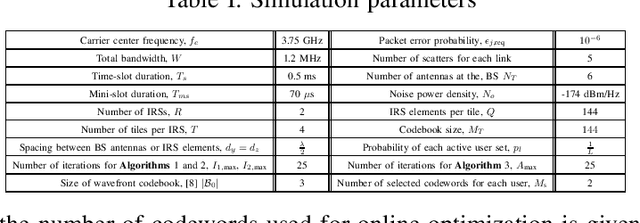
This paper investigates the resource allocation algorithm design for wireless systems assisted by large intelligent reflecting surfaces (IRSs) with coexisting enhanced mobile broadband (eMBB) and ultra reliable low-latency communication (URLLC) users. We consider a two-time scale resource allocation scheme, whereby the base station's precoders are optimized in each mini-slot to adapt to newly arriving URLLC traffic, whereas the IRS phase shifts are reconfigured only in each time slot to avoid excessive base station-IRS signaling. To facilitate efficient resource allocation design for large IRSs, we employ a codebook-based optimization framework, where the IRS is divided into several tiles and the phase-shift elements of each tile are selected from a pre-defined codebook. The resource allocation algorithm design is formulated as an optimization problem for the maximization of the average sum data rate of the eMBB users over a time slot while guaranteeing the quality-of-service (QoS) of each URLLC user in each mini-slot. An iterative algorithm based on alternating optimization (AO) is proposed to find a high-quality suboptimal solution. As a case study, the proposed algorithm is applied in an industrial indoor environment modelled via the Quadriga channel simulator. Our simulation results show that the proposed algorithm design enables the coexistence of eMBB and URLLC users and yields large performance gains compared to three baseline schemes. Furthermore, our simulation results reveal that the proposed two-time scale resource allocation design incurs only a small performance loss compared to the case when the IRSs are optimized in each mini-slot.
Optimization-based Phase-shift Codebook Design for Large IRSs
Mar 03, 2022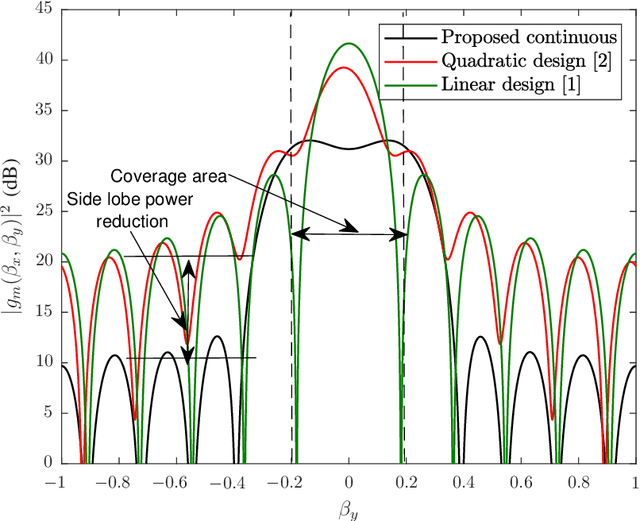
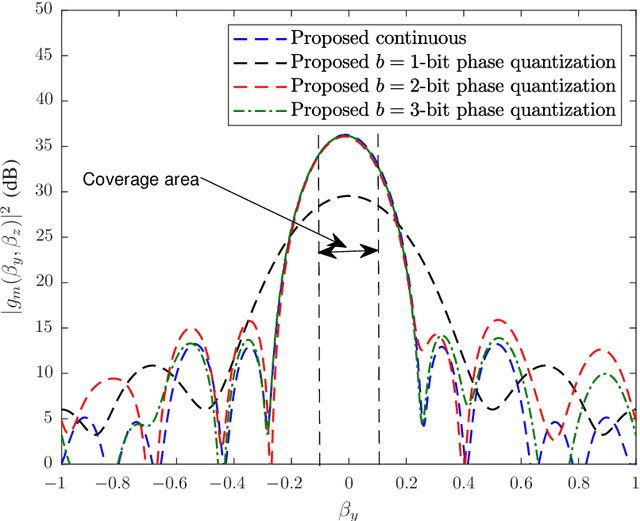
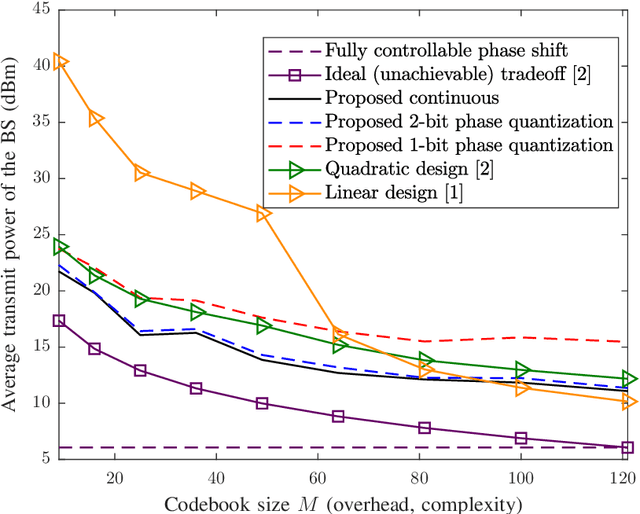
In this paper, we focus on large intelligent reflecting surfaces (IRSs) and propose a new codebook construction method to obtain a set of pre-designed phase-shift configurations for the IRS unit cells. Since the complexity of online optimization and the overhead for channel estimation for IRS-assisted communications scale with the size of the phase-shift codebook, the design of small codebooks is of high importance. We consider both continuous and discrete phase shift designs and formulate the codebook construction as optimization problems. To solve the optimization problems, we propose an optimal algorithm for the discrete phaseshift design and a low-complexity sub-optimal solution for the continuous design. Simulation results show that the proposed algorithms facilitate the construction of codebooks of different sizes and with different beamwidths. Moreover, the performance of the discrete phase-shift design with 2-bit quantization is shown to approach that of the continuous phase-shift design. Finally, our simulation results show that the proposed designs enable large transmit power savings compared to the existing linear and quadratic codebook designs.
Fuzzy-Depth Objects Grasping Based on FSG Algorithm and a Soft Robotic Hand
Oct 21, 2021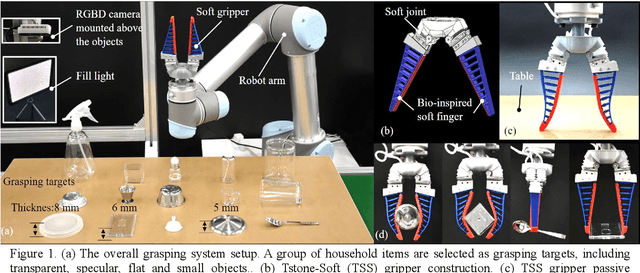
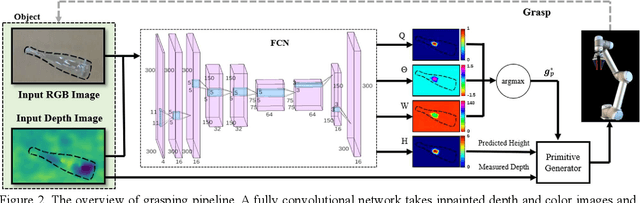
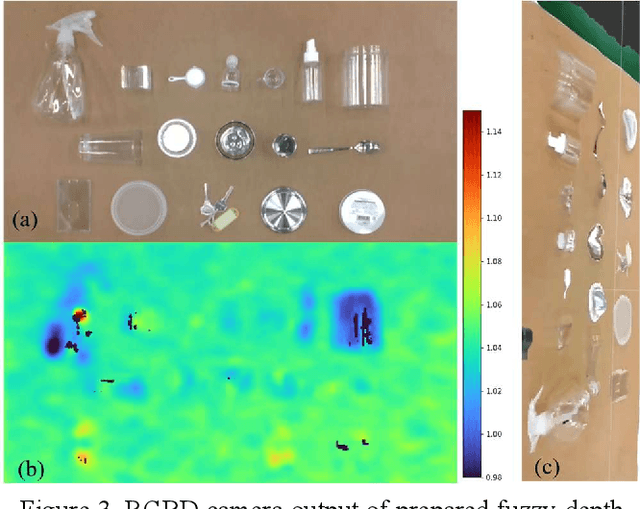

Autonomous grasping is an important factor for robots physically interacting with the environment and executing versatile tasks. However, a universally applicable, cost-effective, and rapidly deployable autonomous grasping approach is still limited by those target objects with fuzzy-depth information. Examples are transparent, specular, flat, and small objects whose depth is difficult to be accurately sensed. In this work, we present a solution to those fuzzy-depth objects. The framework of our approach includes two major components: one is a soft robotic hand and the other one is a Fuzzy-depth Soft Grasping (FSG) algorithm. The soft hand is replaceable for most existing soft hands/grippers with body compliance. FSG algorithm exploits both RGB and depth images to predict grasps while not trying to reconstruct the whole scene. Two grasping primitives are designed to further increase robustness. The proposed method outperforms reference baselines in unseen fuzzy-depth objects grasping experiments (84% success rate).
SuctionNet-1Billion: A Large-Scale Benchmark for Suction Grasping
Mar 23, 2021



Suction is an important solution for the longstanding robotic grasping problem. Compared with other kinds of grasping, suction grasping is easier to represent and often more reliable in practice. Though preferred in many scenarios, it is not fully investigated and lacks sufficient training data and evaluation benchmarks. To address that, firstly, we propose a new physical model to analytically evaluate seal formation and wrench resistance of a suction grasping, which are two key aspects of grasp success. Secondly, a two-step methodology is adopted to generate annotations on a large-scale dataset collected in real-world cluttered scenarios. Thirdly, a standard online evaluation system is proposed to evaluate suction poses in continuous operation space, which can benchmark different algorithms fairly without the need of exhaustive labeling. Real-robot experiments are conducted to show that our annotations align well with real world. Meanwhile, we propose a method to predict numerous suction poses from an RGB-D image of a cluttered scene and demonstrate our superiority against several previous methods. Result analyses are further provided to help readers better understand the challenges in this area. Data and source code are publicly available at www.graspnet.net.
TDAF: Top-Down Attention Framework for Vision Tasks
Dec 14, 2020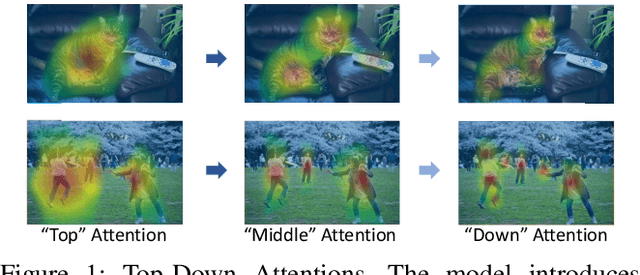
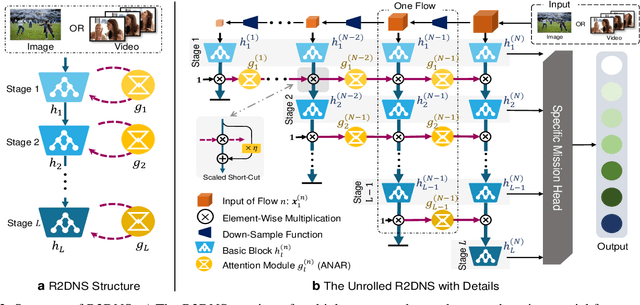
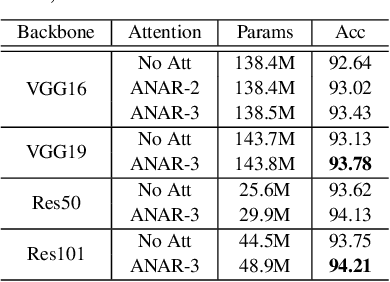
Human attention mechanisms often work in a top-down manner, yet it is not well explored in vision research. Here, we propose the Top-Down Attention Framework (TDAF) to capture top-down attentions, which can be easily adopted in most existing models. The designed Recursive Dual-Directional Nested Structure in it forms two sets of orthogonal paths, recursive and structural ones, where bottom-up spatial features and top-down attention features are extracted respectively. Such spatial and attention features are nested deeply, therefore, the proposed framework works in a mixed top-down and bottom-up manner. Empirical evidence shows that our TDAF can capture effective stratified attention information and boost performance. ResNet with TDAF achieves 2.0% improvements on ImageNet. For object detection, the performance is improved by 2.7% AP over FCOS. For pose estimation, TDAF improves the baseline by 1.6%. And for action recognition, the 3D-ResNet adopting TDAF achieves improvements of 1.7% accuracy.