 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiarizationLM: Speaker Diarization Post-Processing with Large Language Models
Jan 16, 2024



In this paper, we introduce DiarizationLM, a framework to leverage large language models (LLM) to post-process the outputs from a speaker diarization system. Various goals can be achieved with the proposed framework, such as improving the readability of the diarized transcript, or reducing the word diarization error rate (WDER). In this framework, the outputs of the automatic speech recognition (ASR) and speaker diarization systems are represented as a compact textual format, which is included in the prompt to an optionally finetuned LLM. The outputs of the LLM can be used as the refined diarization results with the desired enhancement. As a post-processing step, this framework can be easily applied to any off-the-shelf ASR and speaker diarization systems without retraining existing components. Our experiments show that a finetuned PaLM 2-S model can reduce the WDER by rel. 55.5% on the Fisher telephone conversation dataset, and rel. 44.9% on the Callhome English dataset.
On Robustness to Missing Video for Audiovisual Speech Recognition
Dec 19, 2023



It has been shown that learning audiovisual features can lead to improved speech recognition performance over audio-only features, especially for noisy speech. However, in many common applications, the visual features are partially or entirely missing, e.g.~the speaker might move off screen. Multi-modal models need to be robust: missing video frames should not degrade the performance of an audiovisual model to be worse than that of a single-modality audio-only model. While there have been many attempts at building robust models, there is little consensus on how robustness should be evaluated. To address this, we introduce a framework that allows claims about robustness to be evaluated in a precise and testable way. We also conduct a systematic empirical study of the robustness of common audiovisual speech recognition architectures on a range of acoustic noise conditions and test suites. Finally, we show that an architecture-agnostic solution based on cascades can consistently achieve robustness to missing video, even in settings where existing techniques for robustness like dropout fall short.
Towards Word-Level End-to-End Neural Speaker Diarization with Auxiliary Network
Sep 15, 2023



While standard speaker diarization attempts to answer the question "who spoken when", most of relevant applications in reality are more interested in determining "who spoken what". Whether it is the conventional modularized approach or the more recent end-to-end neural diarization (EEND), an additional automatic speech recognition (ASR) model and an orchestration algorithm are required to associate the speaker labels with recognized words. In this paper, we propose Word-level End-to-End Neural Diarization (WEEND) with auxiliary network, a multi-task learning algorithm that performs end-to-end ASR and speaker diarization in the same neural architecture. That is, while speech is being recognized, speaker labels are predicted simultaneously for each recognized word. Experimental results demonstrate that WEEND outperforms the turn-based diarization baseline system on all 2-speaker short-form scenarios and has the capability to generalize to audio lengths of 5 minutes. Although 3+speaker conversations are harder, we find that with enough in-domain training data, WEEND has the potential to deliver high quality diarized text.
USM-SCD: Multilingual Speaker Change Detection Based on Large Pretrained Foundation Models
Sep 14, 2023We introduce a multilingual speaker change detection model (USM-SCD) that can simultaneously detect speaker turns and perform ASR for 96 languages. This model is adapted from a speech foundation model trained on a large quantity of supervised and unsupervised data, demonstrating the utility of fine-tuning from a large generic foundation model for a downstream task. We analyze the performance of this multilingual speaker change detection model through a series of ablation studies. We show that the USM-SCD model can achieve more than 75% average speaker change detection F1 score across a test set that consists of data from 96 languages. On American English, the USM-SCD model can achieve an 85.8% speaker change detection F1 score across various public and internal test sets, beating the previous monolingual baseline model by 21% relative. We also show that we only need to fine-tune one-quarter of the trainable model parameters to achieve the best model performance. The USM-SCD model exhibits state-of-the-art ASR quality compared with a strong public ASR baseline, making it suitable to handle both tasks with negligible additional computational cost.
Conformers are All You Need for Visual Speech Recogntion
Feb 17, 2023



Visual speech recognition models extract visual features in a hierarchical manner. At the lower level, there is a visual front-end with a limited temporal receptive field that processes the raw pixels depicting the lips or faces. At the higher level, there is an encoder that attends to the embeddings produced by the front-end over a large temporal receptive field. Previous work has focused on improving the visual front-end of the model to extract more useful features for speech recognition. Surprisingly, our work shows that complex visual front-ends are not necessary. Instead of allocating resources to a sophisticated visual front-end, we find that a linear visual front-end paired with a larger Conformer encoder results in lower latency, more efficient memory usage, and improved WER performance. We achieve a new state-of-the-art of $12.8\%$ WER for visual speech recognition on the TED LRS3 dataset, which rivals the performance of audio-only models from just four years ago.
End-to-End Multi-Person Audio/Visual Automatic Speech Recognition
May 11, 2022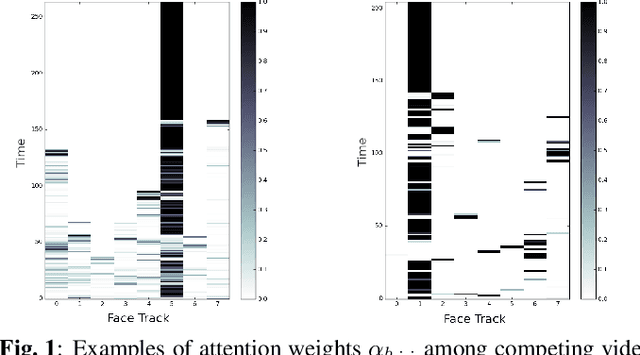

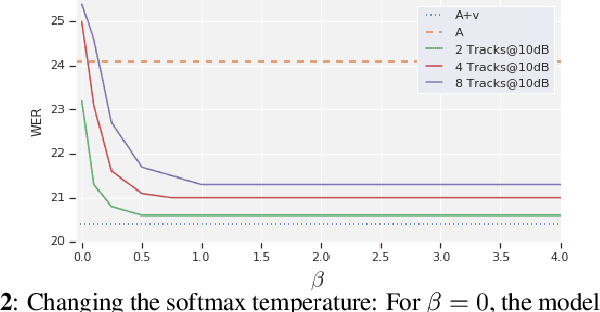
Traditionally, audio-visual automatic speech recognition has been studied under the assumption that the speaking face on the visual signal is the face matching the audio. However, in a more realistic setting, when multiple faces are potentially on screen one needs to decide which face to feed to the A/V ASR system. The present work takes the recent progress of A/V ASR one step further and considers the scenario where multiple people are simultaneously on screen (multi-person A/V ASR). We propose a fully differentiable A/V ASR model that is able to handle multiple face tracks in a video. Instead of relying on two separate models for speaker face selection and audio-visual ASR on a single face track, we introduce an attention layer to the ASR encoder that is able to soft-select the appropriate face video track. Experiments carried out on an A/V system trained on over 30k hours of YouTube videos illustrate that the proposed approach can automatically select the proper face tracks with minor WER degradation compared to an oracle selection of the speaking face while still showing benefits of employing the visual signal instead of the audio alone.
Recurrent Neural Network Transducer for Audio-Visual Speech Recognition
Nov 08, 2019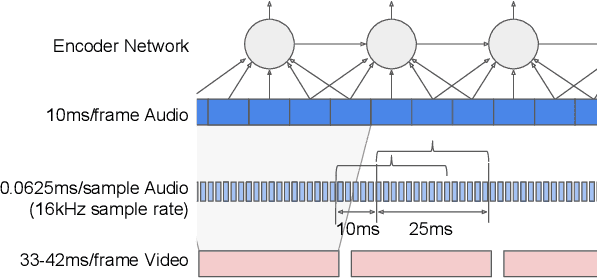
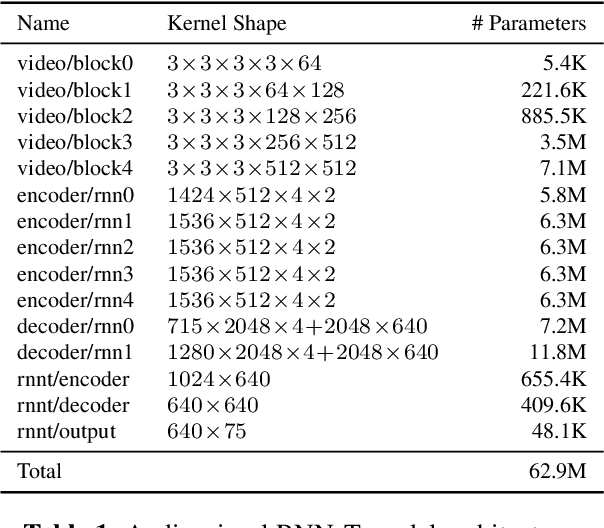
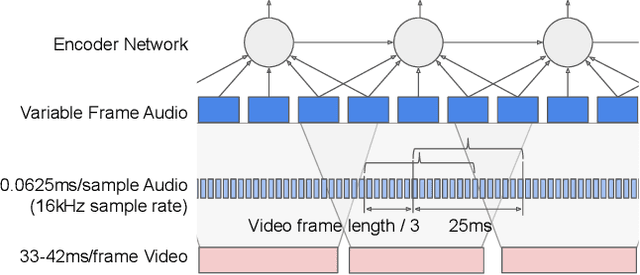

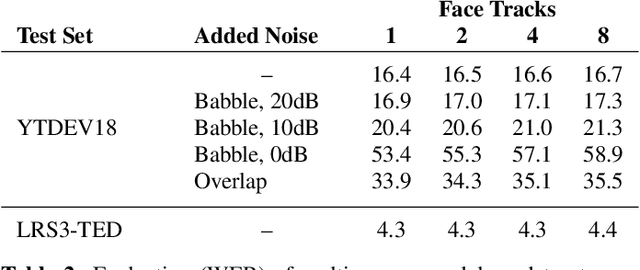
This work presents a large-scale audio-visual speech recognition system based on a recurrent neural network transducer (RNN-T) architecture. To support the development of such a system, we built a large audio-visual (A/V) dataset of segmented utterances extracted from YouTube public videos, leading to 31k hours of audio-visual training content. The performance of an audio-only, visual-only, and audio-visual system are compared on two large-vocabulary test sets: a set of utterance segments from public YouTube videos called YTDEV18 and the publicly available LRS3-TED set. To highlight the contribution of the visual modality, we also evaluated the performance of our system on the YTDEV18 set artificially corrupted with background noise and overlapping speech. To the best of our knowledge, our system significantly improves the state-of-the-art on the LRS3-TED set.
A comparison of end-to-end models for long-form speech recognition
Nov 06, 2019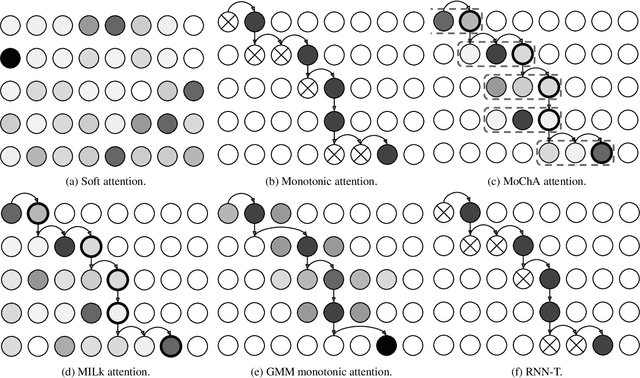

End-to-end automatic speech recognition (ASR) models, including both attention-based models and the recurrent neural network transducer (RNN-T), have shown superior performance compared to conventional systems. However, previous studies have focused primarily on short utterances that typically last for just a few seconds or, at most, a few tens of seconds. Whether such architectures are practical on long utterances that last from minutes to hours remains an open question. In this paper, we both investigate and improve the performance of end-to-end models on long-form transcription. We first present an empirical comparison of different end-to-end models on a real world long-form task and demonstrate that the RNN-T model is much more robust than attention-based systems in this regime. We next explore two improvements to attention-based systems that significantly improve its performance: restricting the attention to be monotonic, and applying a novel decoding algorithm that breaks long utterances into shorter overlapping segments. Combining these two improvements, we show that attention-based end-to-end models can be very competitive to RNN-T on long-form speech recognition.
Adversarial Training for Multilingual Acoustic Modeling
Jun 17, 2019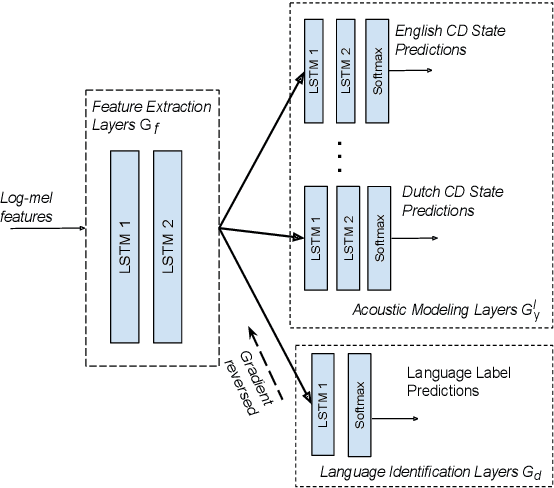
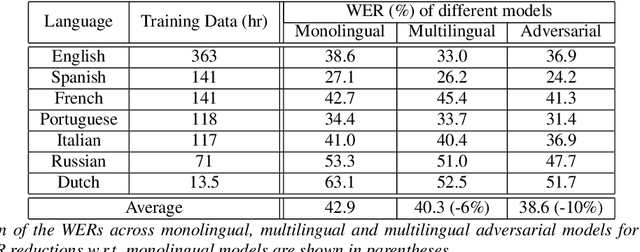
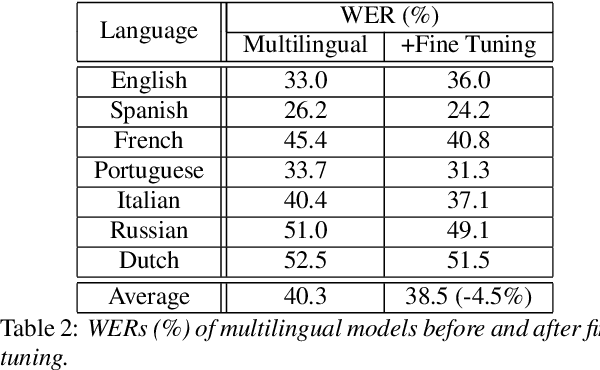
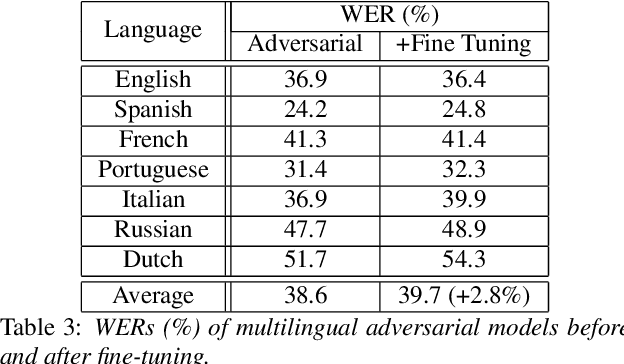
Multilingual training has been shown to improve acoustic modeling performance by sharing and transferring knowledge in modeling different languages. Knowledge sharing is usually achieved by using common lower-level layers for different languages in a deep neural network. Recently, the domain adversarial network was proposed to reduce domain mismatch of training data and learn domain-invariant features. It is thus worth exploring whether adversarial training can further promote knowledge sharing in multilingual models. In this work, we apply the domain adversarial network to encourage the shared layers of a multilingual model to learn language-invariant features. Bidirectional Long Short-Term Memory (LSTM) recurrent neural networks (RNN) are used as building blocks. We show that shared layers learned this way contain less language identification information and lead to better performance. In an automatic speech recognition task for seven languages, the resultant acoustic model improves the word error rate (WER) of the multilingual model by 4% relative on average, and the monolingual models by 10%.
Neural Language Modeling with Visual Features
Mar 07, 2019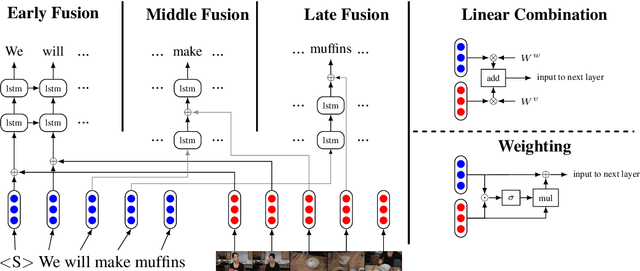
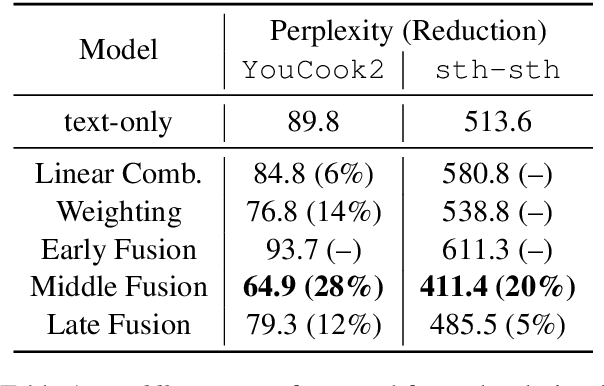
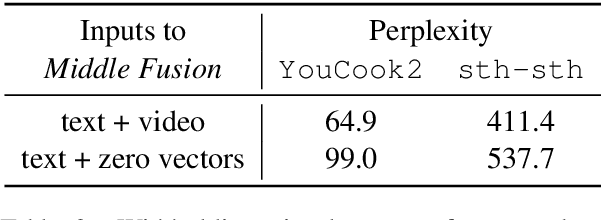
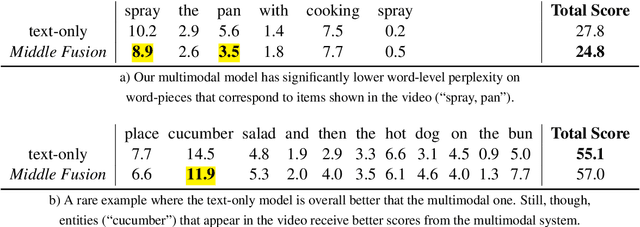
Multimodal language models attempt to incorporate non-linguistic features for the language modeling task. In this work, we extend a standard recurrent neural network (RNN) language model with features derived from videos. We train our models on data that is two orders-of-magnitude bigger than datasets used in prior work. We perform a thorough exploration of model architectures for combining visual and text features. Our experiments on two corpora (YouCookII and 20bn-something-something-v2) show that the best performing architecture consists of middle fusion of visual and text features, yielding over 25% relative improvement in perplexity. We report analysis that provides insights into why our multimodal language model improves upon a standard RNN language model.