 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfffcient Sensing Parameter Estimation with Direct Clutter Mitigation in Perceptive Mobile Networks
Jul 24, 2024



In this work, we investigate sensing parameter estimation in the presence of clutter in perceptive mobile networks (PMNs) that integrate radar sensing into mobile communications. Performing clutter suppression before sensing parameter estimation is generally desirable as the number of sensing parameters can be signiffcantly reduced. However, existing methods require high-complexity clutter mitigation and sensing parameter estimation, where clutter is ffrstly identiffed and then removed. In this correspondence, we propose a much simpler but more effective method by incorporating a clutter cancellation mechanism in formulating a sparse signal model for sensing parameter estimation. In particular, clutter mitigation is performed directly on the received signals and the unitary approximate message passing (UAMP) is leveraged to exploit the common support for sensing parameter estimation in the formulated sparse signal recovery problem. Simulation results show that, compared to state-of-theart methods, the proposed method delivers signiffcantly better performance while with substantially reduced complexity.
Transformer for Multitemporal Hyperspectral Image Unmixing
Jul 15, 2024



Multitemporal hyperspectral image unmixing (MTHU) holds significant importance in monitoring and analyzing the dynamic changes of surface. However, compared to single-temporal unmixing, the multitemporal approach demands comprehensive consideration of information across different phases, rendering it a greater challenge. To address this challenge, we propose the Multitemporal Hyperspectral Image Unmixing Transformer (MUFormer), an end-to-end unsupervised deep learning model. To effectively perform multitemporal hyperspectral image unmixing, we introduce two key modules: the Global Awareness Module (GAM) and the Change Enhancement Module (CEM). The Global Awareness Module computes self-attention across all phases, facilitating global weight allocation. On the other hand, the Change Enhancement Module dynamically learns local temporal changes by comparing endmember changes between adjacent phases. The synergy between these modules allows for capturing semantic information regarding endmember and abundance changes, thereby enhancing the effectiveness of multitemporal hyperspectral image unmixing. We conducted experiments on one real dataset and two synthetic datasets, demonstrating that our model significantly enhances the effect of multitemporal hyperspectral image unmixing.
Semantic Feature Division Multiple Access for Multi-user Digital Interference Networks
Jul 11, 2024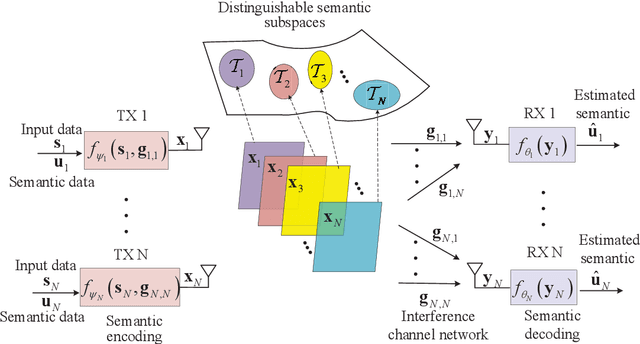


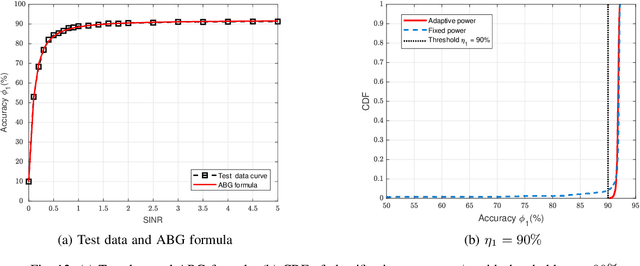
With the ever-increasing user density and quality of service (QoS) demand,5G networks with limited spectrum resources are facing massive access challenges. To address these challenges, in this paper, we propose a novel discrete semantic feature division multiple access (SFDMA) paradigm for multi-user digital interference networks. Specifically, by utilizing deep learning technology, SFDMA extracts multi-user semantic information into discrete representations in distinguishable semantic subspaces, which enables multiple users to transmit simultaneously over the same time-frequency resources. Furthermore, based on a robust information bottleneck, we design a SFDMA based multi-user digital semantic interference network for inference tasks, which can achieve approximate orthogonal transmission. Moreover, we propose a SFDMA based multi-user digital semantic interference network for image reconstruction tasks, where the discrete outputs of the semantic encoders of the users are approximately orthogonal, which significantly reduces multi-user interference. Furthermore, we propose an Alpha-Beta-Gamma (ABG) formula for semantic communications, which is the first theoretical relationship between inference accuracy and transmission power. Then, we derive adaptive power control methods with closed-form expressions for inference tasks. Extensive simulations verify the effectiveness and superiority of the proposed SFDMA.
Flight Structure Optimization of Modular Reconfigurable UAVs
Jul 04, 2024



This paper presents a Genetic Algorithm (GA) designed to reconfigure a large group of modular Unmanned Aerial Vehicles (UAVs), each with different weights and inertia parameters, into an over-actuated flight structure with improved dynamic properties. Previous research efforts either utilized expert knowledge to design flight structures for a specific task or relied on enumeration-based algorithms that required extensive computation to find an optimal one. However, both approaches encounter challenges in accommodating the heterogeneity among modules. Our GA addresses these challenges by incorporating the complexities of over-actuation and dynamic properties into its formulation. Additionally, we employ a tree representation and a vector representation to describe flight structures, facilitating efficient crossover operations and fitness evaluations within the GA framework, respectively. Using cubic modular quadcopters capable of functioning as omni-directional thrust generators, we validate that the proposed approach can (i) adeptly identify suboptimal configurations ensuring over-actuation while ensuring trajectory tracking accuracy and (ii) significantly reduce computational costs compared to traditional enumeration-based methods.
Language-Guided Object-Centric Diffusion Policy for Collision-Aware Robotic Manipulation
Jun 29, 2024Learning from demonstrations faces challenges in generalizing beyond the training data and is fragile even to slight visual variations. To tackle this problem, we introduce Lan-o3dp, a language guided object centric diffusion policy that takes 3d representation of task relevant objects as conditional input and can be guided by cost function for safety constraints at inference time. Lan-o3dp enables strong generalization in various aspects, such as background changes, visual ambiguity and can avoid novel obstacles that are unseen during the demonstration process. Specifically, We first train a diffusion policy conditioned on point clouds of target objects and then harness a large language model to decompose the user instruction into task related units consisting of target objects and obstacles, which can be used as visual observation for the policy network or converted to a cost function, guiding the generation of trajectory towards collision free region at test time. Our proposed method shows training efficiency and higher success rates compared with the baselines in simulation experiments. In real world experiments, our method exhibits strong generalization performance towards unseen instances, cluttered scenes, scenes of multiple similar objects and demonstrates training free capability of obstacle avoidance.
Knowledge Tagging System on Math Questions via LLMs with Flexible Demonstration Retriever
Jun 19, 2024



Knowledge tagging for questions plays a crucial role in contemporary intelligent educational applications, including learning progress diagnosis, practice question recommendations, and course content organization. Traditionally, these annotations are always conducted by pedagogical experts, as the task requires not only a strong semantic understanding of both question stems and knowledge definitions but also deep insights into connecting question-solving logic with corresponding knowledge concepts. With the recent emergence of advanced text encoding algorithms, such as pre-trained language models, many researchers have developed automatic knowledge tagging systems based on calculating the semantic similarity between the knowledge and question embeddings. In this paper, we explore automating the task using Large Language Models (LLMs), in response to the inability of prior encoding-based methods to deal with the hard cases which involve strong domain knowledge and complicated concept definitions. By showing the strong performance of zero- and few-shot results over math questions knowledge tagging tasks, we demonstrate LLMs' great potential in conquering the challenges faced by prior methods. Furthermore, by proposing a reinforcement learning-based demonstration retriever, we successfully exploit the great potential of different-sized LLMs in achieving better performance results while keeping the in-context demonstration usage efficiency high.
Toward Optimal LLM Alignments Using Two-Player Games
Jun 16, 2024



The standard Reinforcement Learning from Human Feedback (RLHF) framework primarily focuses on optimizing the performance of large language models using pre-collected prompts. However, collecting prompts that provide comprehensive coverage is both tedious and challenging, and often fails to include scenarios that LLMs need to improve on the most. In this paper, we investigate alignment through the lens of two-agent games, involving iterative interactions between an adversarial and a defensive agent. The adversarial agent's task at each step is to generate prompts that expose the weakness of the defensive agent. In return, the defensive agent seeks to improve its responses to these newly identified prompts it struggled with, based on feedback from the reward model. We theoretically demonstrate that this iterative reinforcement learning optimization converges to a Nash Equilibrium for the game induced by the agents. Experimental results in safety scenarios demonstrate that learning in such a competitive environment not only fully trains agents but also leads to policies with enhanced generalization capabilities for both adversarial and defensive agents.
Evaluating Uncertainty-based Failure Detection for Closed-Loop LLM Planners
Jun 01, 2024Recently, Large Language Models (LLMs) have witnessed remarkable performance as zero-shot task planners for robotic manipulation tasks. However, the open-loop nature of previous works makes LLM-based planning error-prone and fragile. On the other hand, failure detection approaches for closed-loop planning are often limited by task-specific heuristics or following an unrealistic assumption that the prediction is trustworthy all the time. As a general-purpose reasoning machine, LLMs or Multimodal Large Language Models (MLLMs) are promising for detecting failures. However, However, the appropriateness of the aforementioned assumption diminishes due to the notorious hullucination problem. In this work, we attempt to mitigate these issues by introducing a framework for closed-loop LLM-based planning called KnowLoop, backed by an uncertainty-based MLLMs failure detector, which is agnostic to any used MLLMs or LLMs. Specifically, we evaluate three different ways for quantifying the uncertainty of MLLMs, namely token probability, entropy, and self-explained confidence as primary metrics based on three carefully designed representative prompting strategies. With a self-collected dataset including various manipulation tasks and an LLM-based robot system, our experiments demonstrate that token probability and entropy are more reflective compared to self-explained confidence. By setting an appropriate threshold to filter out uncertain predictions and seek human help actively, the accuracy of failure detection can be significantly enhanced. This improvement boosts the effectiveness of closed-loop planning and the overall success rate of tasks.
AGILE: A Novel Framework of LLM Agents
May 23, 2024



We introduce a novel framework of LLM agents named AGILE (AGent that Interacts and Learns from Environments) designed to perform complex conversational tasks with users, leveraging LLMs, memory, tools, and interactions with experts. The agent's abilities include not only conversation but also reflection, utilization of tools, and consultation with experts. We formulate the construction of such an LLM agent as a reinforcement learning problem, in which the LLM serves as the policy model. We fine-tune the LLM using labeled data of actions and the PPO algorithm. We focus on question answering and release a dataset for agents called ProductQA, comprising challenging questions in online shopping. Our extensive experiments on ProductQA and MedMCQA show that AGILE agents based on 13B and 7B LLMs trained with PPO can outperform GPT-4 agents. Our ablation study highlights the indispensability of memory, tools, consultation, reflection, and reinforcement learning in achieving the agent's strong performance.
Large Language Models for Education: A Survey and Outlook
Apr 01, 2024

The advent of Large Language Models (LLMs) has brought in a new era of possibilities in the realm of education. This survey paper summarizes the various technologies of LLMs in educational settings from multifaceted perspectives, encompassing student and teacher assistance, adaptive learning, and commercial tools. We systematically review the technological advancements in each perspective, organize related datasets and benchmarks, and identify the risks and challenges associated with deploying LLMs in education. Furthermore, we outline future research opportunities, highlighting the potential promising directions. Our survey aims to provide a comprehensive technological picture for educators, researchers, and policymakers to harness the power of LLMs to revolutionize educational practices and foster a more effective personalized learning environment.