 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovert Beamforming Design for Integrated Radar Sensing and Communication Systems
Aug 11, 2022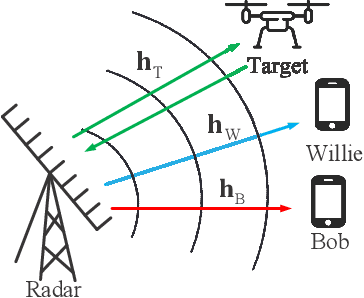
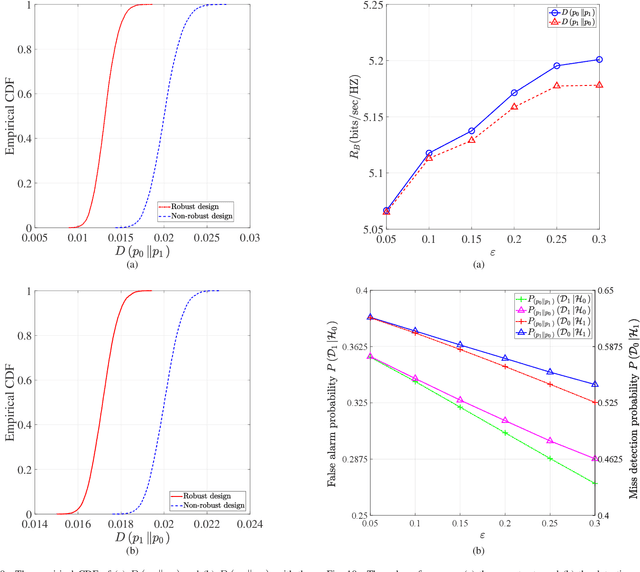
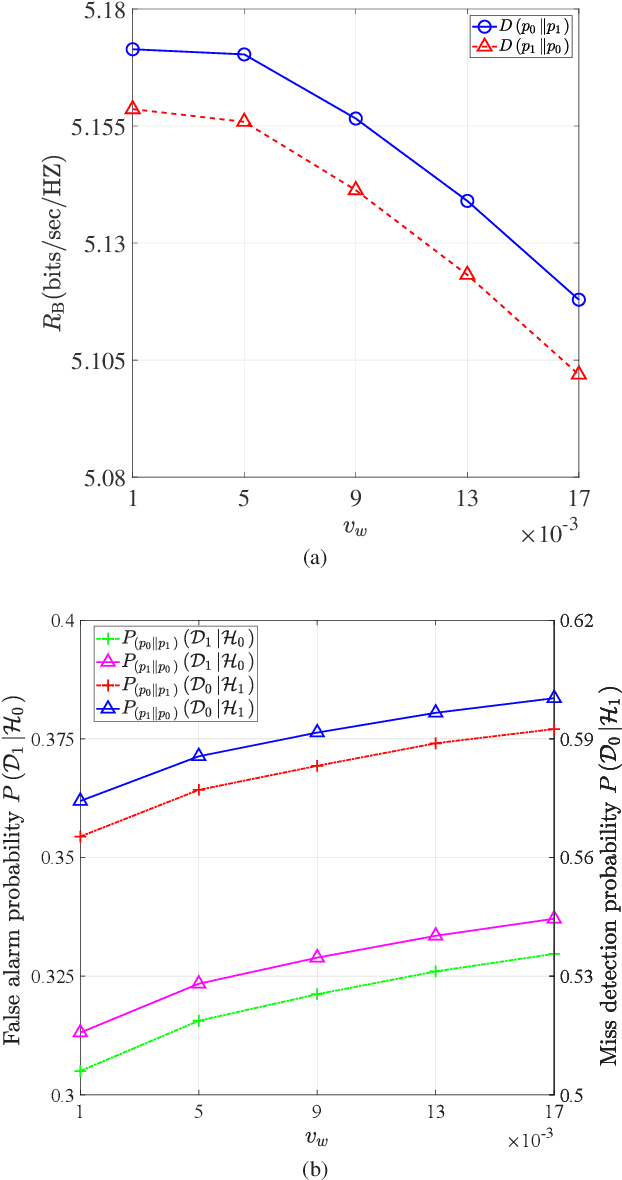
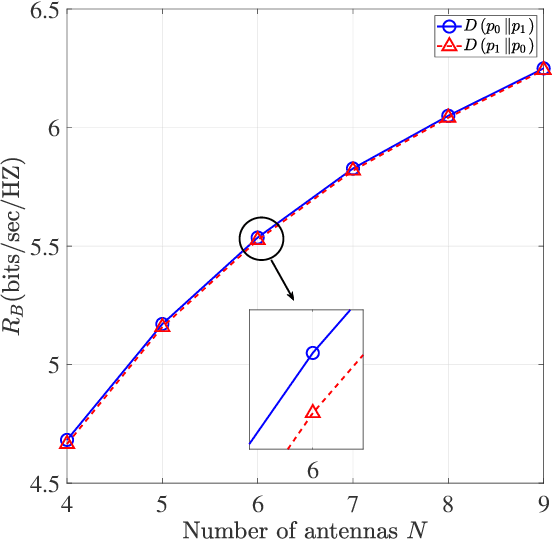
We propose covert beamforming design frameworks for integrated radar sensing and communication (IRSC) systems, where the radar can covertly communicate with legitimate users under the cover of the probing waveforms without being detected by the eavesdropper. Specifically, by jointly designing the target detection beamformer and communication beamformer, we aim to maximize the radar detection mutual information (MI) (or the communication rate) subject to the covert constraint, the communication rate constraint (or the radar detection MI constraint), and the total power constraint. For the perfect eavesdropper's channel state information (CSI) scenario, we transform the covert beamforming design problems into a series of convex subproblems, by exploiting semidefinite relaxation, which can be solved via the bisection search method. Considering the high complexity of iterative optimization, we further propose a single-iterative covert beamformer design scheme based on the zero-forcing criterion. For the imperfect eavesdropper's CSI scenario, we develop a relaxation and restriction method to tackle the robust covert beamforming design problems. Simulation results demonstrate the effectiveness of the proposed covert beamforming schemes for perfect and imperfect CSI scenarios.
Biologically Inspired Neural Path Finding
Jun 13, 2022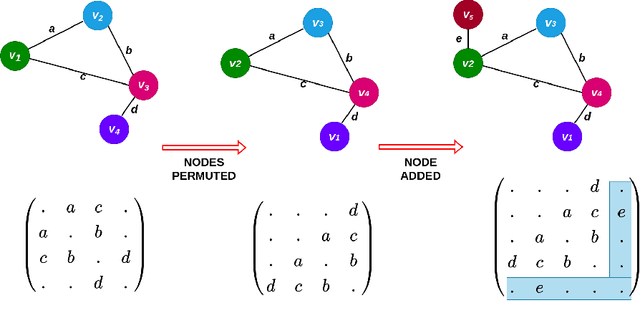
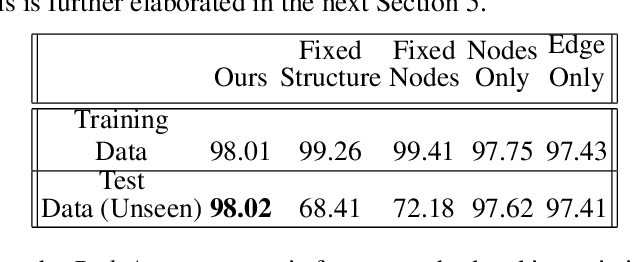
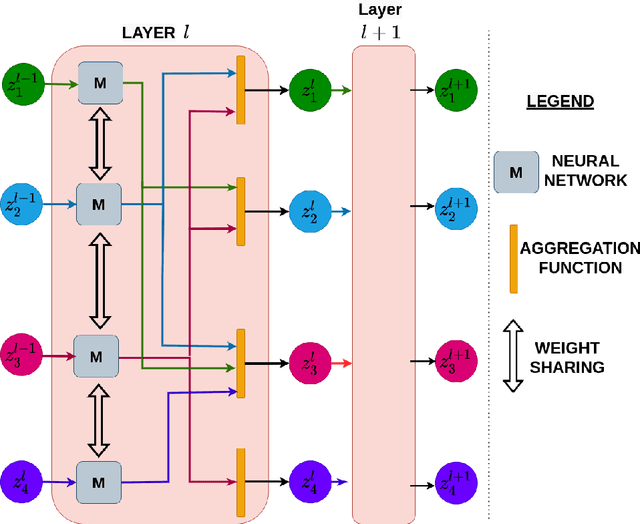
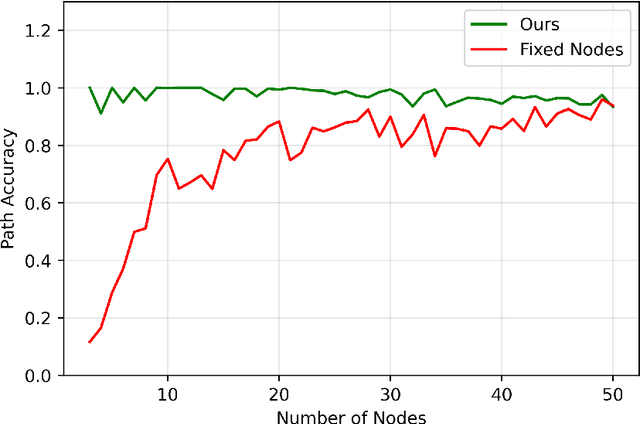
The human brain can be considered to be a graphical structure comprising of tens of billions of biological neurons connected by synapses. It has the remarkable ability to automatically re-route information flow through alternate paths in case some neurons are damaged. Moreover, the brain is capable of retaining information and applying it to similar but completely unseen scenarios. In this paper, we take inspiration from these attributes of the brain, to develop a computational framework to find the optimal low cost path between a source node and a destination node in a generalized graph. We show that our framework is capable of handling unseen graphs at test time. Moreover, it can find alternate optimal paths, when nodes are arbitrarily added or removed during inference, while maintaining a fixed prediction time. Code is available here: https://github.com/hangligit/pathfinding
On Calibration of Graph Neural Networks for Node Classification
Jun 03, 2022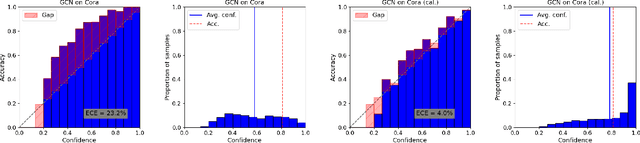
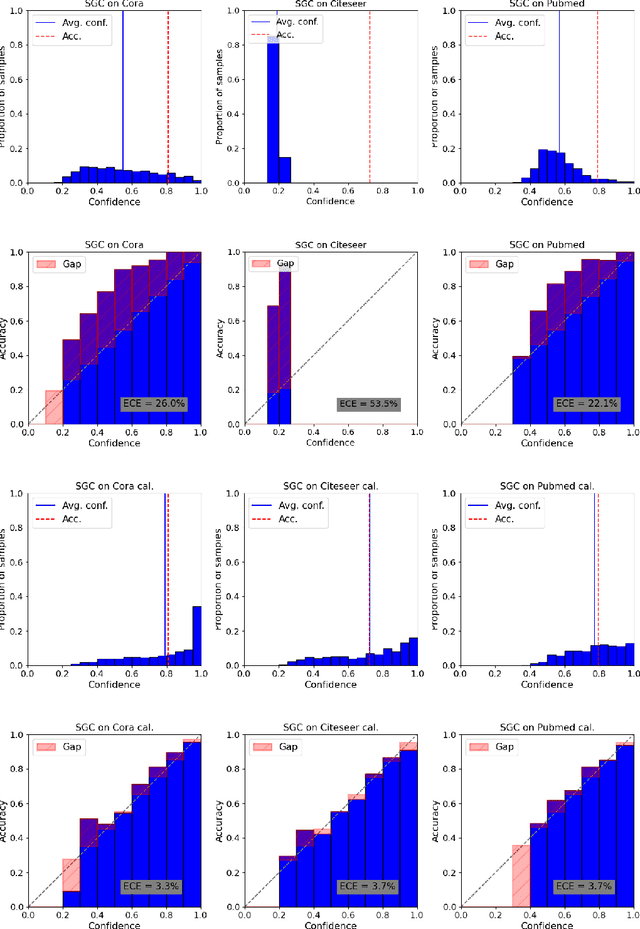
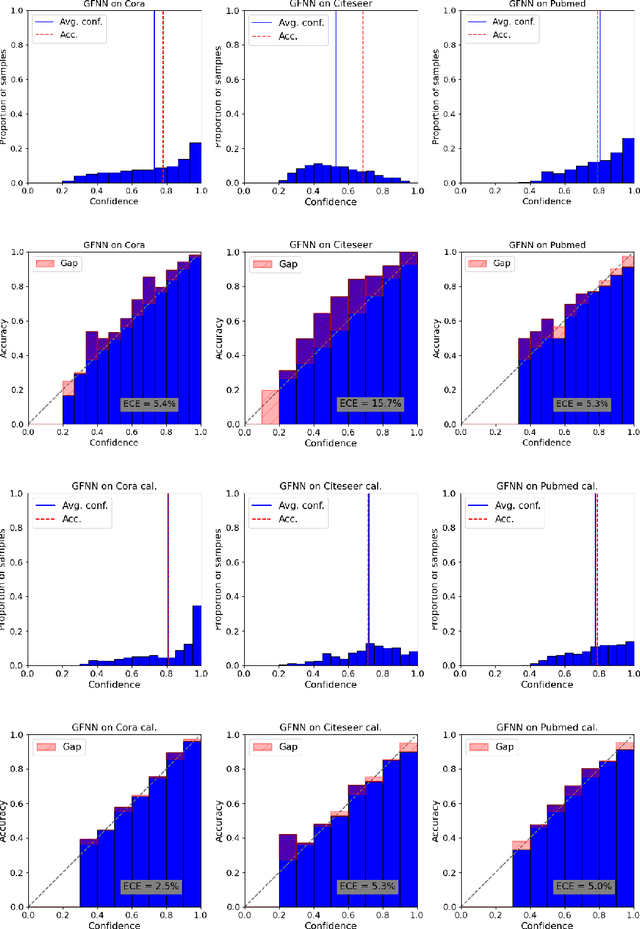
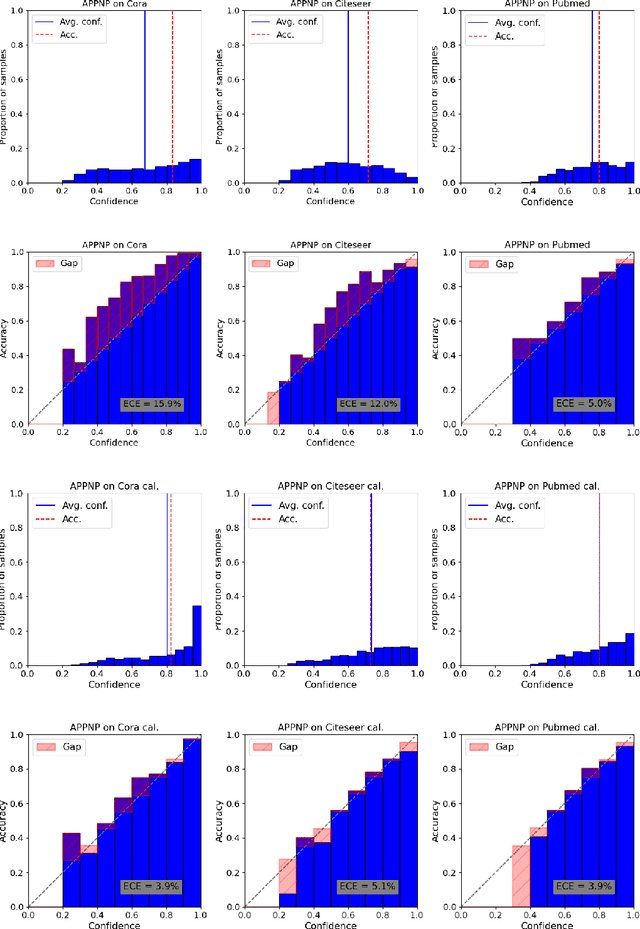
Graphs can model real-world, complex systems by representing entities and their interactions in terms of nodes and edges. To better exploit the graph structure, graph neural networks have been developed, which learn entity and edge embeddings for tasks such as node classification and link prediction. These models achieve good performance with respect to accuracy, but the confidence scores associated with the predictions might not be calibrated. That means that the scores might not reflect the ground-truth probabilities of the predicted events, which would be especially important for safety-critical applications. Even though graph neural networks are used for a wide range of tasks, the calibration thereof has not been sufficiently explored yet. We investigate the calibration of graph neural networks for node classification, study the effect of existing post-processing calibration methods, and analyze the influence of model capacity, graph density, and a new loss function on calibration. Further, we propose a topology-aware calibration method that takes the neighboring nodes into account and yields improved calibration compared to baseline methods.
Directed Acyclic Transformer for Non-Autoregressive Machine Translation
May 16, 2022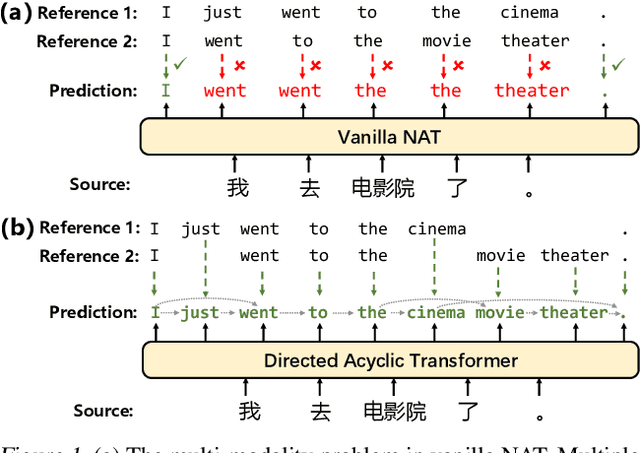
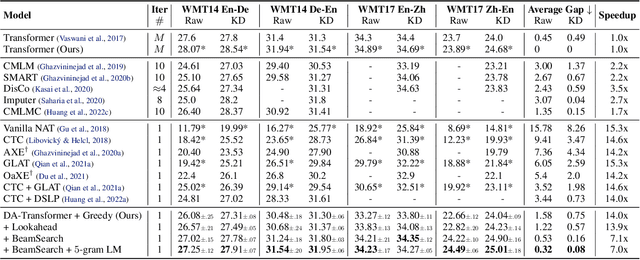
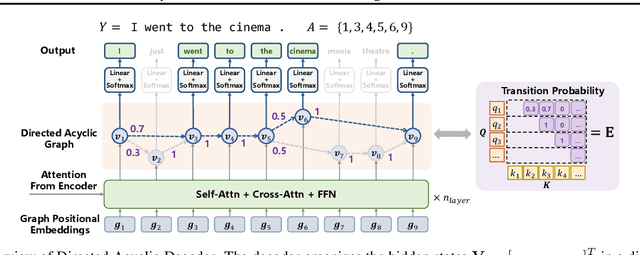
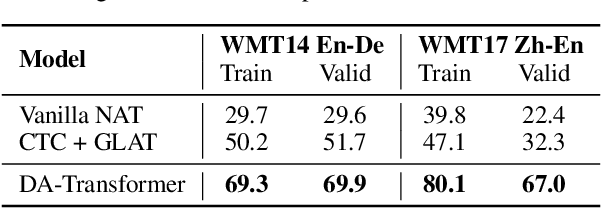
Non-autoregressive Transformers (NATs) significantly reduce the decoding latency by generating all tokens in parallel. However, such independent predictions prevent NATs from capturing the dependencies between the tokens for generating multiple possible translations. In this paper, we propose Directed Acyclic Transfomer (DA-Transformer), which represents the hidden states in a Directed Acyclic Graph (DAG), where each path of the DAG corresponds to a specific translation. The whole DAG simultaneously captures multiple translations and facilitates fast predictions in a non-autoregressive fashion. Experiments on the raw training data of WMT benchmark show that DA-Transformer substantially outperforms previous NATs by about 3 BLEU on average, which is the first NAT model that achieves competitive results with autoregressive Transformers without relying on knowledge distillation.
How does Feedback Signal Quality Impact Effectiveness of Pseudo Relevance Feedback for Passage Retrieval?
May 12, 2022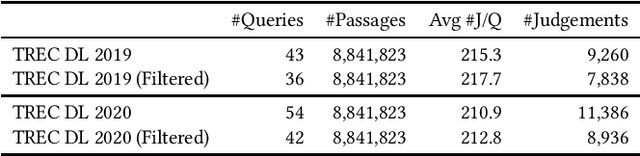
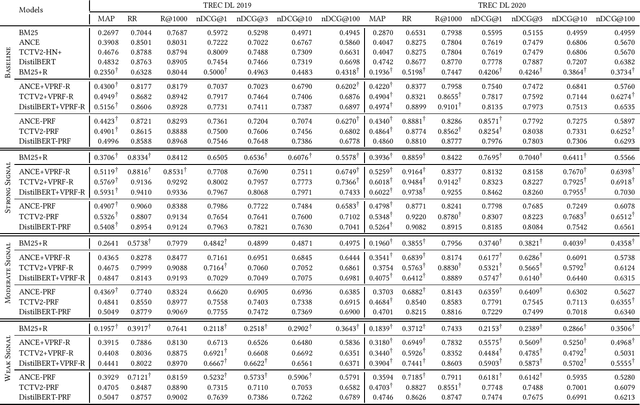
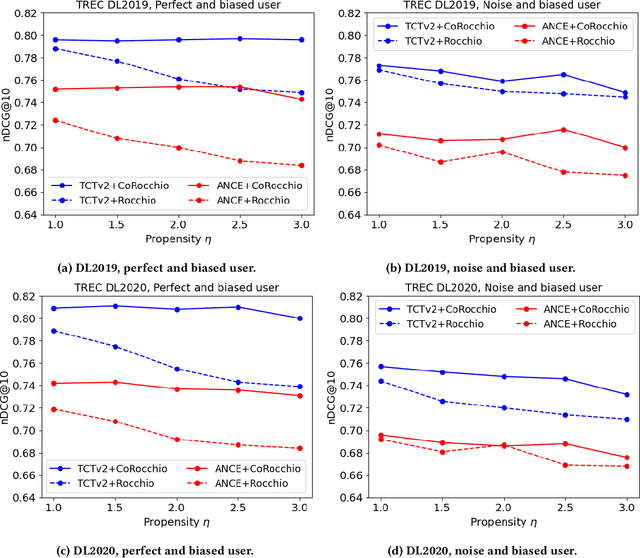
Pseudo-Relevance Feedback (PRF) assumes that the top results retrieved by a first-stage ranker are relevant to the original query and uses them to improve the query representation for a second round of retrieval. This assumption however is often not correct: some or even all of the feedback documents may be irrelevant. Indeed, the effectiveness of PRF methods may well depend on the quality of the feedback signal and thus on the effectiveness of the first-stage ranker. This aspect however has received little attention before. In this paper we control the quality of the feedback signal and measure its impact on a range of PRF methods, including traditional bag-of-words methods (Rocchio), and dense vector-based methods (learnt and not learnt). Our results show the important role the quality of the feedback signal plays on the effectiveness of PRF methods. Importantly, and surprisingly, our analysis reveals that not all PRF methods are the same when dealing with feedback signals of varying quality. These findings are critical to gain a better understanding of the PRF methods and of which and when they should be used, depending on the feedback signal quality, and set the basis for future research in this area.
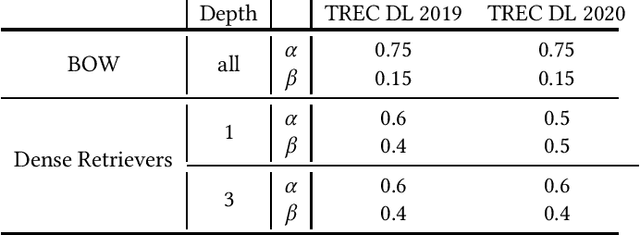
To Interpolate or not to Interpolate: PRF, Dense and Sparse Retrievers
Apr 30, 2022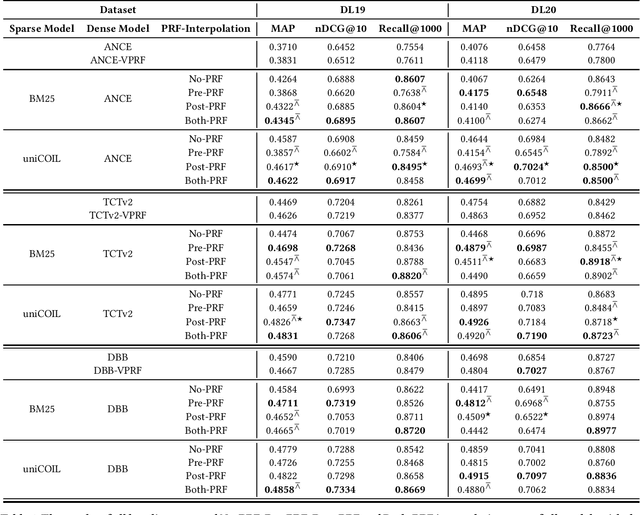
Current pre-trained language model approaches to information retrieval can be broadly divided into two categories: sparse retrievers (to which belong also non-neural approaches such as bag-of-words methods, e.g., BM25) and dense retrievers. Each of these categories appears to capture different characteristics of relevance. Previous work has investigated how relevance signals from sparse retrievers could be combined with those from dense retrievers via interpolation. Such interpolation would generally lead to higher retrieval effectiveness. In this paper we consider the problem of combining the relevance signals from sparse and dense retrievers in the context of Pseudo Relevance Feedback (PRF). This context poses two key challenges: (1) When should interpolation occur: before, after, or both before and after the PRF process? (2) Which sparse representation should be considered: a zero-shot bag-of-words model (BM25), or a learnt sparse representation? To answer these questions we perform a thorough empirical evaluation considering an effective and scalable neural PRF approach (Vector-PRF), three effective dense retrievers (ANCE, TCTv2, DistillBERT), and one state-of-the-art learnt sparse retriever (uniCOIL). The empirical findings from our experiments suggest that, regardless of sparse representation and dense retriever, interpolation both before and after PRF achieves the highest effectiveness across most datasets and metrics.
Self-Supervised Audio-and-Text Pre-training with Extremely Low-Resource Parallel Data
Apr 10, 2022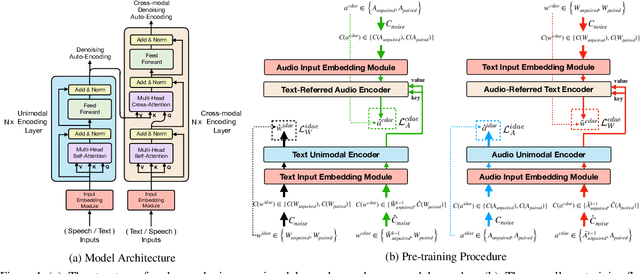
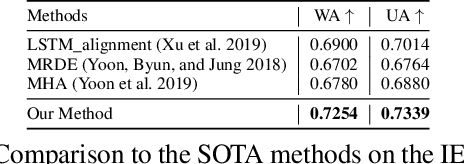
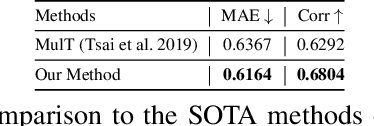
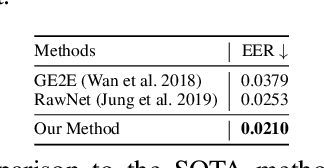
Multimodal pre-training for audio-and-text has recently been proved to be effective and has significantly improved the performance of many downstream speech understanding tasks. However, these state-of-the-art pre-training audio-text models work well only when provided with large amount of parallel audio-and-text data, which brings challenges on many languages that are rich in unimodal corpora but scarce of parallel cross-modal corpus. In this paper, we investigate whether it is possible to pre-train an audio-text multimodal model with extremely low-resource parallel data and extra non-parallel unimodal data. Our pre-training framework consists of the following components: (1) Intra-modal Denoising Auto-Encoding (IDAE), which is able to reconstruct input text (audio) representations from a noisy version of itself. (2) Cross-modal Denoising Auto-Encoding (CDAE), which is pre-trained to reconstruct the input text (audio), given both a noisy version of the input text (audio) and the corresponding translated noisy audio features (text embeddings). (3) Iterative Denoising Process (IDP), which iteratively translates raw audio (text) and the corresponding text embeddings (audio features) translated from previous iteration into the new less-noisy text embeddings (audio features). We adapt a dual cross-modal Transformer as our backbone model which consists of two unimodal encoders for IDAE and two cross-modal encoders for CDAE and IDP. Our method achieves comparable performance on multiple downstream speech understanding tasks compared with the model pre-trained on fully parallel data, demonstrating the great potential of the proposed method. Our code is available at: \url{https://github.com/KarlYuKang/Low-Resource-Multimodal-Pre-training}.
Implicit Feedback for Dense Passage Retrieval: A Counterfactual Approach
Apr 01, 2022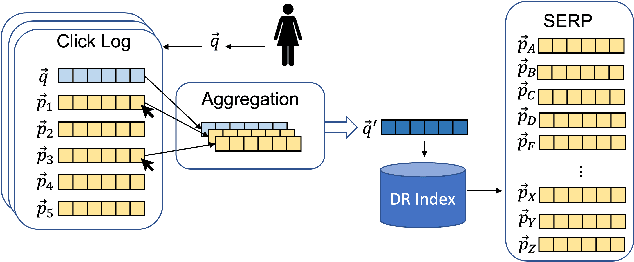


In this paper we study how to effectively exploit implicit feedback in Dense Retrievers (DRs). We consider the specific case in which click data from a historic click log is available as implicit feedback. We then exploit such historic implicit interactions to improve the effectiveness of a DR. A key challenge that we study is the effect that biases in the click signal, such as position bias, have on the DRs. To overcome the problems associated with the presence of such bias, we propose the Counterfactual Rocchio (CoRocchio) algorithm for exploiting implicit feedback in Dense Retrievers. We demonstrate both theoretically and empirically that dense query representations learnt with CoRocchio are unbiased with respect to position bias and lead to higher retrieval effectiveness.
A Neural-Symbolic Approach to Natural Language Understanding
Mar 20, 2022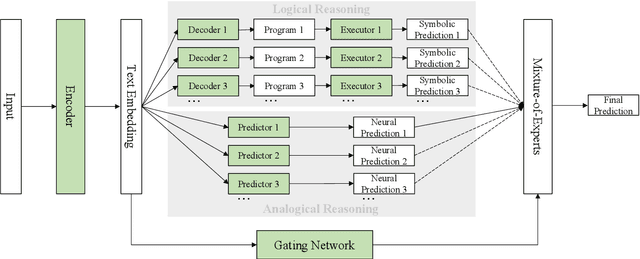


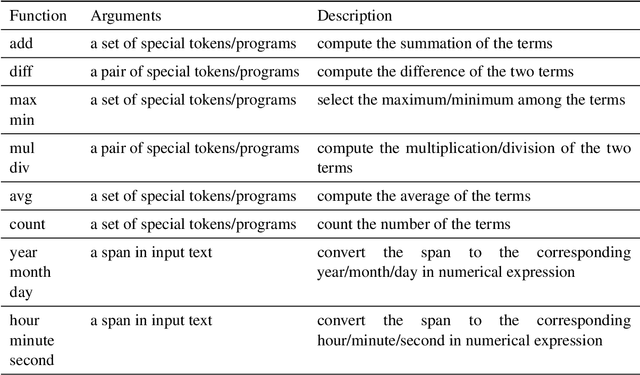
Deep neural networks, empowered by pre-trained language models, have achieved remarkable results in natural language understanding (NLU) tasks. However, their performances can deteriorate drastically when logical reasoning is needed in the process. This is because, ideally, NLU needs to depend on not only analogical reasoning, which deep neural networks are good at, but also logical reasoning. According to the dual-process theory, analogical reasoning and logical reasoning are respectively carried out by System 1 and System 2 in the human brain. Inspired by the theory, we present a novel framework for NLU called Neural-Symbolic Processor (NSP), which performs analogical reasoning based on neural processing and performs logical reasoning based on both neural and symbolic processing. As a case study, we conduct experiments on two NLU tasks, question answering (QA) and natural language inference (NLI), when numerical reasoning (a type of logical reasoning) is necessary. The experimental results show that our method significantly outperforms state-of-the-art methods in both tasks.
Counterfactually Evaluating Explanations in Recommender Systems
Mar 02, 2022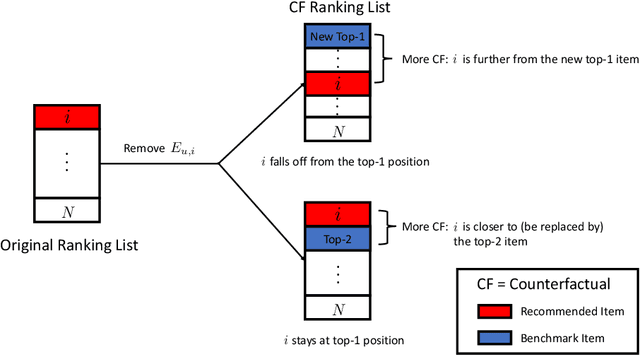

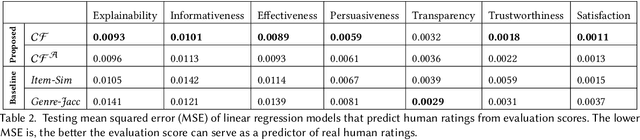
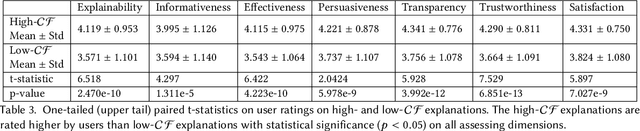
Modern recommender systems face an increasing need to explain their recommendations. Despite considerable progress in this area, evaluating the quality of explanations remains a significant challenge for researchers and practitioners. Prior work mainly conducts human study to evaluate explanation quality, which is usually expensive, time-consuming, and prone to human bias. In this paper, we propose an offline evaluation method that can be computed without human involvement. To evaluate an explanation, our method quantifies its counterfactual impact on the recommendation. To validate the effectiveness of our method, we carry out an online user study. We show that, compared to conventional methods, our method can produce evaluation scores more correlated with the real human judgments, and therefore can serve as a better proxy for human evaluation. In addition, we show that explanations with high evaluation scores are considered better by humans. Our findings highlight the promising direction of using the counterfactual approach as one possible way to evaluate recommendation explanations.