 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Foundation Model for Dental Caries Detection with Dual-View Co-Training
Aug 28, 2025



Accurate dental caries detection from panoramic X-rays plays a pivotal role in preventing lesion progression. However, current detection methods often yield suboptimal accuracy due to subtle contrast variations and diverse lesion morphology of dental caries. In this work, inspired by the clinical workflow where dentists systematically combine whole-image screening with detailed tooth-level inspection, we present DVCTNet, a novel Dual-View Co-Training network for accurate dental caries detection. Our DVCTNet starts with employing automated tooth detection to establish two complementary views: a global view from panoramic X-ray images and a local view from cropped tooth images. We then pretrain two vision foundation models separately on the two views. The global-view foundation model serves as the detection backbone, generating region proposals and global features, while the local-view model extracts detailed features from corresponding cropped tooth patches matched by the region proposals. To effectively integrate information from both views, we introduce a Gated Cross-View Attention (GCV-Atten) module that dynamically fuses dual-view features, enhancing the detection pipeline by integrating the fused features back into the detection model for final caries detection. To rigorously evaluate our DVCTNet, we test it on a public dataset and further validate its performance on a newly curated, high-precision dental caries detection dataset, annotated using both intra-oral images and panoramic X-rays for double verification. Experimental results demonstrate DVCTNet's superior performance against existing state-of-the-art (SOTA) methods on both datasets, indicating the clinical applicability of our method. Our code and labeled dataset are available at https://github.com/ShanghaiTech-IMPACT/DVCTNet.
AFABench: A Generic Framework for Benchmarking Active Feature Acquisition
Aug 20, 2025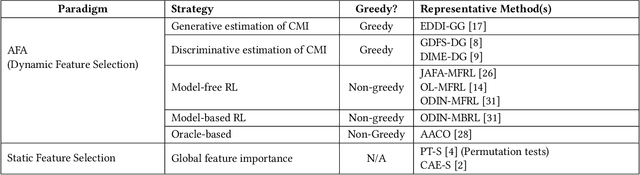
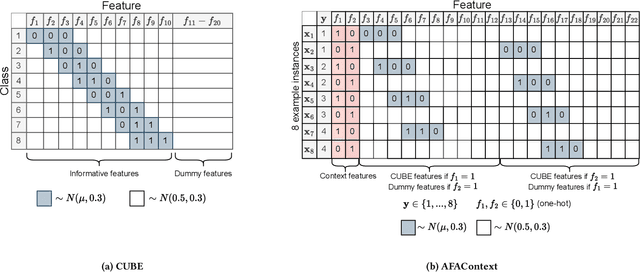
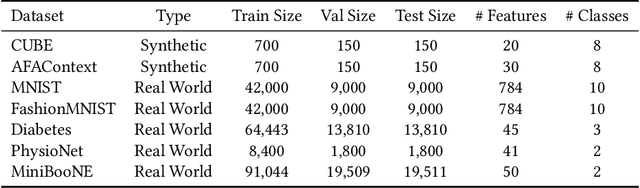
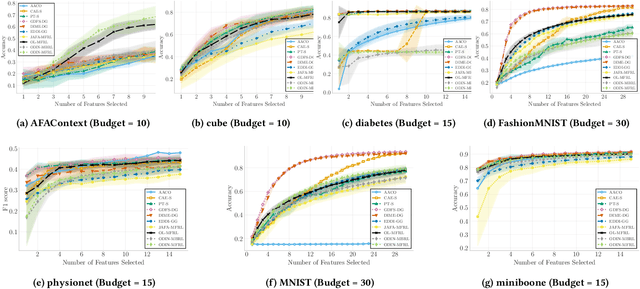
In many real-world scenarios, acquiring all features of a data instance can be expensive or impractical due to monetary cost, latency, or privacy concerns. Active Feature Acquisition (AFA) addresses this challenge by dynamically selecting a subset of informative features for each data instance, trading predictive performance against acquisition cost. While numerous methods have been proposed for AFA, ranging from greedy information-theoretic strategies to non-myopic reinforcement learning approaches, fair and systematic evaluation of these methods has been hindered by the lack of standardized benchmarks. In this paper, we introduce AFABench, the first benchmark framework for AFA. Our benchmark includes a diverse set of synthetic and real-world datasets, supports a wide range of acquisition policies, and provides a modular design that enables easy integration of new methods and tasks. We implement and evaluate representative algorithms from all major categories, including static, greedy, and reinforcement learning-based approaches. To test the lookahead capabilities of AFA policies, we introduce a novel synthetic dataset, AFAContext, designed to expose the limitations of greedy selection. Our results highlight key trade-offs between different AFA strategies and provide actionable insights for future research. The benchmark code is available at: https://github.com/Linusaronsson/AFA-Benchmark.
LoViC: Efficient Long Video Generation with Context Compression
Jul 17, 2025



Despite recent advances in diffusion transformers (DiTs) for text-to-video generation, scaling to long-duration content remains challenging due to the quadratic complexity of self-attention. While prior efforts -- such as sparse attention and temporally autoregressive models -- offer partial relief, they often compromise temporal coherence or scalability. We introduce LoViC, a DiT-based framework trained on million-scale open-domain videos, designed to produce long, coherent videos through a segment-wise generation process. At the core of our approach is FlexFormer, an expressive autoencoder that jointly compresses video and text into unified latent representations. It supports variable-length inputs with linearly adjustable compression rates, enabled by a single query token design based on the Q-Former architecture. Additionally, by encoding temporal context through position-aware mechanisms, our model seamlessly supports prediction, retradiction, interpolation, and multi-shot generation within a unified paradigm. Extensive experiments across diverse tasks validate the effectiveness and versatility of our approach.
One-shot Face Sketch Synthesis in the Wild via Generative Diffusion Prior and Instruction Tuning
Jun 18, 2025



Face sketch synthesis is a technique aimed at converting face photos into sketches. Existing face sketch synthesis research mainly relies on training with numerous photo-sketch sample pairs from existing datasets. However, these large-scale discriminative learning methods will have to face problems such as data scarcity and high human labor costs. Once the training data becomes scarce, their generative performance significantly degrades. In this paper, we propose a one-shot face sketch synthesis method based on diffusion models. We optimize text instructions on a diffusion model using face photo-sketch image pairs. Then, the instructions derived through gradient-based optimization are used for inference. To simulate real-world scenarios more accurately and evaluate method effectiveness more comprehensively, we introduce a new benchmark named One-shot Face Sketch Dataset (OS-Sketch). The benchmark consists of 400 pairs of face photo-sketch images, including sketches with different styles and photos with different backgrounds, ages, sexes, expressions, illumination, etc. For a solid out-of-distribution evaluation, we select only one pair of images for training at each time, with the rest used for inference. Extensive experiments demonstrate that the proposed method can convert various photos into realistic and highly consistent sketches in a one-shot context. Compared to other methods, our approach offers greater convenience and broader applicability. The dataset will be available at: https://github.com/HanWu3125/OS-Sketch
Application-Driven Value Alignment in Agentic AI Systems: Survey and Perspectives
Jun 11, 2025



The ongoing evolution of AI paradigms has propelled AI research into the Agentic AI stage. Consequently, the focus of research has shifted from single agents and simple applications towards multi-agent autonomous decision-making and task collaboration in complex environments. As Large Language Models (LLMs) advance, their applications become more diverse and complex, leading to increasingly situational and systemic risks. This has brought significant attention to value alignment for AI agents, which aims to ensure that an agent's goals, preferences, and behaviors align with human values and societal norms. This paper reviews value alignment in agent systems within specific application scenarios. It integrates the advancements in AI driven by large models with the demands of social governance. Our review covers value principles, agent system application scenarios, and agent value alignment evaluation. Specifically, value principles are organized hierarchically from a top-down perspective, encompassing macro, meso, and micro levels. Agent system application scenarios are categorized and reviewed from a general-to-specific viewpoint. Agent value alignment evaluation systematically examines datasets for value alignment assessment and relevant value alignment methods. Additionally, we delve into value coordination among multiple agents within agent systems. Finally, we propose several potential research directions in this field.
Activation-Guided Consensus Merging for Large Language Models
May 20, 2025Recent research has increasingly focused on reconciling the reasoning capabilities of System 2 with the efficiency of System 1. While existing training-based and prompt-based approaches face significant challenges in terms of efficiency and stability, model merging emerges as a promising strategy to integrate the diverse capabilities of different Large Language Models (LLMs) into a unified model. However, conventional model merging methods often assume uniform importance across layers, overlooking the functional heterogeneity inherent in neural components. To address this limitation, we propose \textbf{A}ctivation-Guided \textbf{C}onsensus \textbf{M}erging (\textbf{ACM}), a plug-and-play merging framework that determines layer-specific merging coefficients based on mutual information between activations of pre-trained and fine-tuned models. ACM effectively preserves task-specific capabilities without requiring gradient computations or additional training. Extensive experiments on Long-to-Short (L2S) and general merging tasks demonstrate that ACM consistently outperforms all baseline methods. For instance, in the case of Qwen-7B models, TIES-Merging equipped with ACM achieves a \textbf{55.3\%} reduction in response length while simultaneously improving reasoning accuracy by \textbf{1.3} points. We submit the code with the paper for reproducibility, and it will be publicly available.
Prompted Meta-Learning for Few-shot Knowledge Graph Completion
May 08, 2025



Few-shot knowledge graph completion (KGC) has obtained significant attention due to its practical applications in real-world scenarios, where new knowledge often emerges with limited available data. While most existing methods for few-shot KGC have predominantly focused on leveraging relational information, rich semantics inherent in KGs have been largely overlooked. To address this gap, we propose a novel prompted meta-learning (PromptMeta) framework that seamlessly integrates meta-semantics with relational information for few-shot KGC. PrompMeta has two key innovations: (1) a meta-semantic prompt pool that captures and consolidates high-level meta-semantics, enabling effective knowledge transfer and adaptation to rare and newly emerging relations. (2) a learnable fusion prompt that dynamically combines meta-semantic information with task-specific relational information tailored to different few-shot tasks. Both components are optimized together with model parameters within a meta-learning framework. Extensive experiments on two benchmark datasets demonstrate the effectiveness of our approach.
Benchmarking Federated Machine Unlearning methods for Tabular Data
Apr 01, 2025



Machine unlearning, which enables a model to forget specific data upon request, is increasingly relevant in the era of privacy-centric machine learning, particularly within federated learning (FL) environments. This paper presents a pioneering study on benchmarking machine unlearning methods within a federated setting for tabular data, addressing the unique challenges posed by cross-silo FL where data privacy and communication efficiency are paramount. We explore unlearning at the feature and instance levels, employing both machine learning, random forest and logistic regression models. Our methodology benchmarks various unlearning algorithms, including fine-tuning and gradient-based approaches, across multiple datasets, with metrics focused on fidelity, certifiability, and computational efficiency. Experiments demonstrate that while fidelity remains high across methods, tree-based models excel in certifiability, ensuring exact unlearning, whereas gradient-based methods show improved computational efficiency. This study provides critical insights into the design and selection of unlearning algorithms tailored to the FL environment, offering a foundation for further research in privacy-preserving machine learning.
Beyond Standard MoE: Mixture of Latent Experts for Resource-Efficient Language Models
Mar 29, 2025



Mixture of Experts (MoE) has emerged as a pivotal architectural paradigm for efficient scaling of Large Language Models (LLMs), operating through selective activation of parameter subsets for each input token. Nevertheless, conventional MoE architectures encounter substantial challenges, including excessive memory utilization and communication overhead during training and inference, primarily attributable to the proliferation of expert modules. In this paper, we introduce Mixture of Latent Experts (MoLE), a novel parameterization methodology that facilitates the mapping of specific experts into a shared latent space. Specifically, all expert operations are systematically decomposed into two principal components: a shared projection into a lower-dimensional latent space, followed by expert-specific transformations with significantly reduced parametric complexity. This factorized approach substantially diminishes parameter count and computational requirements. Beyond the pretraining implementation of the MoLE architecture, we also establish a rigorous mathematical framework for transforming pre-trained MoE models into the MoLE architecture, characterizing the sufficient conditions for optimal factorization and developing a systematic two-phase algorithm for this conversion process. Our comprehensive theoretical analysis demonstrates that MoLE significantly enhances computational efficiency across multiple dimensions while preserving model representational capacity. Empirical evaluations corroborate our theoretical findings, confirming that MoLE achieves performance comparable to standard MoE implementations while substantially reducing resource requirements.
Unlocking Efficient Long-to-Short LLM Reasoning with Model Merging
Mar 26, 2025



The transition from System 1 to System 2 reasoning in large language models (LLMs) has marked significant advancements in handling complex tasks through deliberate, iterative thinking. However, this progress often comes at the cost of efficiency, as models tend to overthink, generating redundant reasoning steps without proportional improvements in output quality. Long-to-Short (L2S) reasoning has emerged as a promising solution to this challenge, aiming to balance reasoning depth with practical efficiency. While existing approaches, such as supervised fine-tuning (SFT), reinforcement learning (RL), and prompt engineering, have shown potential, they are either computationally expensive or unstable. Model merging, on the other hand, offers a cost-effective and robust alternative by integrating the quick-thinking capabilities of System 1 models with the methodical reasoning of System 2 models. In this work, we present a comprehensive empirical study on model merging for L2S reasoning, exploring diverse methodologies, including task-vector-based, SVD-based, and activation-informed merging. Our experiments reveal that model merging can reduce average response length by up to 55% while preserving or even improving baseline performance. We also identify a strong correlation between model scale and merging efficacy with extensive evaluations on 1.5B/7B/14B/32B models. Furthermore, we investigate the merged model's ability to self-critique and self-correct, as well as its adaptive response length based on task complexity. Our findings highlight model merging as a highly efficient and effective paradigm for L2S reasoning, offering a practical solution to the overthinking problem while maintaining the robustness of System 2 reasoning. This work can be found on Github https://github.com/hahahawu/Long-to-Short-via-Model-Merging.