 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEACHTEXT: CrossModal Generalized Distillation for Text-Video Retrieval
Apr 16, 2021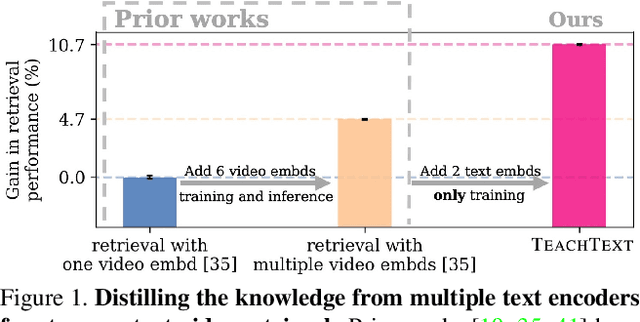

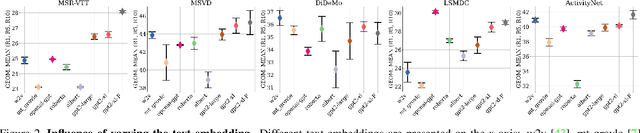
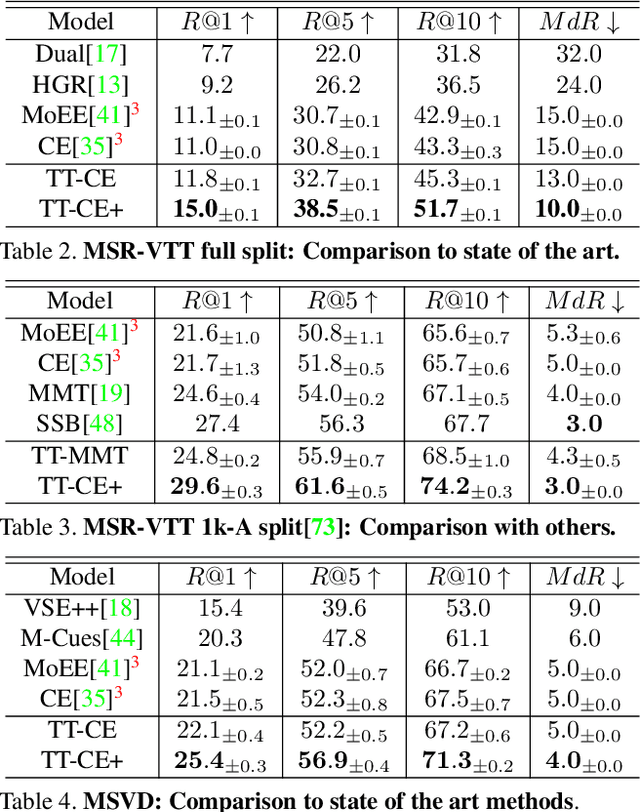
In recent years, considerable progress on the task of text-video retrieval has been achieved by leveraging large-scale pretraining on visual and audio datasets to construct powerful video encoders. By contrast, despite the natural symmetry, the design of effective algorithms for exploiting large-scale language pretraining remains under-explored. In this work, we are the first to investigate the design of such algorithms and propose a novel generalized distillation method, TeachText, which leverages complementary cues from multiple text encoders to provide an enhanced supervisory signal to the retrieval model. Moreover, we extend our method to video side modalities and show that we can effectively reduce the number of used modalities at test time without compromising performance. Our approach advances the state of the art on several video retrieval benchmarks by a significant margin and adds no computational overhead at test time. Last but not least, we show an effective application of our method for eliminating noise from retrieval datasets. Code and data can be found at https://www.robots.ox.ac.uk/~vgg/research/teachtext/.
ALADIN: All Layer Adaptive Instance Normalization for Fine-grained Style Similarity
Mar 17, 2021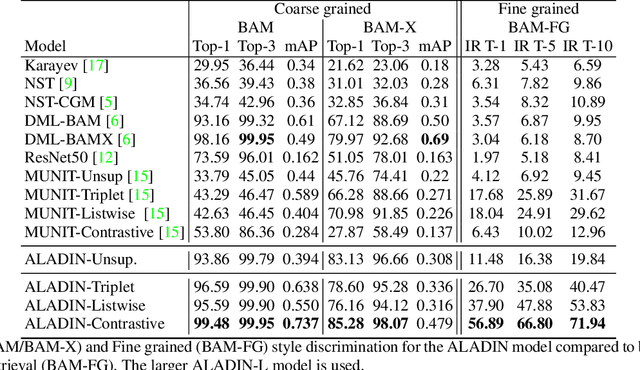
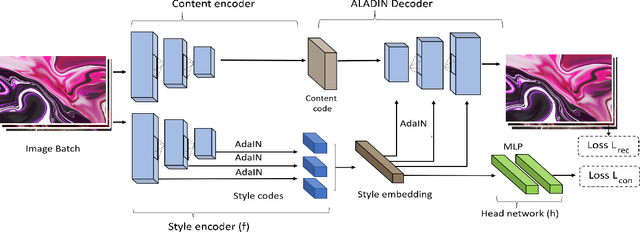
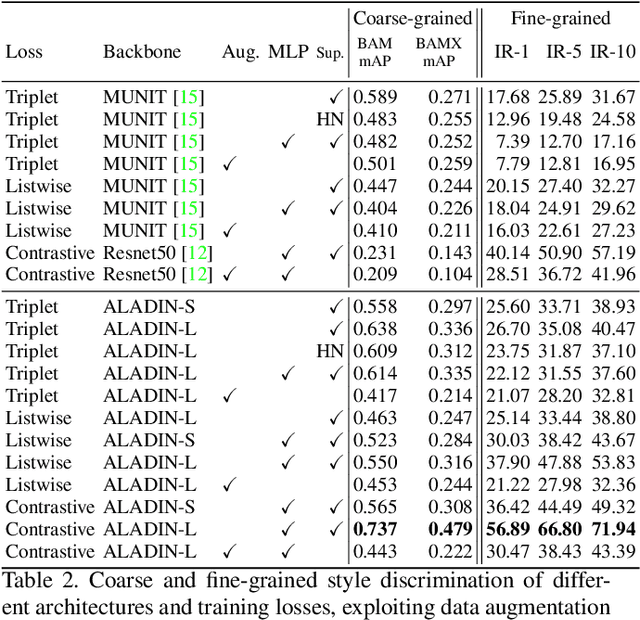

We present ALADIN (All Layer AdaIN); a novel architecture for searching images based on the similarity of their artistic style. Representation learning is critical to visual search, where distance in the learned search embedding reflects image similarity. Learning an embedding that discriminates fine-grained variations in style is hard, due to the difficulty of defining and labelling style. ALADIN takes a weakly supervised approach to learning a representation for fine-grained style similarity of digital artworks, leveraging BAM-FG, a novel large-scale dataset of user generated content groupings gathered from the web. ALADIN sets a new state of the art accuracy for style-based visual search over both coarse labelled style data (BAM) and BAM-FG; a new 2.62 million image dataset of 310,000 fine-grained style groupings also contributed by this work.
Video Question Answering on Screencast Tutorials
Aug 02, 2020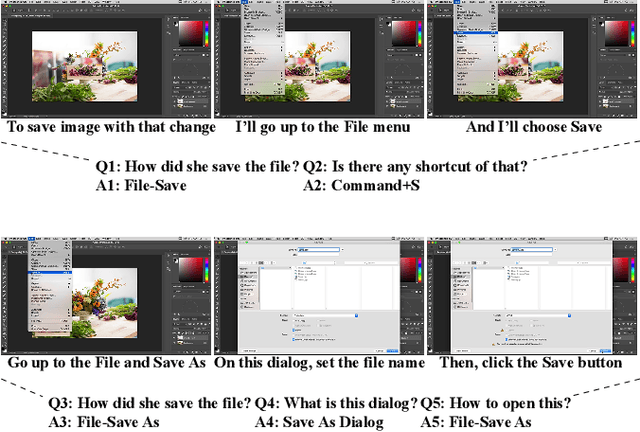
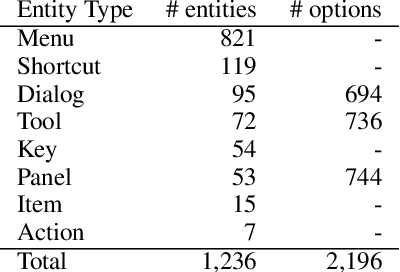
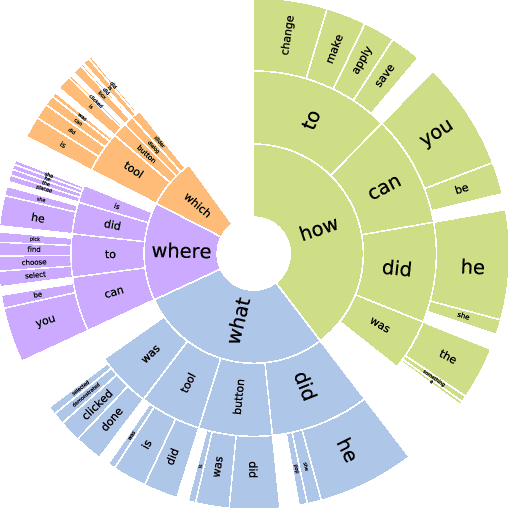
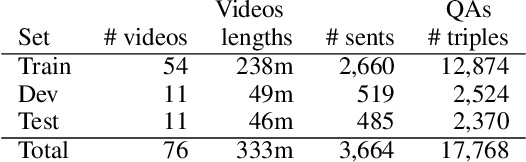
This paper presents a new video question answering task on screencast tutorials. We introduce a dataset including question, answer and context triples from the tutorial videos for a software. Unlike other video question answering works, all the answers in our dataset are grounded to the domain knowledge base. An one-shot recognition algorithm is designed to extract the visual cues, which helps enhance the performance of video question answering. We also propose several baseline neural network architectures based on various aspects of video contexts from the dataset. The experimental results demonstrate that our proposed models significantly improve the question answering performances by incorporating multi-modal contexts and domain knowledge.
Geo-PIFu: Geometry and Pixel Aligned Implicit Functions for Single-view Human Reconstruction
Jun 15, 2020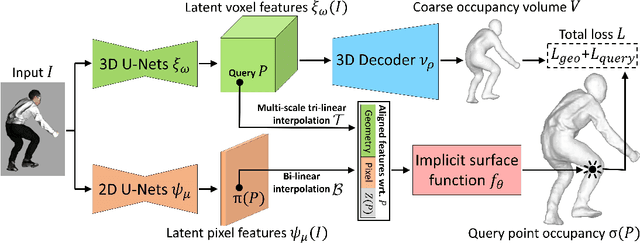
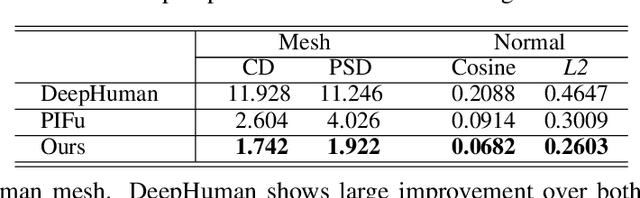

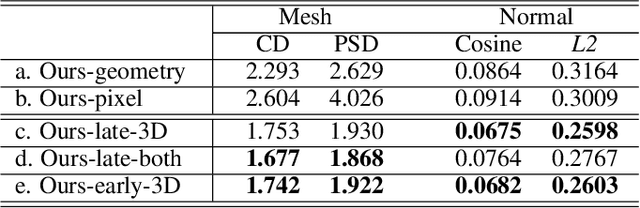
We propose Geo-PIFu, a method to recover a 3D mesh from a monocular color image of a clothed person. Our method is based on a deep implicit function-based representation to learn latent voxel features using a structure-aware 3D U-Net, to constrain the model in two ways: first, to resolve feature ambiguities in query point encoding, second, to serve as a coarse human shape proxy to regularize the high-resolution mesh and encourage global shape regularity. We show that, by both encoding query points and constraining global shape using latent voxel features, the reconstruction we obtain for clothed human meshes exhibits less shape distortion and improved surface details compared to competing methods. We evaluate Geo-PIFu on a recent human mesh public dataset that is $10 \times$ larger than the private commercial dataset used in PIFu and previous derivative work. On average, we exceed the state of the art by $42.7\%$ reduction in Chamfer and Point-to-Surface Distances, and $19.4\%$ reduction in normal estimation errors.
Steering Self-Supervised Feature Learning Beyond Local Pixel Statistics
Apr 05, 2020
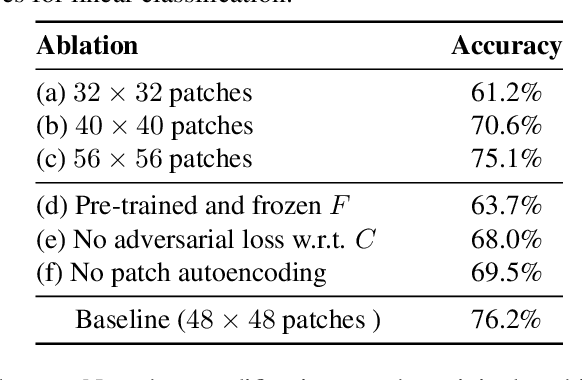

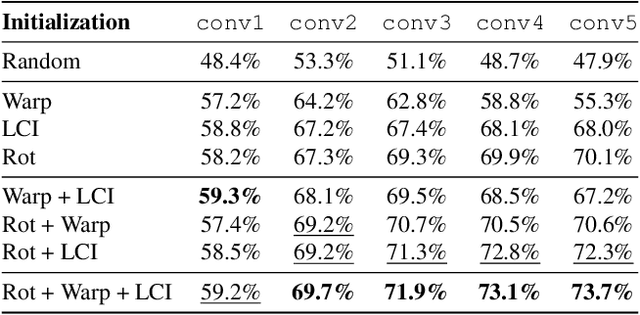
We introduce a novel principle for self-supervised feature learning based on the discrimination of specific transformations of an image. We argue that the generalization capability of learned features depends on what image neighborhood size is sufficient to discriminate different image transformations: The larger the required neighborhood size and the more global the image statistics that the feature can describe. An accurate description of global image statistics allows to better represent the shape and configuration of objects and their context, which ultimately generalizes better to new tasks such as object classification and detection. This suggests a criterion to choose and design image transformations. Based on this criterion, we introduce a novel image transformation that we call limited context inpainting (LCI). This transformation inpaints an image patch conditioned only on a small rectangular pixel boundary (the limited context). Because of the limited boundary information, the inpainter can learn to match local pixel statistics, but is unlikely to match the global statistics of the image. We claim that the same principle can be used to justify the performance of transformations such as image rotations and warping. Indeed, we demonstrate experimentally that learning to discriminate transformations such as LCI, image warping and rotations, yields features with state of the art generalization capabilities on several datasets such as Pascal VOC, STL-10, CelebA, and ImageNet. Remarkably, our trained features achieve a performance on Places on par with features trained through supervised learning with ImageNet labels.
Superpixel Segmentation with Fully Convolutional Networks
Mar 29, 2020
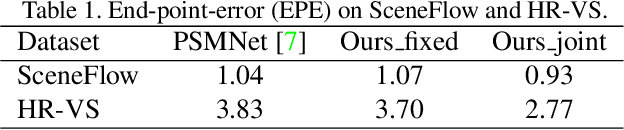

In computer vision, superpixels have been widely used as an effective way to reduce the number of image primitives for subsequent processing. But only a few attempts have been made to incorporate them into deep neural networks. One main reason is that the standard convolution operation is defined on regular grids and becomes inefficient when applied to superpixels. Inspired by an initialization strategy commonly adopted by traditional superpixel algorithms, we present a novel method that employs a simple fully convolutional network to predict superpixels on a regular image grid. Experimental results on benchmark datasets show that our method achieves state-of-the-art superpixel segmentation performance while running at about 50fps. Based on the predicted superpixels, we further develop a downsampling/upsampling scheme for deep networks with the goal of generating high-resolution outputs for dense prediction tasks. Specifically, we modify a popular network architecture for stereo matching to simultaneously predict superpixels and disparities. We show that improved disparity estimation accuracy can be obtained on public datasets.
Neural Architecture Search for Deep Image Prior
Jan 14, 2020
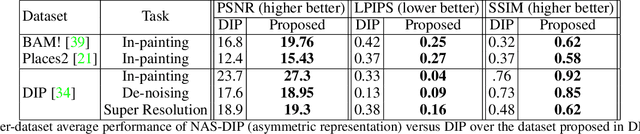
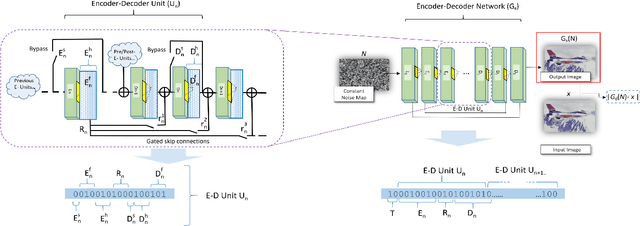
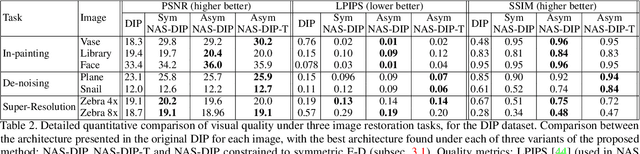
We present a neural architecture search (NAS) technique to enhance the performance of unsupervised image de-noising, in-painting and super-resolution under the recently proposed Deep Image Prior (DIP). We show that evolutionary search can automatically optimize the encoder-decoder (E-D) structure and meta-parameters of the DIP network, which serves as a content-specific prior to regularize these single image restoration tasks. Our binary representation encodes the design space for an asymmetric E-D network that typically converges to yield a content-specific DIP within 10-20 generations using a population size of 500. The optimized architectures consistently improve upon the visual quality of classical DIP for a diverse range of photographic and artistic content.
Large-scale Tag-based Font Retrieval with Generative Feature Learning
Oct 02, 2019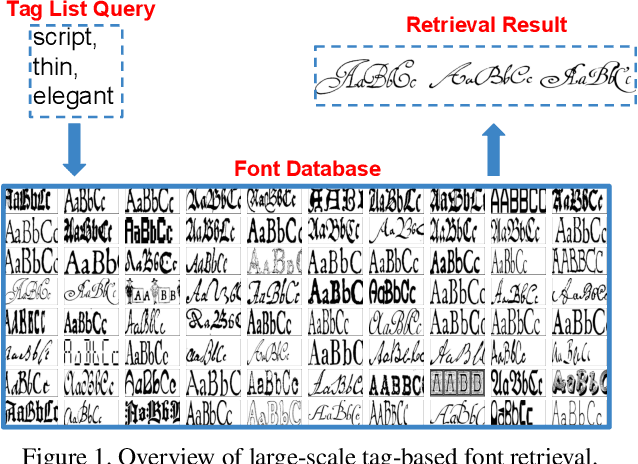
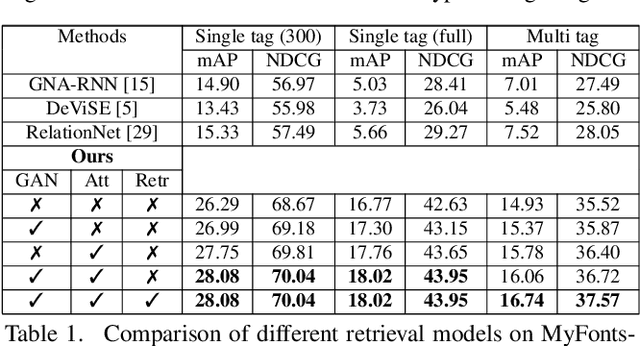
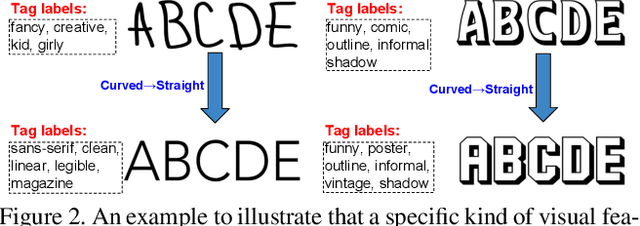

Font selection is one of the most important steps in a design workflow. Traditional methods rely on ordered lists which require significant domain knowledge and are often difficult to use even for trained professionals. In this paper, we address the problem of large-scale tag-based font retrieval which aims to bring semantics to the font selection process and enable people without expert knowledge to use fonts effectively. We collect a large-scale font tagging dataset of high-quality professional fonts. The dataset contains nearly 20,000 fonts, 2,000 tags, and hundreds of thousands of font-tag relations. We propose a novel generative feature learning algorithm that leverages the unique characteristics of fonts. The key idea is that font images are synthetic and can therefore be controlled by the learning algorithm. We design an integrated rendering and learning process so that the visual feature from one image can be used to reconstruct another image with different text. The resulting feature captures important font design details while is robust to nuisance factors such as text. We propose a novel attention mechanism to re-weight the visual feature for joint visual-text modeling. We combine the feature and the attention mechanism in a novel recognition-retrieval model. Experimental results show that our method significantly outperforms the state-of-the-art for the important problem of large-scale tag-based font retrieval.
An Internal Learning Approach to Video Inpainting
Sep 17, 2019
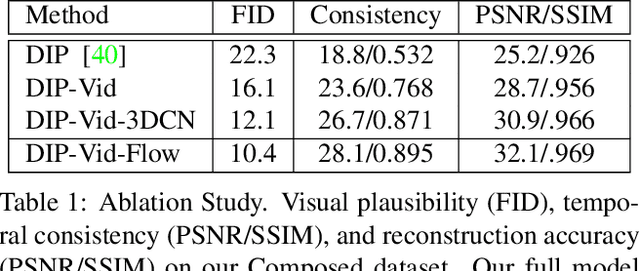
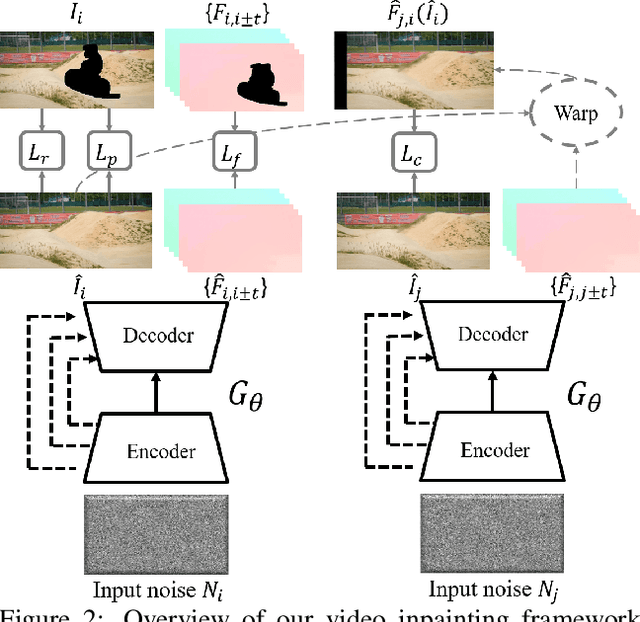
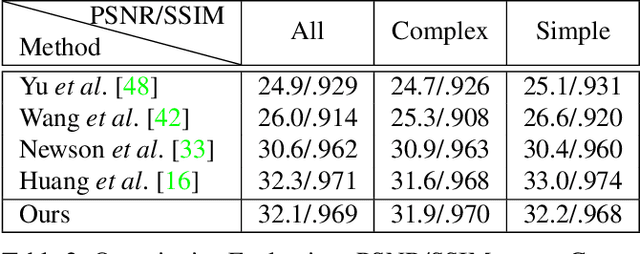
We propose a novel video inpainting algorithm that simultaneously hallucinates missing appearance and motion (optical flow) information, building upon the recent 'Deep Image Prior' (DIP) that exploits convolutional network architectures to enforce plausible texture in static images. In extending DIP to video we make two important contributions. First, we show that coherent video inpainting is possible without a priori training. We take a generative approach to inpainting based on internal (within-video) learning without reliance upon an external corpus of visual data to train a one-size-fits-all model for the large space of general videos. Second, we show that such a framework can jointly generate both appearance and flow, whilst exploiting these complementary modalities to ensure mutual consistency. We show that leveraging appearance statistics specific to each video achieves visually plausible results whilst handling the challenging problem of long-term consistency.
Privacy-Preserving Deep Visual Recognition: An Adversarial Learning Framework and A New Dataset
Jul 29, 2019
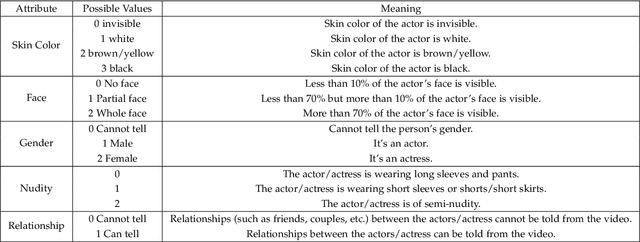
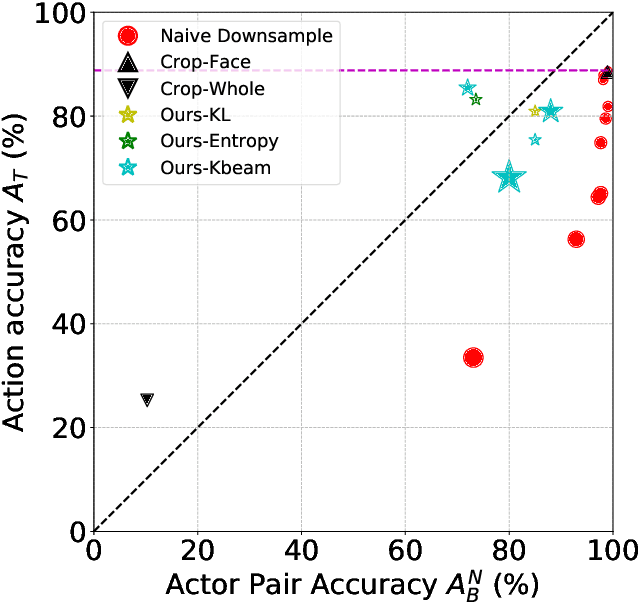
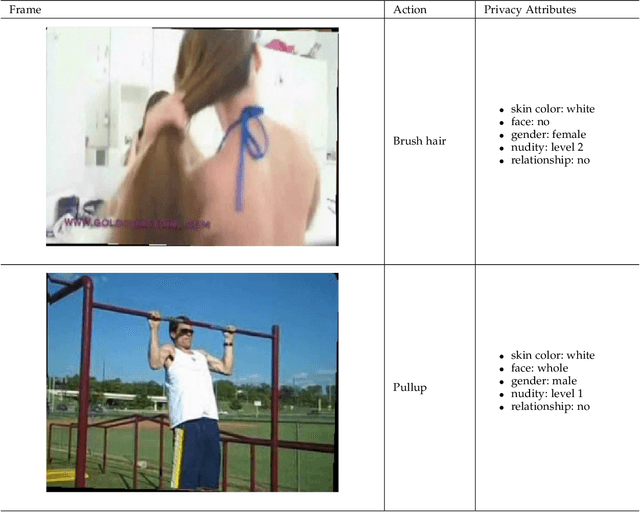
This paper aims to boost privacy-preserving visual recognition, an increasingly demanded feature in smart camera applications, using deep learning. We formulate a unique adversarial training framework, that learns a degradation transform for the original video inputs, in order to explicitly optimize the trade-off between target task performance and the associated privacy budgets on the degraded video. We carefully analyze and benchmark three different optimization strategies to train the resulting model. Notably, the privacy budget, often defined and measured in task-driven contexts, cannot be reliably indicated using any single model performance, because a strong protection of privacy has to sustain against any possible model that tries to hack privacy information. In order to tackle this problem, we propose two strategies: model restarting and model ensemble, which can be easily plug-and-play into our training algorithms and further improve the performance. Extensive experiments have been carried out and analyzed. On the other hand, few public datasets are available with both utility and privacy labels provided, making the power of data-driven (supervised) learning not yet fully unleashed on this task. We first discuss an innovative heuristic of cross-dataset training and evaluation, that jointly utilizes two datasets with target task and privacy labels respectively, for adversarial training. To further alleviate this challenge, we have constructed a new dataset, termed PA-HMDB51, with both target task (action) and selected privacy attributes (gender, age, race, nudity, and relationship) labeled on a frame-wise basis. This first-of-its-kind video dataset further validates the effectiveness of our proposed framework, and opens up new opportunities for the research community.