 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapidly deploying on-device eye tracking by distilling visual foundation models
Apr 02, 2026Eye tracking (ET) plays a critical role in augmented and virtual reality applications. However, rapidly deploying high-accuracy, on-device gaze estimation for new products remains challenging because hardware configurations (e.g., camera placement, camera pose, and illumination) often change across device generations. Visual foundation models (VFMs) are a promising direction for rapid training and deployment, and they excel on natural-image benchmarks; yet we find that off-the-shelf VFMs still struggle to achieve high accuracy on specialized near-eye infrared imagery. To address this gap, we introduce DistillGaze, a framework that distills a foundation model by leveraging labeled synthetic data and unlabeled real data for rapid and high-performance on-device gaze estimation. DistillGaze proceeds in two stages. First, we adapt a VFM into a domain-specialized teacher using self-supervised learning on labeled synthetic and unlabeled real images. Synthetic data provides scalable, high-quality gaze supervision, while unlabeled real data helps bridge the synthetic-to-real domain gap. Second, we train an on-device student using both teacher guidance and self-training. Evaluated on a large-scale, crowd-sourced dataset spanning over 2,000 participants, DistillGaze reduces median gaze error by 58.62% relative to synthetic-only baselines while maintaining a lightweight 256K-parameter model suitable for real-time on-device deployment. Overall, DistillGaze provides an efficient pathway for training and deploying ET models that adapt to hardware changes, and offers a recipe for combining synthetic supervision with unlabeled real data in on-device regression tasks.
PlanarRecon: Real-time 3D Plane Detection and Reconstruction from Posed Monocular Videos
Jun 15, 2022
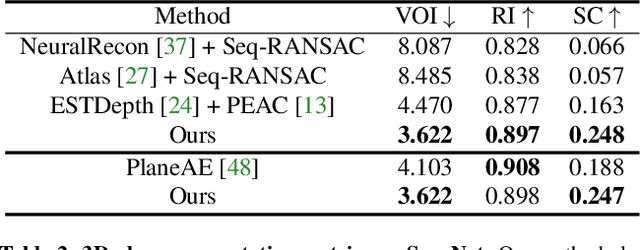
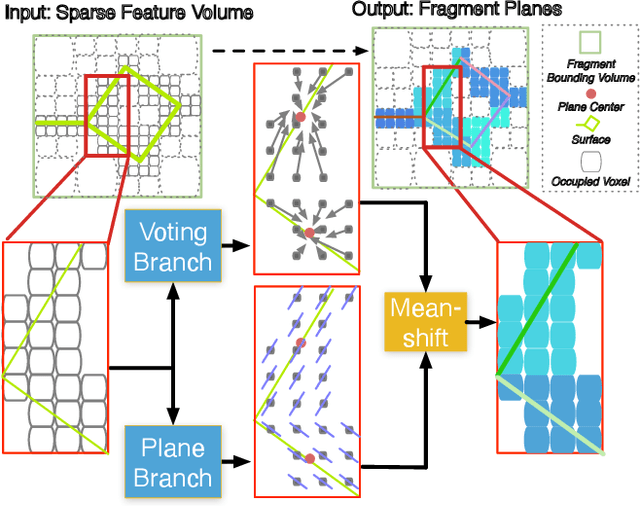
We present PlanarRecon -- a novel framework for globally coherent detection and reconstruction of 3D planes from a posed monocular video. Unlike previous works that detect planes in 2D from a single image, PlanarRecon incrementally detects planes in 3D for each video fragment, which consists of a set of key frames, from a volumetric representation of the scene using neural networks. A learning-based tracking and fusion module is designed to merge planes from previous fragments to form a coherent global plane reconstruction. Such design allows PlanarRecon to integrate observations from multiple views within each fragment and temporal information across different ones, resulting in an accurate and coherent reconstruction of the scene abstraction with low-polygonal geometry. Experiments show that the proposed approach achieves state-of-the-art performances on the ScanNet dataset while being real-time.
Deep Depth from Focus with Differential Focus Volume
Dec 03, 2021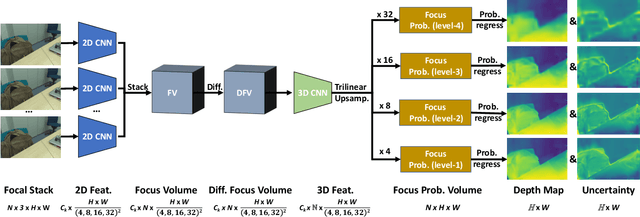

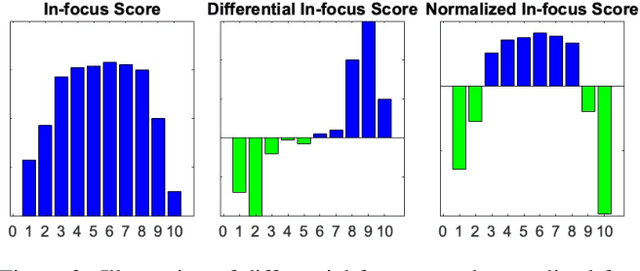

Depth-from-focus (DFF) is a technique that infers depth using the focus change of a camera. In this work, we propose a convolutional neural network (CNN) to find the best-focused pixels in a focal stack and infer depth from the focus estimation. The key innovation of the network is the novel deep differential focus volume (DFV). By computing the first-order derivative with the stacked features over different focal distances, DFV is able to capture both the focus and context information for focus analysis. Besides, we also introduce a probability regression mechanism for focus estimation to handle sparsely sampled focal stacks and provide uncertainty estimation to the final prediction. Comprehensive experiments demonstrate that the proposed model achieves state-of-the-art performance on multiple datasets with good generalizability and fast speed.
Superpixel Segmentation with Fully Convolutional Networks
Mar 29, 2020
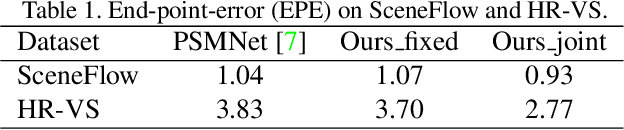
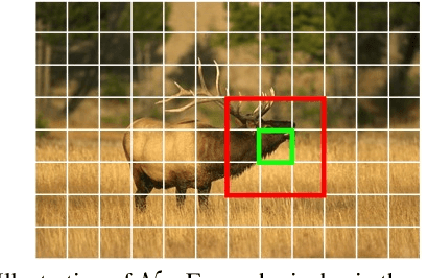

In computer vision, superpixels have been widely used as an effective way to reduce the number of image primitives for subsequent processing. But only a few attempts have been made to incorporate them into deep neural networks. One main reason is that the standard convolution operation is defined on regular grids and becomes inefficient when applied to superpixels. Inspired by an initialization strategy commonly adopted by traditional superpixel algorithms, we present a novel method that employs a simple fully convolutional network to predict superpixels on a regular image grid. Experimental results on benchmark datasets show that our method achieves state-of-the-art superpixel segmentation performance while running at about 50fps. Based on the predicted superpixels, we further develop a downsampling/upsampling scheme for deep networks with the goal of generating high-resolution outputs for dense prediction tasks. Specifically, we modify a popular network architecture for stereo matching to simultaneously predict superpixels and disparities. We show that improved disparity estimation accuracy can be obtained on public datasets.