 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Camera Pose Estimation with Online Partitioning
Aug 05, 2019
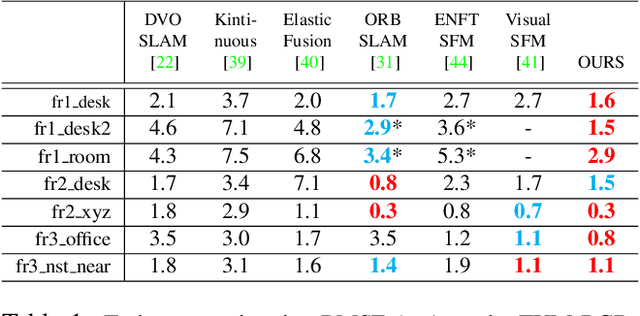
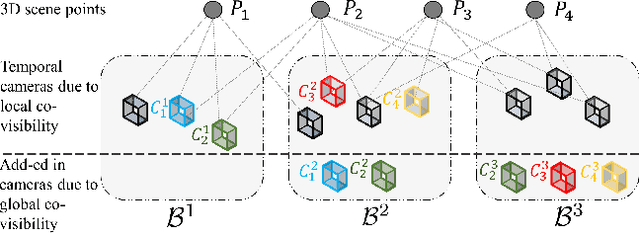
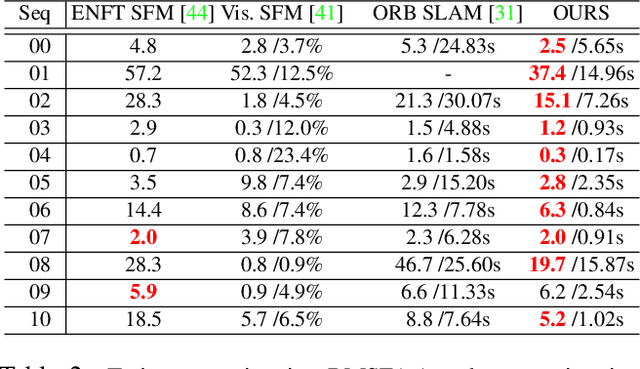
This paper presents a hybrid real-time camera pose estimation framework with a novel partitioning scheme and introduces motion averaging to on-line monocular systems. Breaking through the limitations of fixed-size temporal partitioning in most conventional pose estimation mechanisms, the proposed approach significantly improves the accuracy of local bundle adjustment by gathering spatially-strongly-connected cameras into each block. With the dynamic initialization using intermediate computation values, our proposed self-adaptive Levenberg-Marquardt solver achieves a quadratic convergence rate to further enhance the efficiency of the local optimization. Moreover, the dense data association between blocks by virtue of our co-visibility-based partitioning enables us to explore and implement motion averaging to efficiently align the blocks globally, updating camera motion estimations on-the-fly. Experiment results on benchmarks convincingly demonstrate the practicality and robustness of our proposed approach by outperforming conventional bundle adjustment by orders of magnitude.
Graph Attribute Aggregation Network with Progressive Margin Folding
May 14, 2019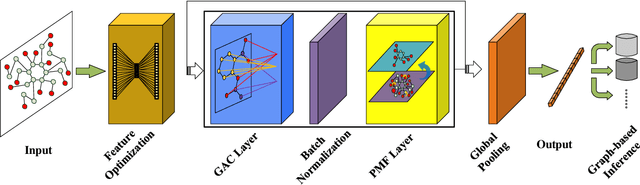
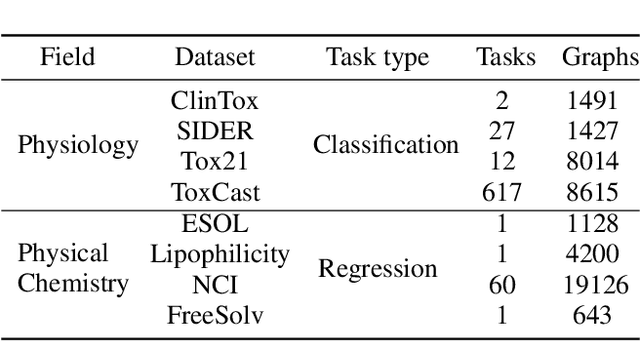
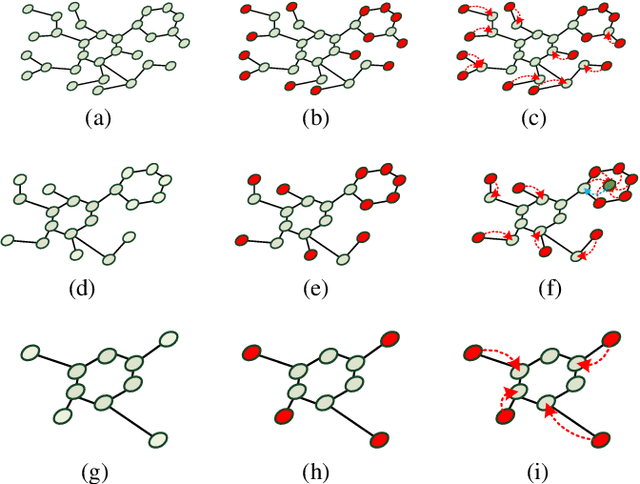
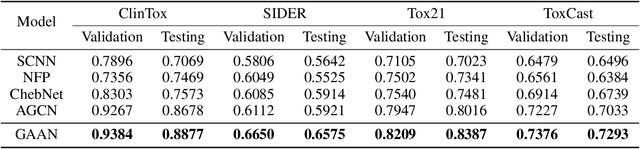
Graph convolutional neural networks (GCNNs) have been attracting increasing research attention due to its great potential in inference over graph structures. However, insufficient effort has been devoted to the aggregation methods between different convolution graph layers. In this paper, we introduce a graph attribute aggregation network (GAAN) architecture. Different from the conventional pooling operations, a graph-transformation-based aggregation strategy, progressive margin folding, PMF, is proposed for integrating graph features. By distinguishing internal and margin elements, we provide an approach for implementing the folding iteratively. And a mechanism is also devised for preserving the local structures during progressively folding. In addition, a hypergraph-based representation is introduced for transferring the aggregated information between different layers. Our experiments applied to the public molecule datasets demonstrate that the proposed GAAN outperforms the existing GCNN models with significant effectiveness.
Salient Object Detection in the Deep Learning Era: An In-Depth Survey
Apr 19, 2019
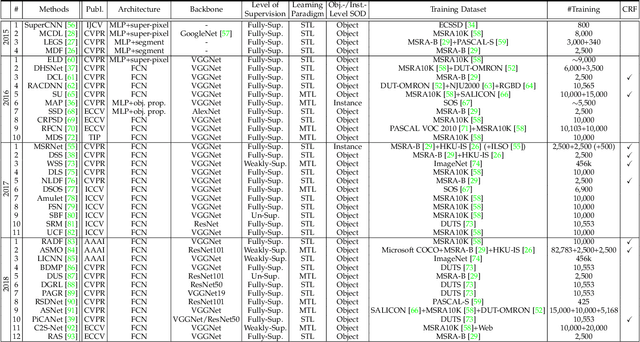
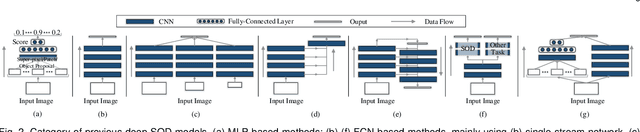
As an important problem in computer vision, salient object detection (SOD) from images has been attracting an increasing amount of research effort over the years. Recent advances in SOD, not surprisingly, are dominantly led by deep learning-based solutions (named deep SOD) and reflected by hundreds of published papers. To facilitate the in-depth understanding of deep SODs, in this paper we provide a comprehensive survey covering various aspects ranging from algorithm taxonomy to unsolved open issues. In particular, we first review deep SOD algorithms from different perspectives including network architecture, level of supervision, learning paradigm and object/instance level detection. Following that, we summarize existing SOD evaluation datasets and metrics. Then, we carefully compile a thorough benchmark results of SOD methods based on previous work, and provide detailed analysis of the comparison results. Moreover, we study the performance of SOD algorithms under different attributes, which have been barely explored previously, by constructing a novel SOD dataset with rich attribute annotations. We further analyze, for the first time in the field, the robustness and transferability of deep SOD models w.r.t. adversarial attacks. We also look into the influence of input perturbations, and the generalization and hardness of existing SOD datasets. Finally, we discuss several open issues and challenges of SOD, and point out possible research directions in future. All the saliency prediction maps, our constructed dataset with annotations, and codes for evaluation are made publicly available at https://github.com/wenguanwang/SODsurvey.
Clustered Object Detection in Aerial Images
Apr 16, 2019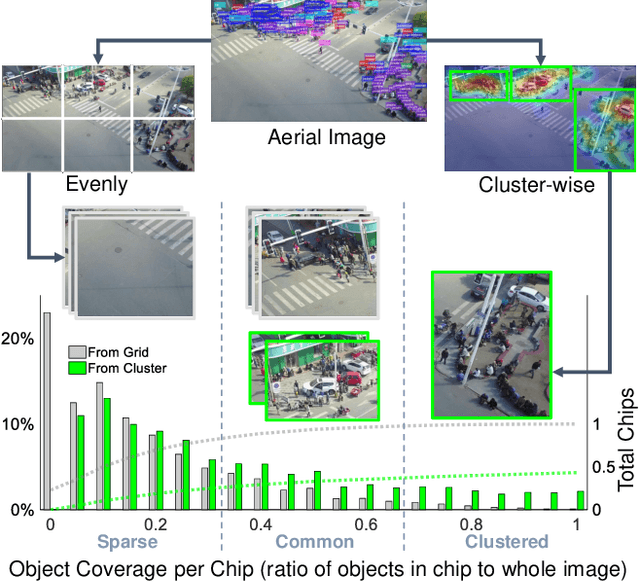
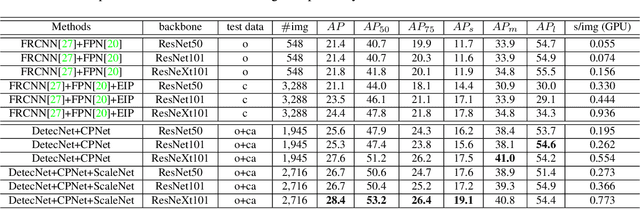
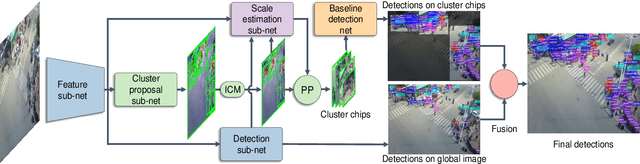
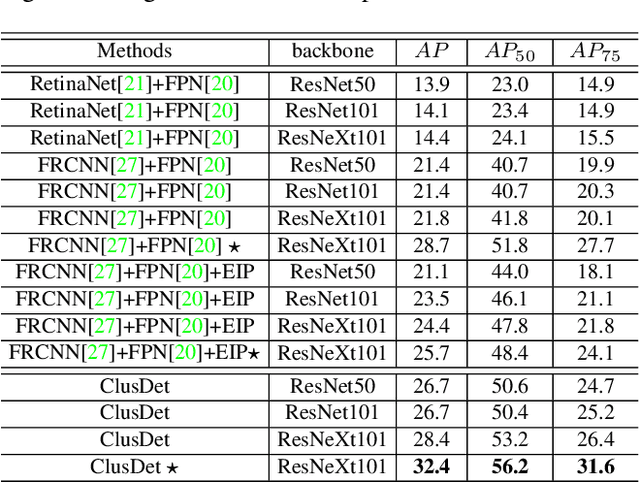
Detecting objects in aerial images is challenging for at least two reasons: (1) target objects like pedestrians are very small in terms of pixels, making them hard to be distinguished from surrounding background; and (2) targets are in general very sparsely and nonuniformly distributed, making the detection very inefficient. In this paper we address both issues inspired by the observation that these targets are often clustered. In particular, we propose a Clustered Detection (ClusDet) network that unifies object cluster and detection in an end-to-end framework. The key components in ClusDet include a cluster proposal sub-network (CPNet), a scale estimation sub-network (ScaleNet), and a dedicated detection network (DetecNet). Given an input image, CPNet produces (object) cluster regions and ScaleNet estimates object scales for these regions. Then, each scale-normalized cluster region and their features are fed into DetecNet for object detection. Compared with previous solutions, ClusDet has several advantages: (1) it greatly reduces the number of blocks for final object detection and hence achieves high running time efficiency, (2) the cluster-based scale estimation is more accurate than previously used single-object based ones, hence effectively improves the detection for small objects, and (3) the final DetecNet is dedicated for clustered regions and implicitly models the prior context information so as to boost detection accuracy. The proposed method is tested on three representative aerial image datasets including VisDrone, UAVDT and DOTA. In all the experiments, ClusDet achieves promising performance in both efficiency and accuracy, in comparison with state-of-the-art detectors.
FAMNet: Joint Learning of Feature, Affinity and Multi-dimensional Assignment for Online Multiple Object Tracking
Apr 10, 2019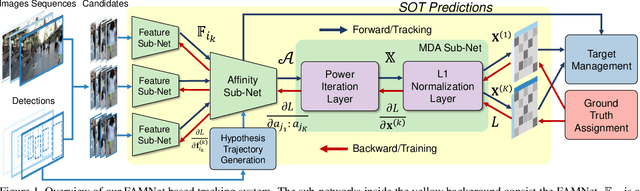
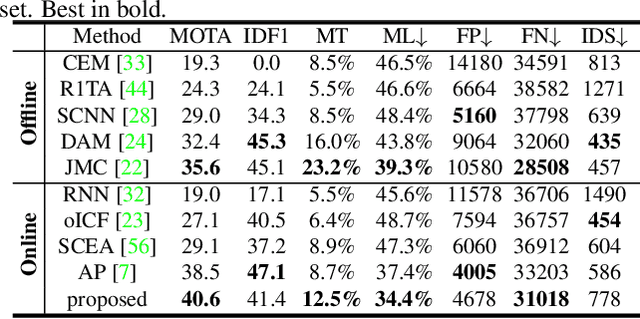
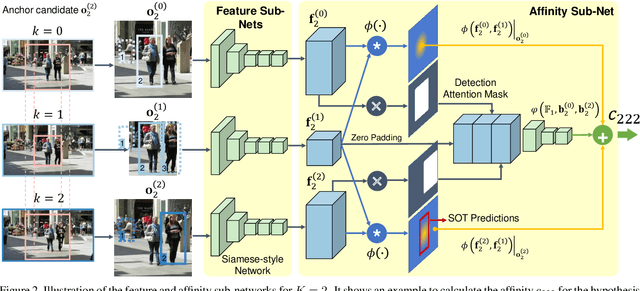
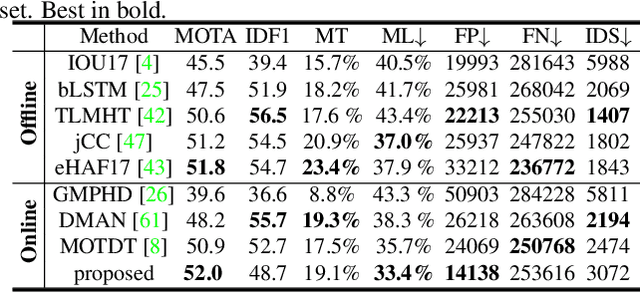
Data association-based multiple object tracking (MOT) involves multiple separated modules processed or optimized differently, which results in complex method design and requires non-trivial tuning of parameters. In this paper, we present an end-to-end model, named FAMNet, where Feature extraction, Affinity estimation and Multi-dimensional assignment are refined in a single network. All layers in FAMNet are designed differentiable thus can be optimized jointly to learn the discriminative features and higher-order affinity model for robust MOT, which is supervised by the loss directly from the assignment ground truth. We also integrate single object tracking technique and a dedicated target management scheme into the FAMNet-based tracking system to further recover false negatives and inhibit noisy target candidates generated by the external detector. The proposed method is evaluated on a diverse set of benchmarks including MOT2015, MOT2017, KITTI-Car and UA-DETRAC, and achieves promising performance on all of them in comparison with state-of-the-arts.
End-to-end Projector Photometric Compensation
Apr 08, 2019
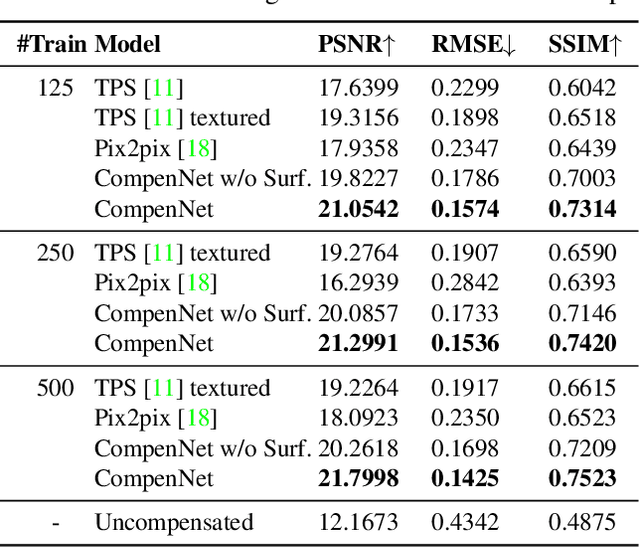
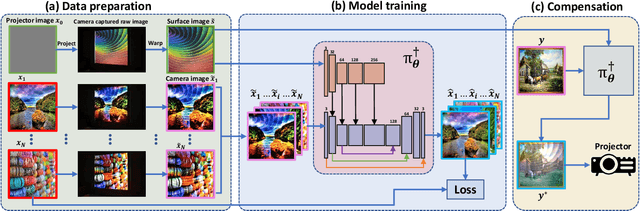
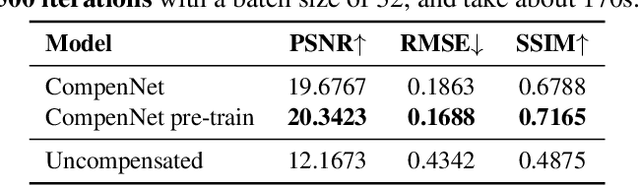
Projector photometric compensation aims to modify a projector input image such that it can compensate for disturbance from the appearance of projection surface. In this paper, for the first time, we formulate the compensation problem as an end-to-end learning problem and propose a convolutional neural network, named CompenNet, to implicitly learn the complex compensation function. CompenNet consists of a UNet-like backbone network and an autoencoder subnet. Such architecture encourages rich multi-level interactions between the camera-captured projection surface image and the input image, and thus captures both photometric and environment information of the projection surface. In addition, the visual details and interaction information are carried to deeper layers along the multi-level skip convolution layers. The architecture is of particular importance for the projector compensation task, for which only a small training dataset is allowed in practice. Another contribution we make is a novel evaluation benchmark, which is independent of system setup and thus quantitatively verifiable. Such benchmark is not previously available, to our best knowledge, due to the fact that conventional evaluation requests the hardware system to actually project the final results. Our key idea, motivated from our end-to-end problem formulation, is to use a reasonable surrogate to avoid such projection process so as to be setup-independent. Our method is evaluated carefully on the benchmark, and the results show that our end-to-end learning solution outperforms state-of-the-arts both qualitatively and quantitatively by a significant margin.
Generic Multiview Visual Tracking
Apr 04, 2019
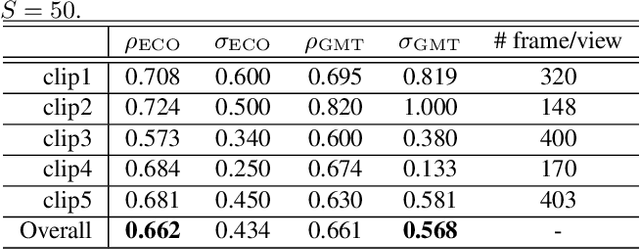
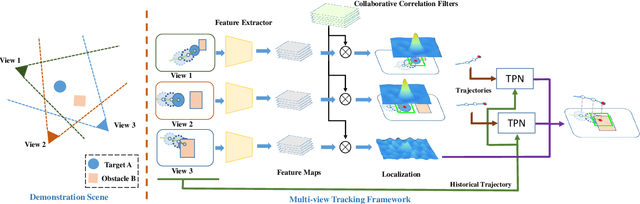
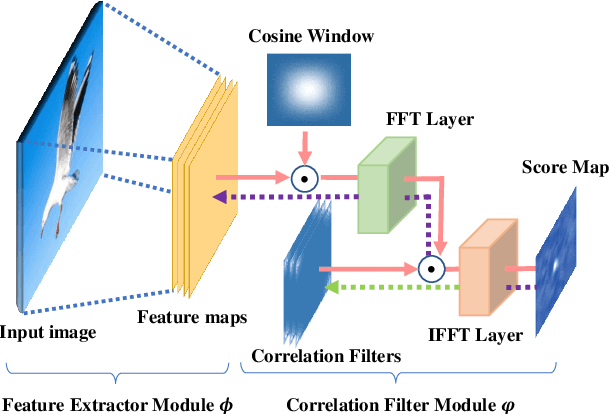
Recent progresses in visual tracking have greatly improved the tracking performance. However, challenges such as occlusion and view change remain obstacles in real world deployment. A natural solution to these challenges is to use multiple cameras with multiview inputs, though existing systems are mostly limited to specific targets (e.g. human), static cameras, and/or camera calibration. To break through these limitations, we propose a generic multiview tracking (GMT) framework that allows camera movement, while requiring neither specific object model nor camera calibration. A key innovation in our framework is a cross-camera trajectory prediction network (TPN), which implicitly and dynamically encodes camera geometric relations, and hence addresses missing target issues such as occlusion. Moreover, during tracking, we assemble information across different cameras to dynamically update a novel collaborative correlation filter (CCF), which is shared among cameras to achieve robustness against view change. The two components are integrated into a correlation filter tracking framework, where the features are trained offline using existing single view tracking datasets. For evaluation, we first contribute a new generic multiview tracking dataset (GMTD) with careful annotations, and then run experiments on GMTD and the PETS2009 datasets. On both datasets, the proposed GMT algorithm shows clear advantages over state-of-the-art ones.
StructVIO : Visual-inertial Odometry with Structural Regularity of Man-made Environments
Mar 05, 2019

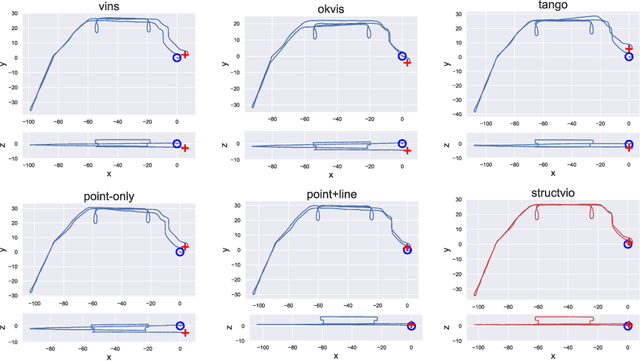
We propose a novel visual-inertial odometry approach that adopts structural regularity in man-made environments. Instead of using Manhattan world assumption, we use Atlanta world model to describe such regularity. An Atlanta world is a world that contains multiple local Manhattan worlds with different heading directions. Each local Manhattan world is detected on-the-fly, and their headings are gradually refined by the state estimator when new observations are coming. With fully exploration of structural lines that aligned with each local Manhattan worlds, our visual-inertial odometry method become more accurate and robust, as well as much more flexible to different kinds of complex man-made environments. Through extensive benchmark tests and real-world tests, the results show that the proposed approach outperforms existing visual-inertial systems in large-scale man-made environments
PFLD: A Practical Facial Landmark Detector
Mar 03, 2019
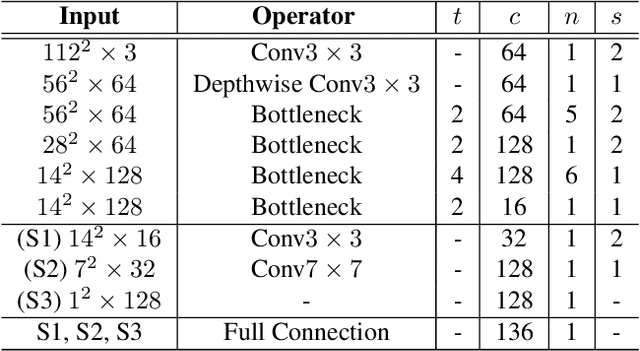
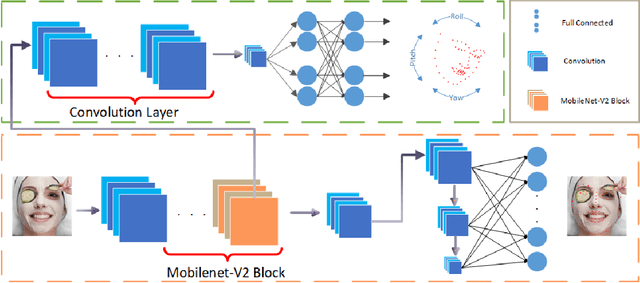

Being accurate, efficient, and compact is essential to a facial landmark detector for practical use. To simultaneously consider the three concerns, this paper investigates a neat model with promising detection accuracy under wild environments e.g., unconstrained pose, expression, lighting, and occlusion conditions) and super real-time speed on a mobile device. More concretely, we customize an end-to-end single stage network associated with acceleration techniques. During the training phase, for each sample, rotation information is estimated for geometrically regularizing landmark localization, which is then NOT involved in the testing phase. A novel loss is designed to, besides considering the geometrical regularization, mitigate the issue of data imbalance by adjusting weights of samples to different states, such as large pose, extreme lighting, and occlusion, in the training set. Extensive experiments are conducted to demonstrate the efficacy of our design and reveal its superior performance over state-of-the-art alternatives on widely-adopted challenging benchmarks, i.e., 300W (including iBUG, LFPW, AFW, HELEN, and XM2VTS) and AFLW. Our model can be merely 2.1Mb of size and reach over 140 fps per face on a mobile phone (Qualcomm ARM 845 processor) with high precision, making it attractive for large-scale or real-time applications. We have made our practical system based on PFLD 0.25X model publicly available at \url{http://sites.google.com/view/xjguo/fld} for encouraging comparisons and improvements from the community.
Online Multi-Object Tracking with Instance-Aware Tracker and Dynamic Model Refreshment
Feb 21, 2019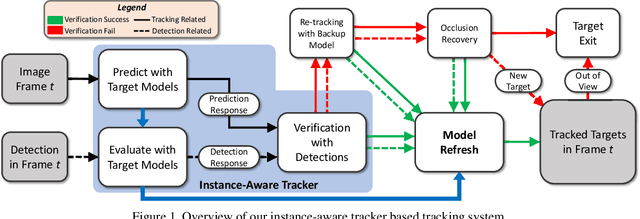
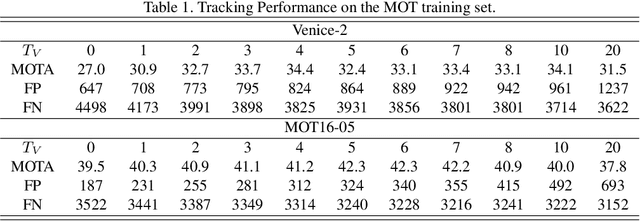
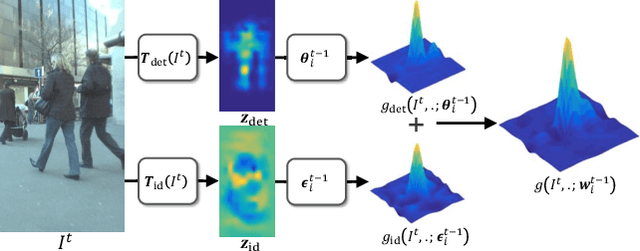
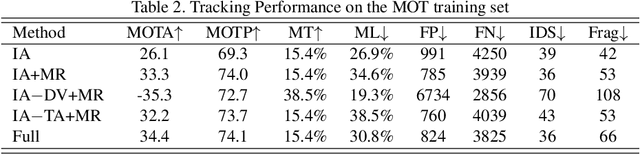
Recent progresses in model-free single object tracking (SOT) algorithms have largely inspired applying SOT to \emph{multi-object tracking} (MOT) to improve the robustness as well as relieving dependency on external detector. However, SOT algorithms are generally designed for distinguishing a target from its environment, and hence meet problems when a target is spatially mixed with similar objects as observed frequently in MOT. To address this issue, in this paper we propose an instance-aware tracker to integrate SOT techniques for MOT by encoding awareness both within and between target models. In particular, we construct each target model by fusing information for distinguishing target both from background and other instances (tracking targets). To conserve uniqueness of all target models, our instance-aware tracker considers response maps from all target models and assigns spatial locations exclusively to optimize the overall accuracy. Another contribution we make is a dynamic model refreshing strategy learned by a convolutional neural network. This strategy helps to eliminate initialization noise as well as to adapt to the variation of target size and appearance. To show the effectiveness of the proposed approach, it is evaluated on the popular MOT15 and MOT16 challenge benchmarks. On both benchmarks, our approach achieves the best overall performances in comparison with published results.