 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSTO: Gated Scale-Transfer Operation for Multi-Scale Feature Learning in Pixel Labeling
Jun 28, 2020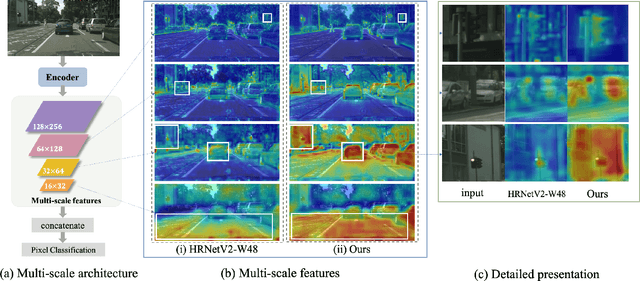
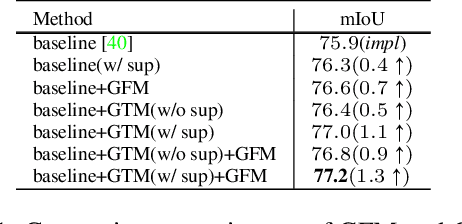
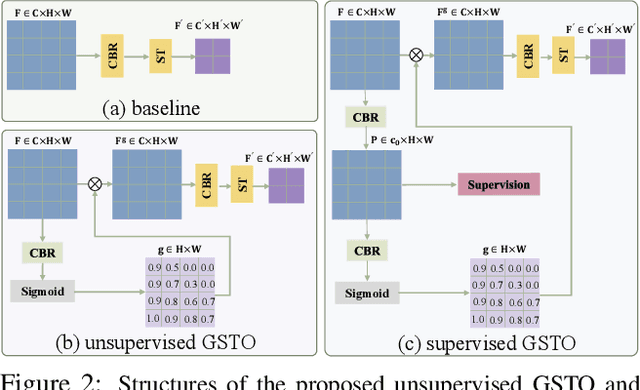
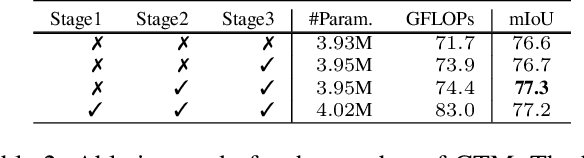
Existing CNN-based methods for pixel labeling heavily depend on multi-scale features to meet the requirements of both semantic comprehension and detail preservation. State-of-the-art pixel labeling neural networks widely exploit conventional scale-transfer operations, i.e., up-sampling and down-sampling to learn multi-scale features. In this work, we find that these operations lead to scale-confused features and suboptimal performance because they are spatial-invariant and directly transit all feature information cross scales without spatial selection. To address this issue, we propose the Gated Scale-Transfer Operation (GSTO) to properly transit spatial-filtered features to another scale. Specifically, GSTO can work either with or without extra supervision. Unsupervised GSTO is learned from the feature itself while the supervised one is guided by the supervised probability matrix. Both forms of GSTO are lightweight and plug-and-play, which can be flexibly integrated into networks or modules for learning better multi-scale features. In particular, by plugging GSTO into HRNet, we get a more powerful backbone (namely GSTO-HRNet) for pixel labeling, and it achieves new state-of-the-art results on the COCO benchmark for human pose estimation and other benchmarks for semantic segmentation including Cityscapes, LIP and Pascal Context, with negligible extra computational cost. Moreover, experiment results demonstrate that GSTO can also significantly boost the performance of multi-scale feature aggregation modules like PPM and ASPP. Code will be made available at https://github.com/VDIGPKU/GSTO.
Graph Neural Network for Hamiltonian-Based Material Property Prediction
May 27, 2020

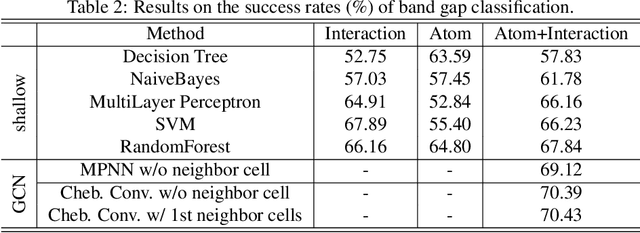
Development of next-generation electronic devices for applications call for the discovery of quantum materials hosting novel electronic, magnetic, and topological properties. Traditional electronic structure methods require expensive computation time and memory consumption, thus a fast and accurate prediction model is desired with increasing importance. Representing the interactions among atomic orbitals in any material, a material Hamiltonian provides all the essential elements that control the structure-property correlations in inorganic compounds. Effective learning of material Hamiltonian by developing machine learning methodologies therefore offers a transformative approach to accelerate the discovery and design of quantum materials. With this motivation, we present and compare several different graph convolution networks that are able to predict the band gap for inorganic materials. The models are developed to incorporate two different features: the information of each orbital itself and the interaction between each other. The information of each orbital includes the name, relative coordinates with respect to the center of super cell and the atom number, while the interaction between orbitals are represented by the Hamiltonian matrix. The results show that our model can get a promising prediction accuracy with cross-validation.
TapLab: A Fast Framework for Semantic Video Segmentation Tapping into Compressed-Domain Knowledge
Mar 30, 2020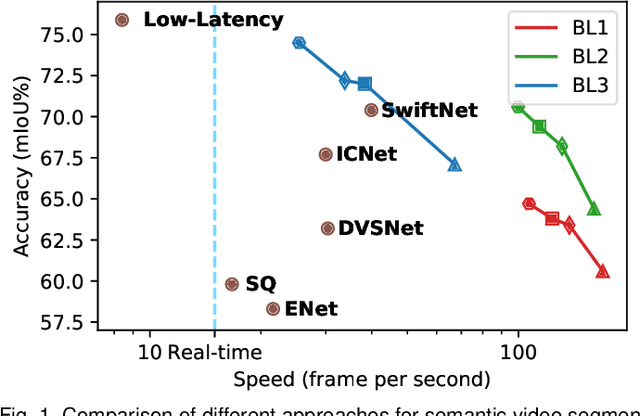
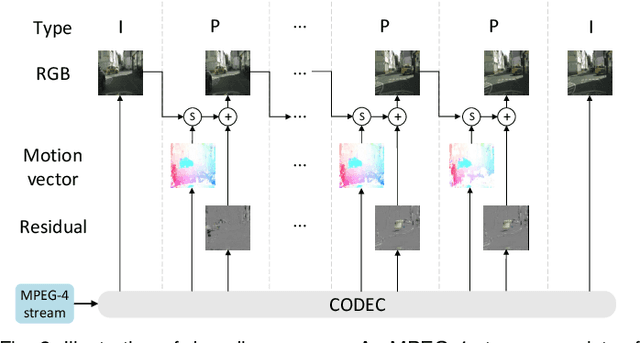

Real-time semantic video segmentation is a challenging task due to the strict requirements of inference speed. Recent approaches mainly devote great efforts to reducing the model size for high efficiency. In this paper, we rethink this problem from a different viewpoint: using knowledge contained in compressed videos. We propose a simple and effective framework, dubbed TapLab, to tap into resources from the compressed domain. Specifically, we design a fast feature warping module using motion vectors for acceleration. To reduce the noise introduced by motion vectors, we design a residual-guided correction module and a residual-guided frame selection module using residuals. Compared with the state-of-the-art fast semantic image segmentation models, our proposed TapLab significantly reduces redundant computations, running around 3 times faster with comparable accuracy for 1024x2048 video. The experimental results show that TapLab achieves 70.6% mIoU on the Cityscapes dataset at 99.8 FPS with a single GPU card. A high-speed version even reaches the speed of 160+ FPS.
Cascaded Human-Object Interaction Recognition
Mar 11, 2020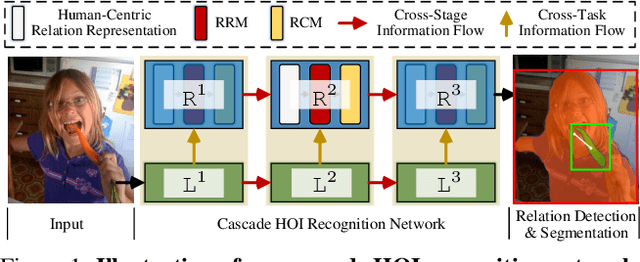

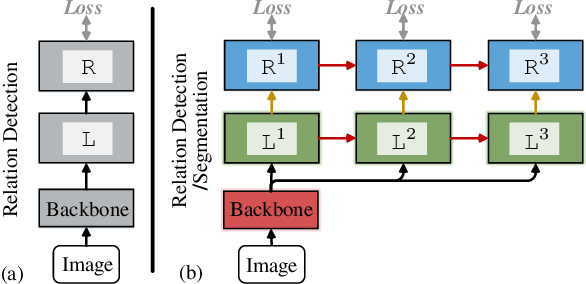
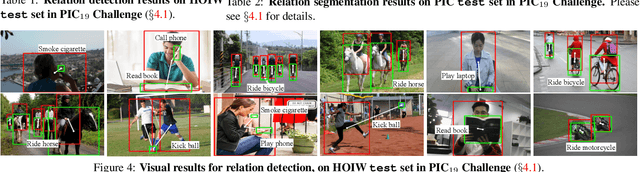
Rapid progress has been witnessed for human-object interaction (HOI) recognition, but most existing models are confined to single-stage reasoning pipelines. Considering the intrinsic complexity of the task, we introduce a cascade architecture for a multi-stage, coarse-to-fine HOI understanding. At each stage, an instance localization network progressively refines HOI proposals and feeds them into an interaction recognition network. Each of the two networks is also connected to its predecessor at the previous stage, enabling cross-stage information propagation. The interaction recognition network has two crucial parts: a relation ranking module for high-quality HOI proposal selection and a triple-stream classifier for relation prediction. With our carefully-designed human-centric relation features, these two modules work collaboratively towards effective interaction understanding. Further beyond relation detection on a bounding-box level, we make our framework flexible to perform fine-grained pixel-wise relation segmentation; this provides a new glimpse into better relation modeling. Our approach reached the $1^{st}$ place in the ICCV2019 Person in Context Challenge, on both relation detection and segmentation tasks. It also shows promising results on V-COCO.
DeLTra: Deep Light Transport for Projector-Camera Systems
Mar 06, 2020
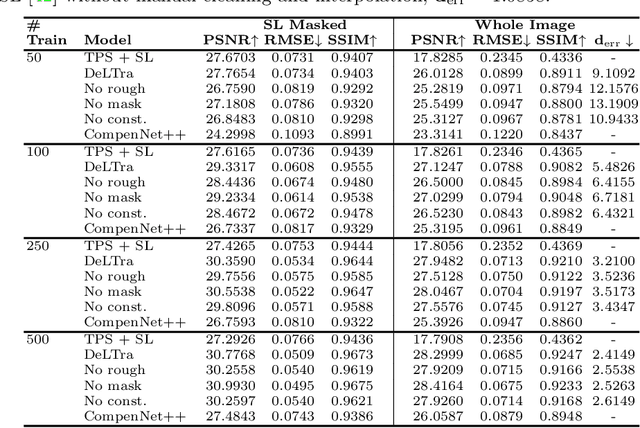

In projector-camera systems, light transport models the propagation from projector emitted radiance to camera-captured irradiance. In this paper, we propose the first end-to-end trainable solution named Deep Light Transport (DeLTra) that estimates radiometrically uncalibrated projector-camera light transport. DeLTra is designed to have two modules: DepthToAtrribute and ShadingNet. DepthToAtrribute explicitly learns rays, depth and normal, and then estimates rough Phong illuminations. Afterwards, the CNN-based ShadingNet renders photorealistic camera-captured image using estimated shading attributes and rough Phong illuminations. A particular challenge addressed by DeLTra is occlusion, for which we exploit epipolar constraint and propose a novel differentiable direct light mask. Thus, it can be learned end-to-end along with the other DeLTra modules. Once trained, DeLTra can be applied simultaneously to three projector-camera tasks: image-based relighting, projector compensation and depth/normal reconstruction. In our experiments, DeLTra shows clear advantages over previous arts with promising quality and meanwhile being practically convenient.
Weakly Supervised Attention Pyramid Convolutional Neural Network for Fine-Grained Visual Classification
Feb 09, 2020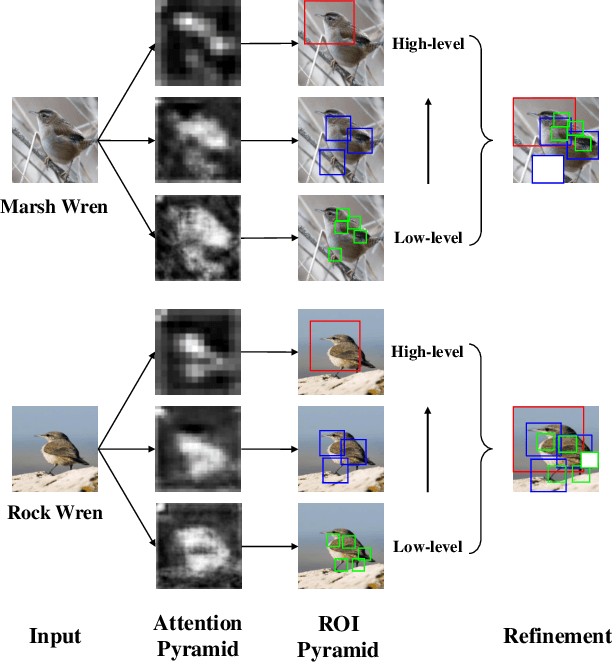
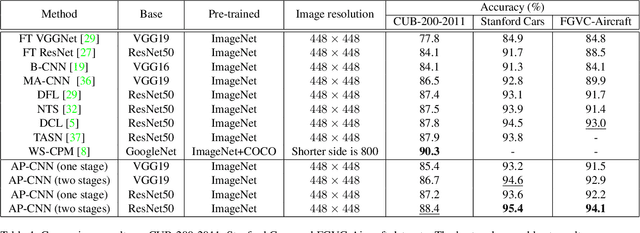
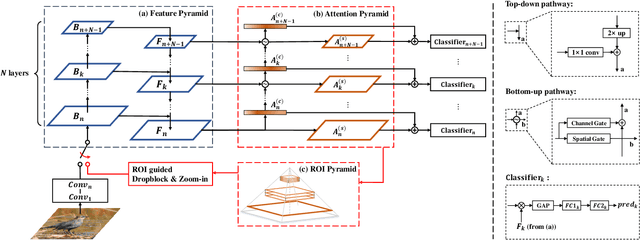

Classifying the sub-categories of an object from the same super-category (e.g. bird species, car and aircraft models) in fine-grained visual classification (FGVC) highly relies on discriminative feature representation and accurate region localization. Existing approaches mainly focus on distilling information from high-level features. In this paper, however, we show that by integrating low-level information (e.g. color, edge junctions, texture patterns), performance can be improved with enhanced feature representation and accurately located discriminative regions. Our solution, named Attention Pyramid Convolutional Neural Network (AP-CNN), consists of a) a pyramidal hierarchy structure with a top-down feature pathway and a bottom-up attention pathway, and hence learns both high-level semantic and low-level detailed feature representation, and b) an ROI guided refinement strategy with ROI guided dropblock and ROI guided zoom-in, which refines features with discriminative local regions enhanced and background noises eliminated. The proposed AP-CNN can be trained end-to-end, without the need of additional bounding box/part annotations. Extensive experiments on three commonly used FGVC datasets (CUB-200-2011, Stanford Cars, and FGVC-Aircraft) demonstrate that our approach can achieve state-of-the-art performance. Code available at \url{http://dwz1.cc/ci8so8a}
Human-Aware Motion Deblurring
Jan 19, 2020


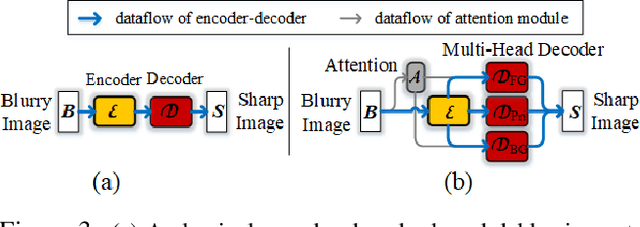
This paper proposes a human-aware deblurring model that disentangles the motion blur between foreground (FG) humans and background (BG). The proposed model is based on a triple-branch encoder-decoder architecture. The first two branches are learned for sharpening FG humans and BG details, respectively; while the third one produces global, harmonious results by comprehensively fusing multi-scale deblurring information from the two domains. The proposed model is further endowed with a supervised, human-aware attention mechanism in an end-to-end fashion. It learns a soft mask that encodes FG human information and explicitly drives the FG/BG decoder-branches to focus on their specific domains. To further benefit the research towards Human-aware Image Deblurring, we introduce a large-scale dataset, named HIDE, which consists of 8,422 blurry and sharp image pairs with 65,784 densely annotated FG human bounding boxes. HIDE is specifically built to span a broad range of scenes, human object sizes, motion patterns, and background complexities. Extensive experiments on public benchmarks and our dataset demonstrate that our model performs favorably against the state-of-the-art motion deblurring methods, especially in capturing semantic details.
Vision Meets Drones: Past, Present and Future
Jan 16, 2020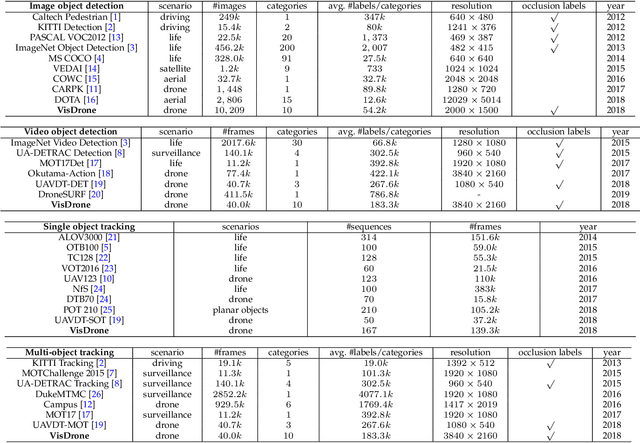
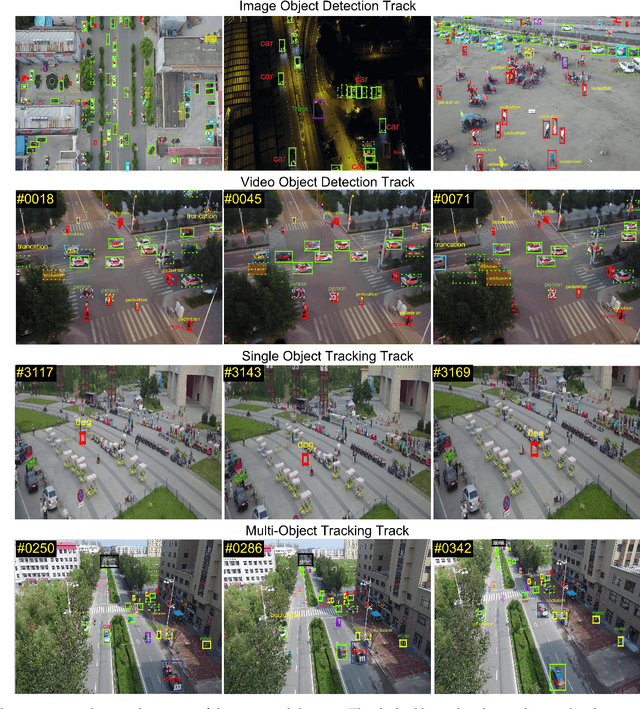
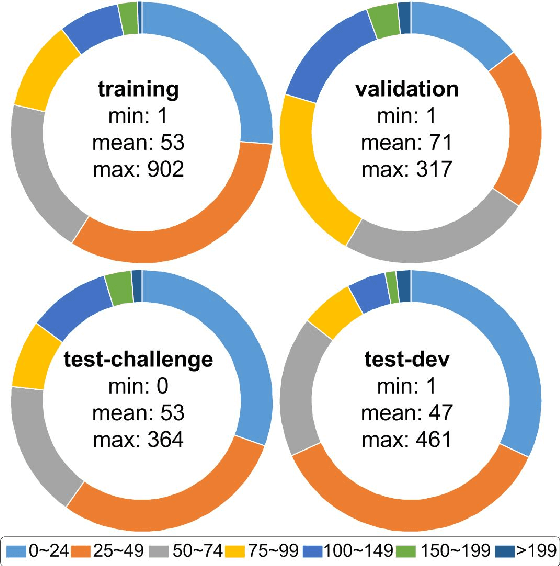
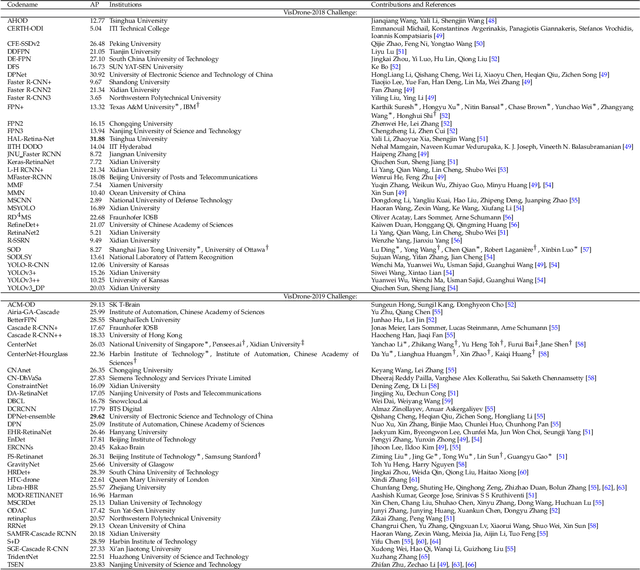
Drones, or general UAVs, equipped with cameras have been fast deployed with a wide range of applications, including agriculture, aerial photography, fast delivery, and surveillance. Consequently, automatic understanding of visual data collected from drones becomes highly demanding, bringing computer vision and drones more and more closely. To promote and track the developments of object detection and tracking algorithms, we have organized two challenge workshops in conjunction with European Conference on Computer Vision (ECCV) 2018, and IEEE International Conference on Computer Vision (ICCV) 2019, attracting more than 100 teams around the world. We provide a large-scale drone captured dataset, VisDrone, which includes four tracks, i.e., (1) image object detection, (2) video object detection, (3) single object tracking, and (4) multi-object tracking. This paper first presents a thorough review of object detection and tracking datasets and benchmarks, and discuss the challenges of collecting large-scale drone-based object detection and tracking datasets with fully manual annotations. After that, we describe our VisDrone dataset, which is captured over various urban/suburban areas of $14$ different cities across China from North to South. Being the largest such dataset ever published, VisDrone enables extensive evaluation and investigation of visual analysis algorithms on the drone platform. We provide a detailed analysis of the current state of the field of large-scale object detection and tracking on drones, and conclude the challenge as well as propose future directions and improvements. We expect the benchmark largely boost the research and development in video analysis on drone platforms. All the datasets and experimental results can be downloaded from the website: https://github.com/VisDrone/VisDrone-Dataset.
MFPN: A Novel Mixture Feature Pyramid Network of Multiple Architectures for Object Detection
Dec 20, 2019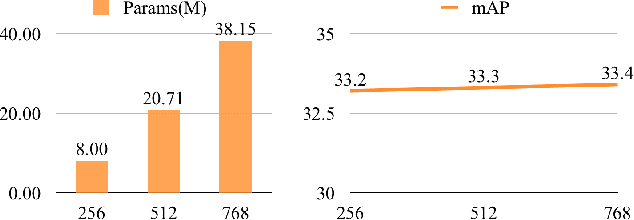
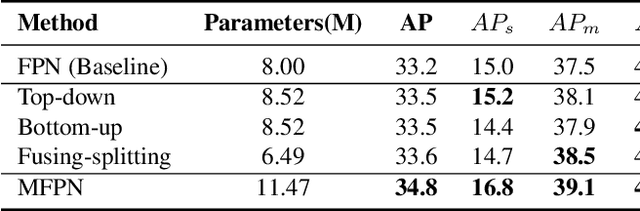
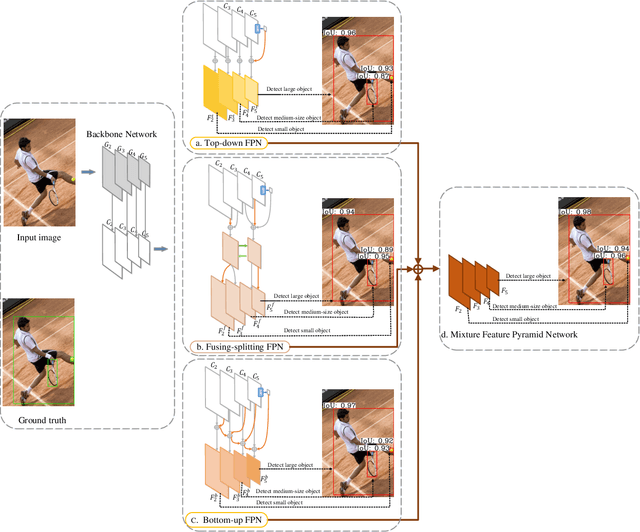
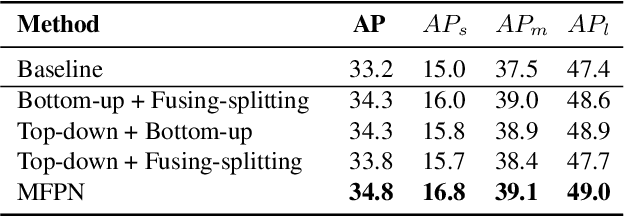
Feature pyramids are widely exploited in many detectors to solve the scale variation problem for object detection. In this paper, we first investigate the Feature Pyramid Network (FPN) architectures and briefly categorize them into three typical fashions: top-down, bottom-up and fusing-splitting, which have their own merits for detecting small objects, large objects, and medium-sized objects, respectively. Further, we design three FPNs of different architectures and propose a novel Mixture Feature Pyramid Network (MFPN) which inherits the merits of all these three kinds of FPNs, by assembling the three kinds of FPNs in a parallel multi-branch architecture and mixing the features. MFPN can significantly enhance both one-stage and two-stage FPN-based detectors with about 2 percent Average Precision(AP) increment on the MS-COCO benchmark, at little sacrifice in running time latency. By simply assembling MFPN with the one-stage and two-stage baseline detectors, we achieve competitive single-model detection results on the COCO detection benchmark without bells and whistles.
Semantic-Aware Label Placement for Augmented Reality in Street View
Dec 15, 2019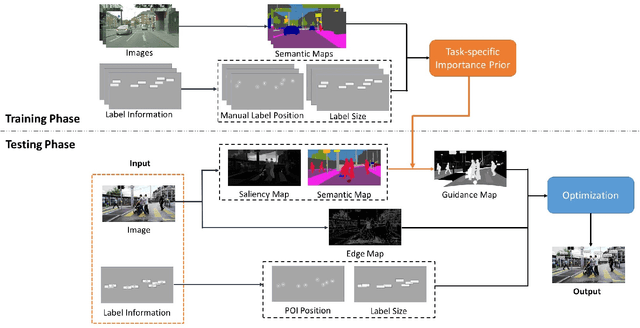
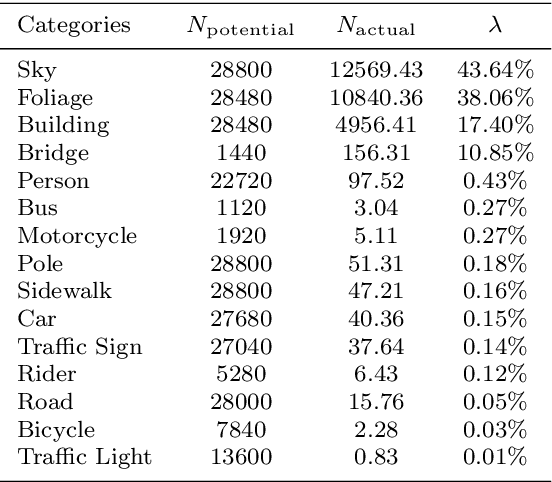
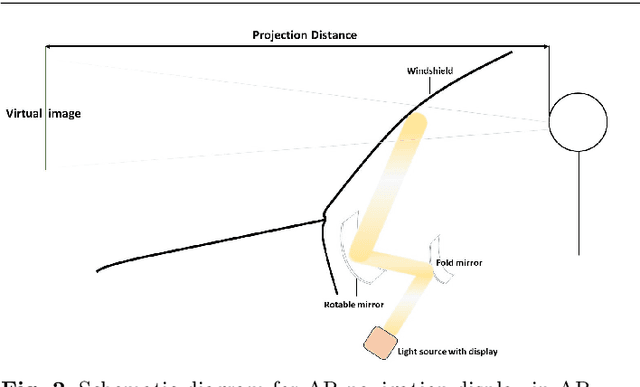
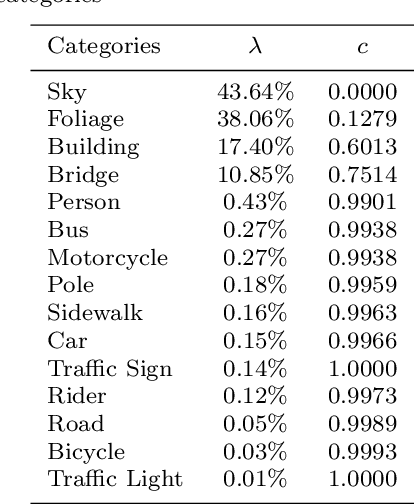
In an augmented reality (AR) application, placing labels in a manner that is clear and readable without occluding the critical information from the real-world can be a challenging problem. This paper introduces a label placement technique for AR used in street view scenarios. We propose a semantic-aware task-specific label placement method by identifying potentially important image regions through a novel feature map, which we refer to as guidance map. Given an input image, its saliency information, semantic information and the task-specific importance prior are integrated into the guidance map for our labeling task. To learn the task prior, we created a label placement dataset with the users' labeling preferences, as well as use it for evaluation. Our solution encodes the constraints for placing labels in an optimization problem to obtain the final label layout, and the labels will be placed in appropriate positions to reduce the chances of overlaying important real-world objects in street view AR scenarios. The experimental validation shows clearly the benefits of our method over previous solutions in the AR street view navigation and similar applications.