 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePDCNet: a benchmark and general deep learning framework for activity prediction of peptide-drug conjugates
Jun 15, 2025Peptide-drug conjugates (PDCs) represent a promising therapeutic avenue for human diseases, particularly in cancer treatment. Systematic elucidation of structure-activity relationships (SARs) and accurate prediction of the activity of PDCs are critical for the rational design and optimization of these conjugates. To this end, we carefully design and construct a benchmark PDCs dataset compiled from literature-derived collections and PDCdb database, and then develop PDCNet, the first unified deep learning framework for forecasting the activity of PDCs. The architecture systematically captures the complex factors underlying anticancer decisions of PDCs in real-word scenarios through a multi-level feature fusion framework that collaboratively characterizes and learns the features of peptides, linkers, and payloads. Leveraging a curated PDCs benchmark dataset, comprehensive evaluation results show that PDCNet demonstrates superior predictive capability, with the highest AUC, F1, MCC and BA scores of 0.9213, 0.7656, 0.7071 and 0.8388 for the test set, outperforming eight established traditional machine learning models. Multi-level validations, including 5-fold cross-validation, threshold testing, ablation studies, model interpretability analysis and external independent testing, further confirm the superiority, robustness, and usability of the PDCNet architecture. We anticipate that PDCNet represents a novel paradigm, incorporating both a benchmark dataset and advanced models, which can accelerate the design and discovery of new PDC-based therapeutic agents.
ADCNet: a unified framework for predicting the activity of antibody-drug conjugates
Jan 17, 2024



Antibody-drug conjugate (ADC) has revolutionized the field of cancer treatment in the era of precision medicine due to their ability to precisely target cancer cells and release highly effective drug. Nevertheless, the realization of rational design of ADC is very difficult because the relationship between their structures and activities is difficult to understand. In the present study, we introduce a unified deep learning framework called ADCNet to help design potential ADCs. The ADCNet highly integrates the protein representation learning language model ESM-2 and small-molecule representation learning language model FG-BERT models to achieve activity prediction through learning meaningful features from antigen and antibody protein sequences of ADC, SMILES strings of linker and payload, and drug-antibody ratio (DAR) value. Based on a carefully designed and manually tailored ADC data set, extensive evaluation results reveal that ADCNet performs best on the test set compared to baseline machine learning models across all evaluation metrics. For example, it achieves an average prediction accuracy of 87.12%, a balanced accuracy of 0.8689, and an area under receiver operating characteristic curve of 0.9293 on the test set. In addition, cross-validation, ablation experiments, and external independent testing results further prove the stability, advancement, and robustness of the ADCNet architecture. For the convenience of the community, we develop the first online platform (https://ADCNet.idruglab.cn) for the prediction of ADCs activity based on the optimal ADCNet model, and the source code is publicly available at https://github.com/idrugLab/ADCNet.
Improving Human Annotation in Single Object Tracking
Nov 07, 2019

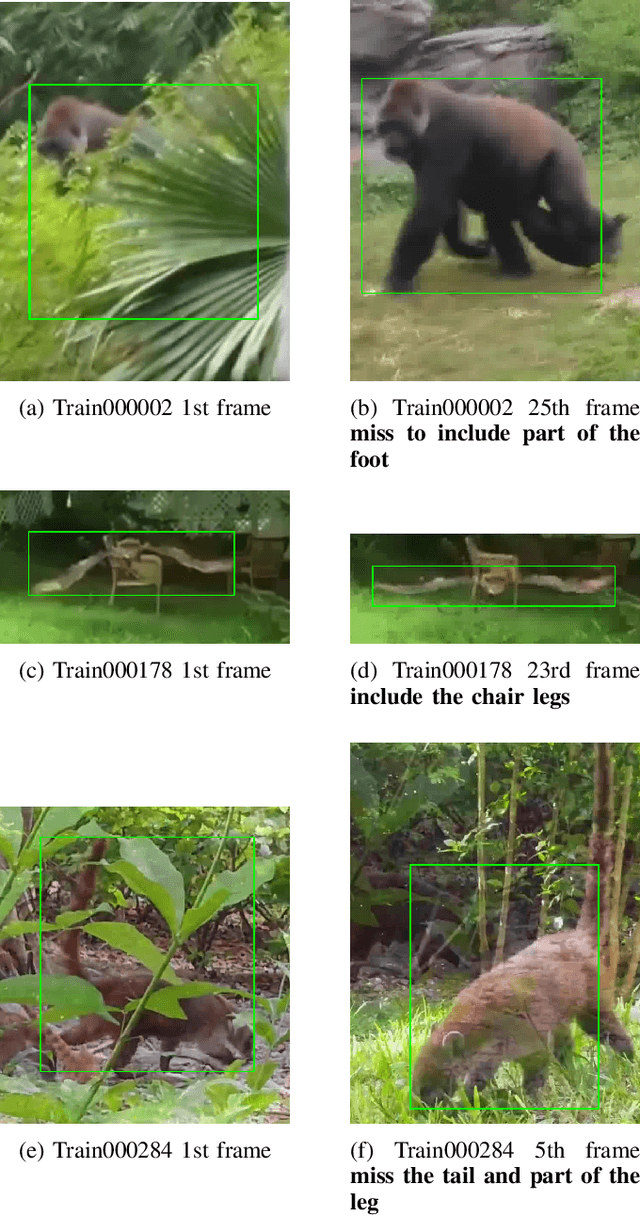
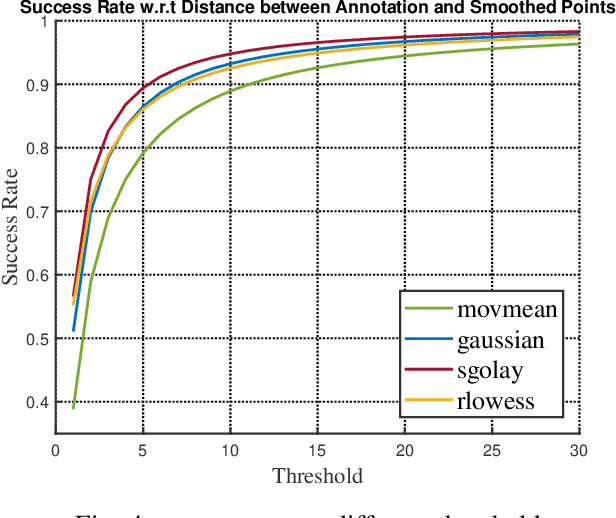
Human annotation is always considered as ground truth in video object tracking tasks. It is used in both training and evaluation purposes. Thus, ensuring its high quality is an important task for the success of trackers and evaluations between them. In this paper, we give a qualitative and quantitative analysis of the existing human annotations. We show that human annotation tends to be non-smooth and is prone to partial visibility and deformation. We propose a smoothing trajectory strategy with the ability to handle moving scenes. We use a two-step adaptive image alignment algorithm to find the canonical view of the video sequence. We then use different techniques to smooth the trajectories at certain degree. Once we convert back to the original image coordination, we can compare with the human annotation. With the experimental results, we can get more consistent trajectories. At a certain degree, it can also slightly improve the trained model. If go beyond a certain threshold, the smoothing error will start eating up the benefit. Overall, our method could help extrapolate the missing annotation frames or identify and correct human annotation outliers as well as help improve the training data quality.