 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast IR Drop Estimation with Machine Learning
Nov 26, 2020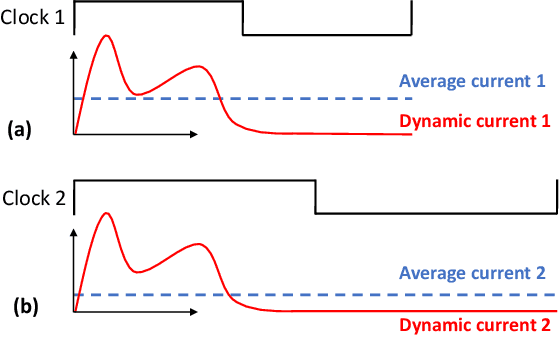
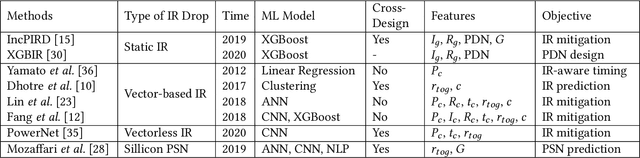
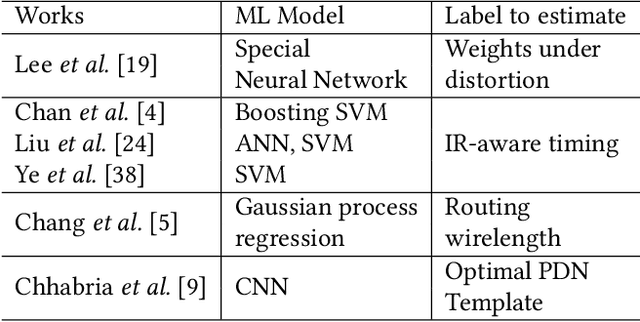

IR drop constraint is a fundamental requirement enforced in almost all chip designs. However, its evaluation takes a long time, and mitigation techniques for fixing violations may require numerous iterations. As such, fast and accurate IR drop prediction becomes critical for reducing design turnaround time. Recently, machine learning (ML) techniques have been actively studied for fast IR drop estimation due to their promise and success in many fields. These studies target at various design stages with different emphasis, and accordingly, different ML algorithms are adopted and customized. This paper provides a review to the latest progress in ML-based IR drop estimation techniques. It also serves as a vehicle for discussing some general challenges faced by ML applications in electronics design automation (EDA), and demonstrating how to integrate ML models with conventional techniques for the better efficiency of EDA tools.
DVERGE: Diversifying Vulnerabilities for Enhanced Robust Generation of Ensembles
Oct 18, 2020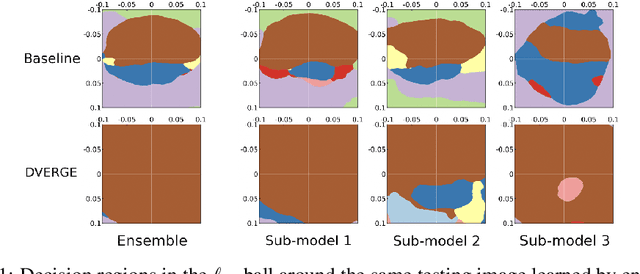

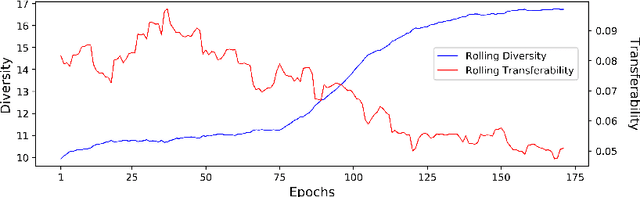

Recent research finds CNN models for image classification demonstrate overlapped adversarial vulnerabilities: adversarial attacks can mislead CNN models with small perturbations, which can effectively transfer between different models trained on the same dataset. Adversarial training, as a general robustness improvement technique, eliminates the vulnerability in a single model by forcing it to learn robust features. The process is hard, often requires models with large capacity, and suffers from significant loss on clean data accuracy. Alternatively, ensemble methods are proposed to induce sub-models with diverse outputs against a transfer adversarial example, making the ensemble robust against transfer attacks even if each sub-model is individually non-robust. Only small clean accuracy drop is observed in the process. However, previous ensemble training methods are not efficacious in inducing such diversity and thus ineffective on reaching robust ensemble. We propose DVERGE, which isolates the adversarial vulnerability in each sub-model by distilling non-robust features, and diversifies the adversarial vulnerability to induce diverse outputs against a transfer attack. The novel diversity metric and training procedure enables DVERGE to achieve higher robustness against transfer attacks comparing to previous ensemble methods, and enables the improved robustness when more sub-models are added to the ensemble. The code of this work is available at https://github.com/zjysteven/DVERGE
Reinforcement Learning-based Black-Box Evasion Attacks to Link Prediction in Dynamic Graphs
Sep 12, 2020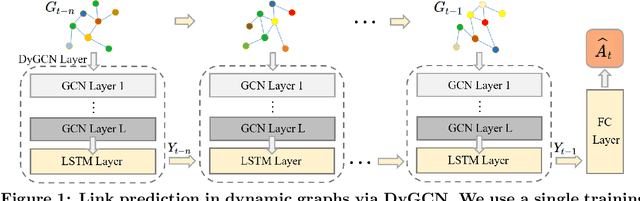
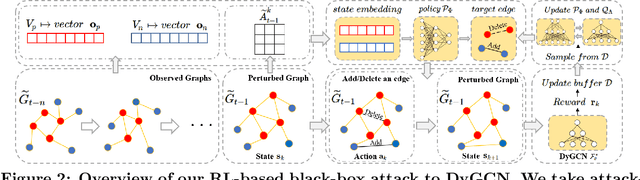
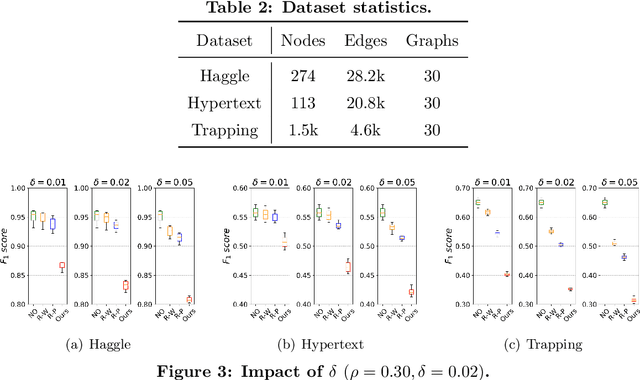
Link prediction in dynamic graphs (LPDG) is an important research problem that has diverse applications such as online recommendations, studies on disease contagion, organizational studies, etc. Various LPDG methods based on graph embedding and graph neural networks have been recently proposed and achieved state-of-the-art performance. In this paper, we study the vulnerability of LPDG methods and propose the first practical black-box evasion attack. Specifically, given a trained LPDG model, our attack aims to perturb the graph structure, without knowing to model parameters, model architecture, etc., such that the LPDG model makes as many wrong predicted links as possible. We design our attack based on a stochastic policy-based RL algorithm. Moreover, we evaluate our attack on three real-world graph datasets from different application domains. Experimental results show that our attack is both effective and efficient.
Evasion Attacks to Graph Neural Networks via Influence Function
Sep 12, 2020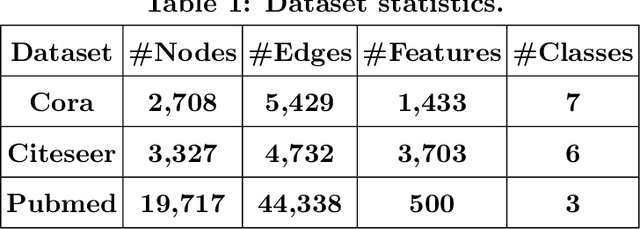
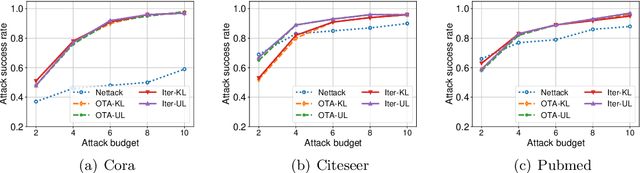
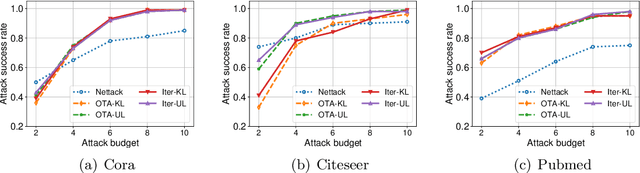

Graph neural networks (GNNs) have achieved state-of-the-art performance in many graph-related tasks, e.g., node classification. However, recent works show that GNNs are vulnerable to evasion attacks, i.e., an attacker can slightly perturb the graph structure to fool GNN models. Existing evasion attacks to GNNs have several key drawbacks: 1) they are limited to attack two-layer GNNs; 2) they are not efficient; or/and 3) they need to know GNN model parameters. We address the above drawbacks in this paper and propose an influence-based evasion attack against GNNs. Specifically, we first introduce two influence functions, i.e., feature-label influence and label influence, that are defined on GNNs and label propagation (LP), respectively. Then, we build a strong connection between GNNs and LP in terms of influence. Next, we reformulate the evasion attack against GNNs to be related to calculating label influence on LP, which is applicable to multi-layer GNNs and does not need to know the GNN model. We also propose an efficient algorithm to calculate label influence. Finally, we evaluate our influence-based attack on three benchmark graph datasets. Our experimental results show that, compared to state-of-the-art attack, our attack can achieve comparable attack performance, but has a 5-50x speedup when attacking two-layer GNNs. Moreover, our attack is effective to attack multi-layer GNNs.
LotteryFL: Personalized and Communication-Efficient Federated Learning with Lottery Ticket Hypothesis on Non-IID Datasets
Aug 07, 2020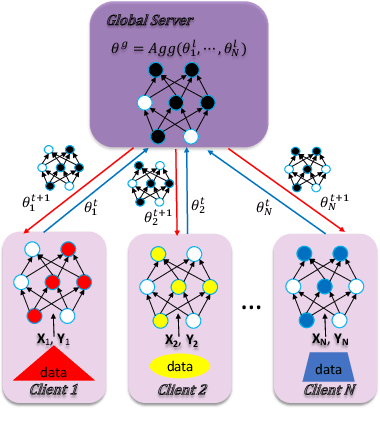
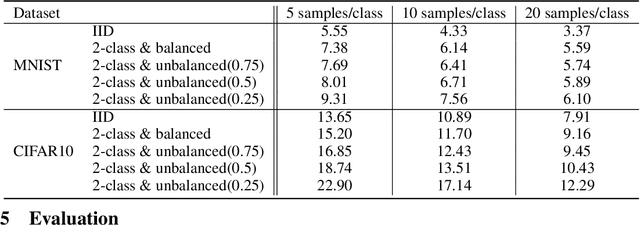
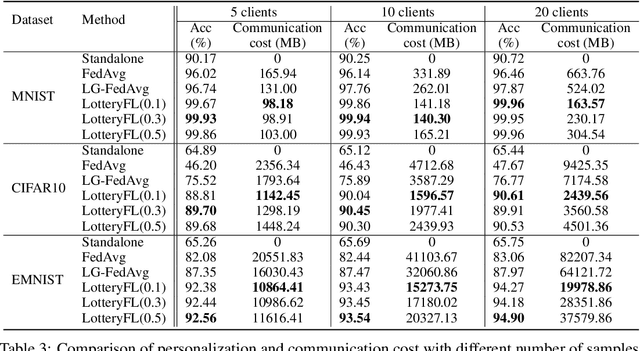
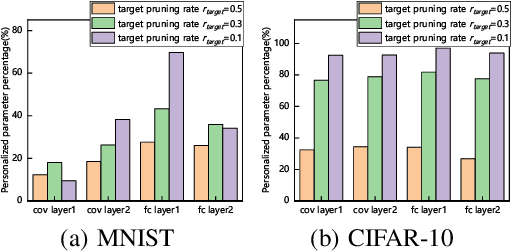
Federated learning is a popular distributed machine learning paradigm with enhanced privacy. Its primary goal is learning a global model that offers good performance for the participants as many as possible. The technology is rapidly advancing with many unsolved challenges, among which statistical heterogeneity (i.e., non-IID) and communication efficiency are two critical ones that hinder the development of federated learning. In this work, we propose LotteryFL -- a personalized and communication-efficient federated learning framework via exploiting the Lottery Ticket hypothesis. In LotteryFL, each client learns a lottery ticket network (i.e., a subnetwork of the base model) by applying the Lottery Ticket hypothesis, and only these lottery networks will be communicated between the server and clients. Rather than learning a shared global model in classic federated learning, each client learns a personalized model via LotteryFL; the communication cost can be significantly reduced due to the compact size of lottery networks. To support the training and evaluation of our framework, we construct non-IID datasets based on MNIST, CIFAR-10 and EMNIST by taking feature distribution skew, label distribution skew and quantity skew into consideration. Experiments on these non-IID datasets demonstrate that LotteryFL significantly outperforms existing solutions in terms of personalization and communication cost.
NASGEM: Neural Architecture Search via Graph Embedding Method
Jul 08, 2020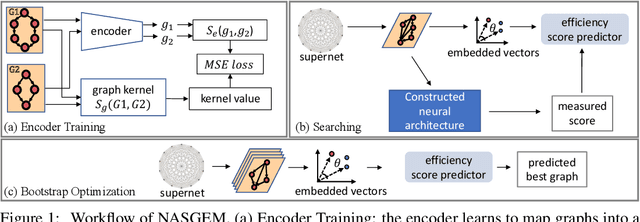
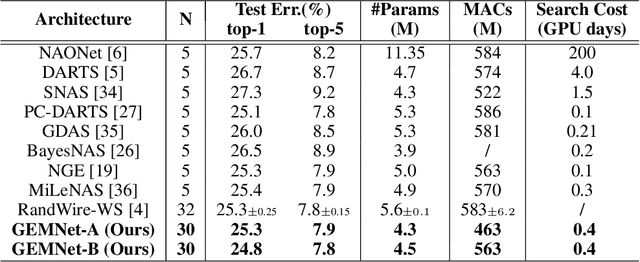
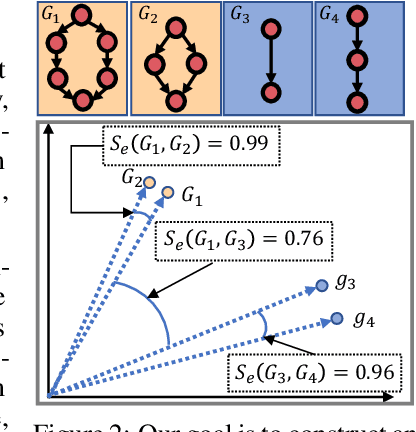
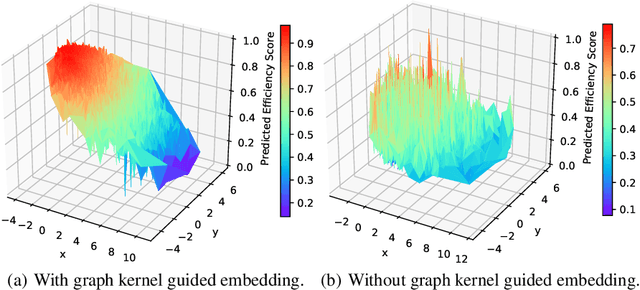
Neural Architecture Search (NAS) automates and prospers the design of neural networks. Recent studies show that mapping the discrete neural architecture search space into a continuous space which is more compact, more representative, and easier to optimize can significantly reduce the exploration cost. However, existing differentiable methods cannot preserve the graph information when projecting a neural architecture into a continuous space, causing inaccuracy and/or reduced representation capability in the mapped space. Moreover, existing methods can explore only a very limited inner-cell search space due to the cell representation limitation or poor scalability. To enable quick search of more sophisticated neural architectures while preserving graph information, we propose NASGEM which stands for Neural Architecture Search via Graph Embedding Method. NASGEM is driven by a novel graph embedding method integrated with similarity estimation to capture the inner-cell information in the discrete space. Thus, NASGEM is able to search a wider space (e.g., 30 nodes in a cell). By precisely estimating the graph distance, NASGEM can efficiently explore a large amount of candidate cells to enable a more flexible cell design while still keeping the search cost low. GEMNet, which is a set of networks discovered by NASGEM, has higher accuracy while less parameters (up to 62% less) and Multiply-Accumulates (up to 20.7% less) compared to networks crafted by existing differentiable search methods. Our ablation study on NASBench-101 further validates the effectiveness of the proposed graph embedding method, which is complementary to many existing NAS approaches and can be combined to achieve better performance.
Defending against GAN-based Deepfake Attacks via Transformation-aware Adversarial Faces
Jun 12, 2020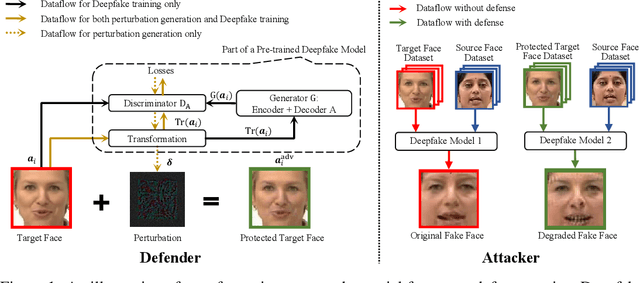
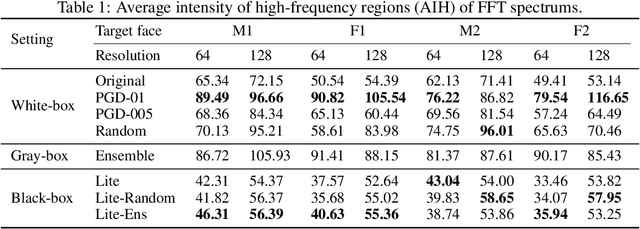

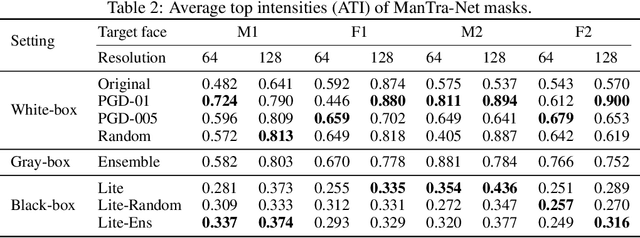
Deepfake represents a category of face-swapping attacks that leverage machine learning models such as autoencoders or generative adversarial networks. Although the concept of the face-swapping is not new, its recent technical advances make fake content (e.g., images, videos) more realistic and imperceptible to Humans. Various detection techniques for Deepfake attacks have been explored. These methods, however, are passive measures against Deepfakes as they are mitigation strategies after the high-quality fake content is generated. More importantly, we would like to think ahead of the attackers with robust defenses. This work aims to take an offensive measure to impede the generation of high-quality fake images or videos. Specifically, we propose to use novel transformation-aware adversarially perturbed faces as a defense against GAN-based Deepfake attacks. Different from the naive adversarial faces, our proposed approach leverages differentiable random image transformations during the generation. We also propose to use an ensemble-based approach to enhance the defense robustness against GAN-based Deepfake variants under the black-box setting. We show that training a Deepfake model with adversarial faces can lead to a significant degradation in the quality of synthesized faces. This degradation is twofold. On the one hand, the quality of the synthesized faces is reduced with more visual artifacts such that the synthesized faces are more obviously fake or less convincing to human observers. On the other hand, the synthesized faces can easily be detected based on various metrics.
PENNI: Pruned Kernel Sharing for Efficient CNN Inference
May 14, 2020
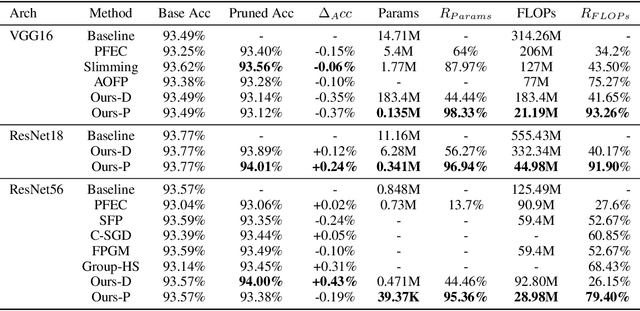
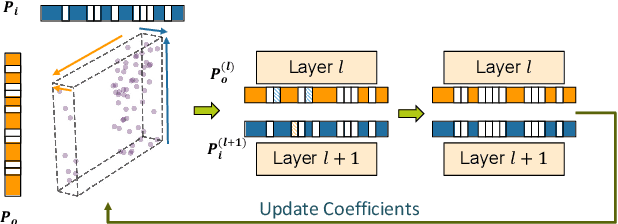
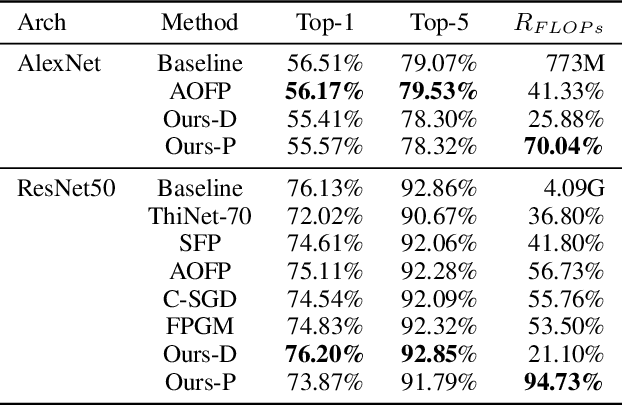
Although state-of-the-art (SOTA) CNNs achieve outstanding performance on various tasks, their high computation demand and massive number of parameters make it difficult to deploy these SOTA CNNs onto resource-constrained devices. Previous works on CNN acceleration utilize low-rank approximation of the original convolution layers to reduce computation cost. However, these methods are very difficult to conduct upon sparse models, which limits execution speedup since redundancies within the CNN model are not fully exploited. We argue that kernel granularity decomposition can be conducted with low-rank assumption while exploiting the redundancy within the remaining compact coefficients. Based on this observation, we propose PENNI, a CNN model compression framework that is able to achieve model compactness and hardware efficiency simultaneously by (1) implementing kernel sharing in convolution layers via a small number of basis kernels and (2) alternately adjusting bases and coefficients with sparse constraints. Experiments show that we can prune 97% parameters and 92% FLOPs on ResNet18 CIFAR10 with no accuracy loss, and achieve 44% reduction in run-time memory consumption and a 53% reduction in inference latency.
Learning Low-rank Deep Neural Networks via Singular Vector Orthogonality Regularization and Singular Value Sparsification
Apr 20, 2020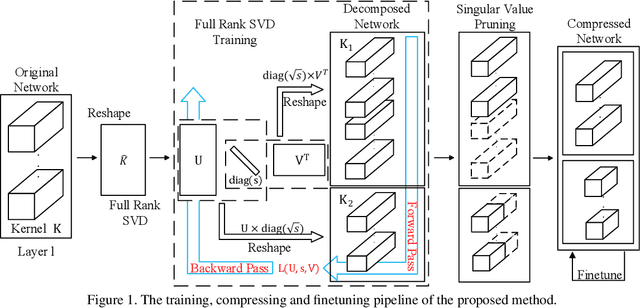
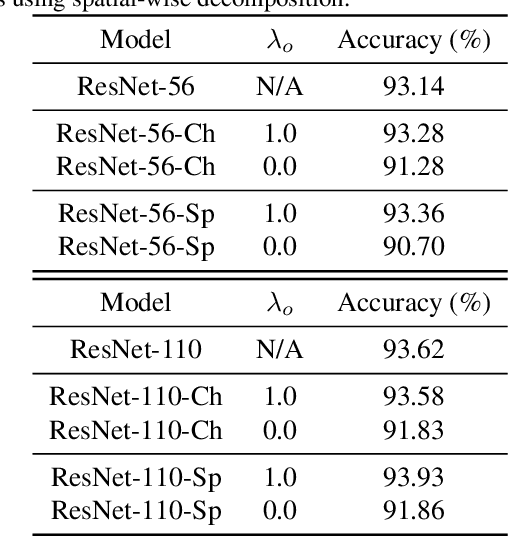
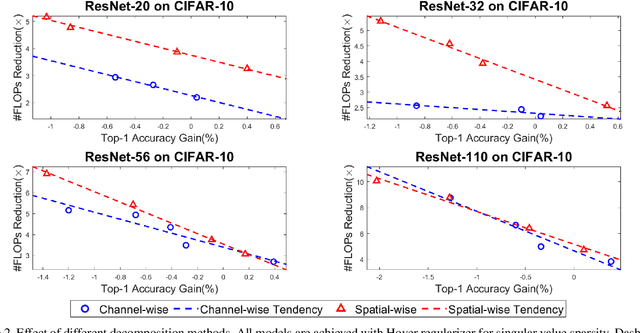
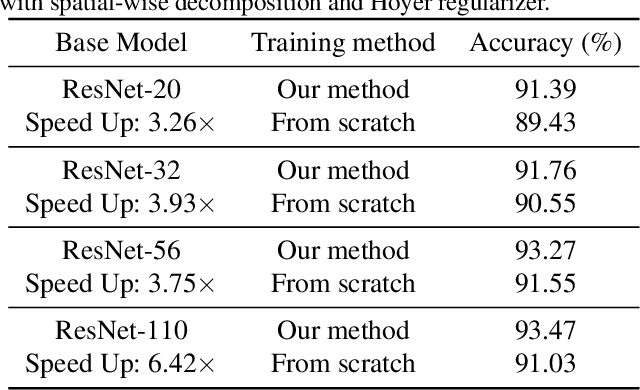
Modern deep neural networks (DNNs) often require high memory consumption and large computational loads. In order to deploy DNN algorithms efficiently on edge or mobile devices, a series of DNN compression algorithms have been explored, including factorization methods. Factorization methods approximate the weight matrix of a DNN layer with the multiplication of two or multiple low-rank matrices. However, it is hard to measure the ranks of DNN layers during the training process. Previous works mainly induce low-rank through implicit approximations or via costly singular value decomposition (SVD) process on every training step. The former approach usually induces a high accuracy loss while the latter has a low efficiency. In this work, we propose SVD training, the first method to explicitly achieve low-rank DNNs during training without applying SVD on every step. SVD training first decomposes each layer into the form of its full-rank SVD, then performs training directly on the decomposed weights. We add orthogonality regularization to the singular vectors, which ensure the valid form of SVD and avoid gradient vanishing/exploding. Low-rank is encouraged by applying sparsity-inducing regularizers on the singular values of each layer. Singular value pruning is applied at the end to explicitly reach a low-rank model. We empirically show that SVD training can significantly reduce the rank of DNN layers and achieve higher reduction on computation load under the same accuracy, comparing to not only previous factorization methods but also state-of-the-art filter pruning methods.
Neural Predictor for Neural Architecture Search
Dec 02, 2019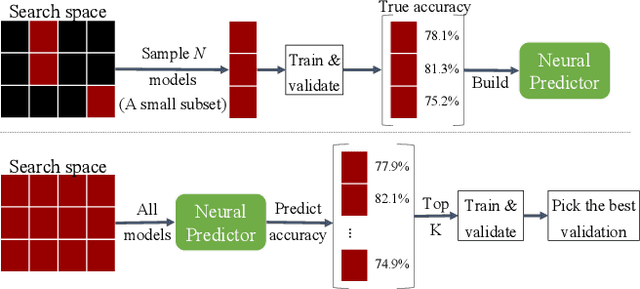
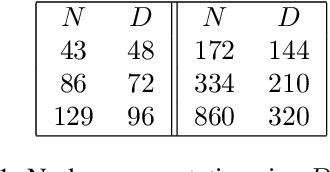

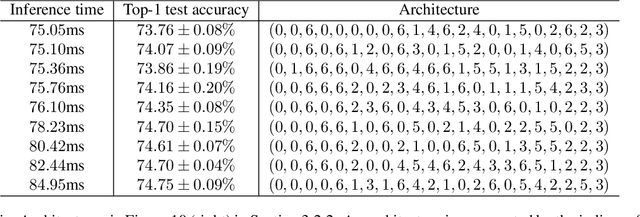
Neural Architecture Search methods are effective but often use complex algorithms to come up with the best architecture. We propose an approach with three basic steps that is conceptually much simpler. First we train N random architectures to generate N (architecture, validation accuracy) pairs and use them to train a regression model that predicts accuracy based on the architecture. Next, we use this regression model to predict the validation accuracies of a large number of random architectures. Finally, we train the top-K predicted architectures and deploy the model with the best validation result. While this approach seems simple, it is more than 20 times as sample efficient as Regularized Evolution on the NASBench-101 benchmark and can compete on ImageNet with more complex approaches based on weight sharing, such as ProxylessNAS.