 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplementation of tangent linear and adjoint models for neural networks based on a compiler library tool
Mar 17, 2026This paper presents TorchNWP, a compilation library tool for the efficient coupling of artificial intelligence components and traditional numerical models. It aims to address the issues of poor cross-language compatibility, insufficient coupling flexibility, and low data transfer efficiency between operational numerical models developed in Fortran and Python-based deep learning frameworks. Based on LibTorch, it optimizes and designs a unified application-layer calling interface, converts deep learning models under the PyTorch framework into a static binary format, and provides C/C++ interfaces. Then, using hybrid Fortran/C/C++ programming, it enables the deployment of deep learning models within numerical models. Integrating TorchNWP into a numerical model only requires compiling it into a callable link library and linking it during the compilation and linking phase to generate the executable. On this basis, tangent linear and adjoint model based on neural networks are implemented at the C/C++ level, which can shield the internal structure of neural network models and simplify the construction process of four-dimensional variational data assimilation systems. Meanwhile, it supports deployment on heterogeneous platforms, is compatible with mainstream neural network models, and enables mapping of different parallel granularities and efficient parallel execution. Using this tool requires minimal code modifications to the original numerical model, thus reducing coupling costs. It can be efficiently integrated into numerical weather prediction models such as CMA-GFS and MCV, and has been applied to the coupling of deep learning-based physical parameterization schemes (e.g., radiation, non-orographic gravity wave drag) and the development of their tangent linear and adjoint models, significantly improving the accuracy and efficiency of numerical weather prediction.
Machine learning based radiative parameterization scheme and its performance in operational reforecast experiments
Jan 20, 2026Radiation is typically the most time-consuming physical process in numerical models. One solution is to use machine learning methods to simulate the radiation process to improve computational efficiency. From an operational standpoint, this study investigates critical limitations inherent to hybrid forecasting frameworks that embed deep neural networks into numerical prediction models, with a specific focus on two fundamental bottlenecks: coupling compatibility and long-term integration stability. A residual convolutional neural network is employed to approximate the Rapid Radiative Transfer Model for General Circulation Models (RRTMG) within the global operational system of China Meteorological Administration. We adopted an offline training and online coupling approach. First, a comprehensive dataset is generated through model simulations, encompassing all atmospheric columns both with and without cloud cover. To ensure the stability of the hybrid model, the dataset is enhanced via experience replay, and additional output constraints based on physical significance are imposed. Meanwhile, a LibTorch-based coupling method is utilized, which is more suitable for real-time operational computations. The hybrid model is capable of performing ten-day integrated forecasts as required. A two-month operational reforecast experiment demonstrates that the machine learning emulator achieves accuracy comparable to that of the traditional physical scheme, while accelerating the computation speed by approximately eightfold.
Reflectance Prediction-based Knowledge Distillation for Robust 3D Object Detection in Compressed Point Clouds
May 23, 2025Regarding intelligent transportation systems for vehicle networking, low-bitrate transmission via lossy point cloud compression is vital for facilitating real-time collaborative perception among vehicles with restricted bandwidth. In existing compression transmission systems, the sender lossily compresses point coordinates and reflectance to generate a transmission code stream, which faces transmission burdens from reflectance encoding and limited detection robustness due to information loss. To address these issues, this paper proposes a 3D object detection framework with reflectance prediction-based knowledge distillation (RPKD). We compress point coordinates while discarding reflectance during low-bitrate transmission, and feed the decoded non-reflectance compressed point clouds into a student detector. The discarded reflectance is then reconstructed by a geometry-based reflectance prediction (RP) module within the student detector for precise detection. A teacher detector with the same structure as student detector is designed for performing reflectance knowledge distillation (RKD) and detection knowledge distillation (DKD) from raw to compressed point clouds. Our RPKD framework jointly trains detectors on both raw and compressed point clouds to improve the student detector's robustness. Experimental results on the KITTI dataset and Waymo Open Dataset demonstrate that our method can boost detection accuracy for compressed point clouds across multiple code rates. Notably, at a low code rate of 2.146 Bpp on the KITTI dataset, our RPKD-PV achieves the highest mAP of 73.6, outperforming existing detection methods with the PV-RCNN baseline.
A Mamba Foundation Model for Time Series Forecasting
Nov 05, 2024



Time series foundation models have demonstrated strong performance in zero-shot learning, making them well-suited for predicting rapidly evolving patterns in real-world applications where relevant training data are scarce. However, most of these models rely on the Transformer architecture, which incurs quadratic complexity as input length increases. To address this, we introduce TSMamba, a linear-complexity foundation model for time series forecasting built on the Mamba architecture. The model captures temporal dependencies through both forward and backward Mamba encoders, achieving high prediction accuracy. To reduce reliance on large datasets and lower training costs, TSMamba employs a two-stage transfer learning process that leverages pretrained Mamba LLMs, allowing effective time series modeling with a moderate training set. In the first stage, the forward and backward backbones are optimized via patch-wise autoregressive prediction; in the second stage, the model trains a prediction head and refines other components for long-term forecasting. While the backbone assumes channel independence to manage varying channel numbers across datasets, a channel-wise compressed attention module is introduced to capture cross-channel dependencies during fine-tuning on specific multivariate datasets. Experiments show that TSMamba's zero-shot performance is comparable to state-of-the-art time series foundation models, despite using significantly less training data. It also achieves competitive or superior full-shot performance compared to task-specific prediction models. The code will be made publicly available.
Boosting 3D Object Detection with Semantic-Aware Multi-Branch Framework
Jul 08, 2024



In autonomous driving, LiDAR sensors are vital for acquiring 3D point clouds, providing reliable geometric information. However, traditional sampling methods of preprocessing often ignore semantic features, leading to detail loss and ground point interference in 3D object detection. To address this, we propose a multi-branch two-stage 3D object detection framework using a Semantic-aware Multi-branch Sampling (SMS) module and multi-view consistency constraints. The SMS module includes random sampling, Density Equalization Sampling (DES) for enhancing distant objects, and Ground Abandonment Sampling (GAS) to focus on non-ground points. The sampled multi-view points are processed through a Consistent KeyPoint Selection (CKPS) module to generate consistent keypoint masks for efficient proposal sampling. The first-stage detector uses multi-branch parallel learning with multi-view consistency loss for feature aggregation, while the second-stage detector fuses multi-view data through a Multi-View Fusion Pooling (MVFP) module to precisely predict 3D objects. The experimental results on KITTI 3D object detection benchmark dataset show that our method achieves excellent detection performance improvement for a variety of backbones, especially for low-performance backbones with the simple network structures.
A Joint Time-frequency Domain Transformer for Multivariate Time Series Forecasting
May 24, 2023To enhance predicting performance while minimizing computational demands, this paper introduces a joint time-frequency domain Transformer (JTFT) for multivariate forecasting. The method exploits the sparsity of time series in the frequency domain using a small number of learnable frequencies to extract temporal dependencies effectively. Alongside the frequency domain representation, a fixed number of the most recent data points are directly encoded in the time domain, bolstering the learning of local relationships and mitigating the adverse effects of non-stationarity. JTFT achieves linear complexity since the length of the internal representation remains independent of the input sequence length. Additionally, a low-rank attention layer is proposed to efficiently capture cross-dimensional dependencies and prevent performance degradation due to the entanglement of temporal and channel-wise modeling. Experiments conducted on six real-world datasets demonstrate that JTFT outperforms state-of-the-art methods.
NAMSG: An Efficient Method For Training Neural Networks
May 23, 2019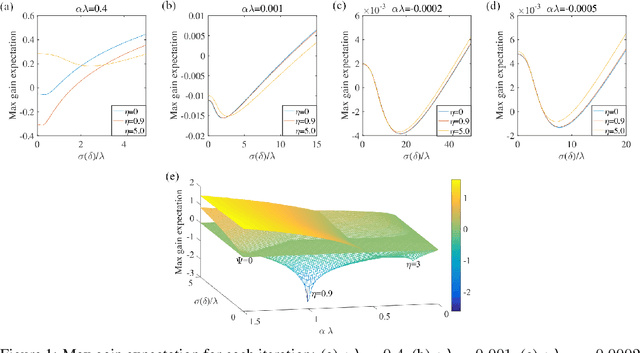
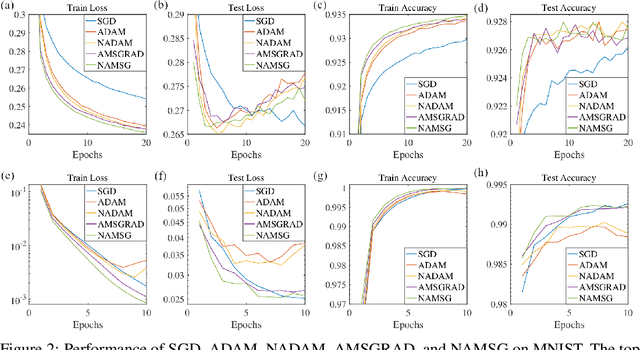
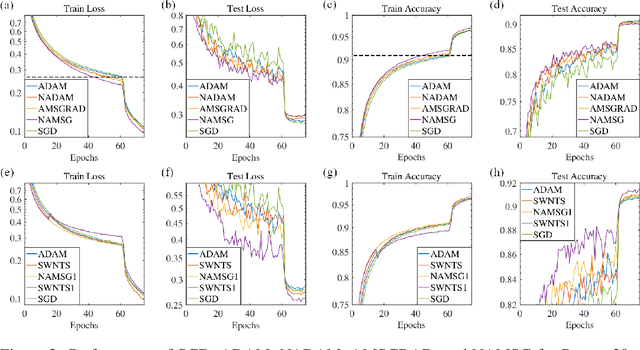
We introduce NAMSG, an adaptive first-order algorithm for training neural networks. The method is efficient in computation and memory, and is straightforward to implement. It computes the gradients at configurable remote observation points, in order to expedite the convergence by adjusting the step size for directions with different curvatures in the stochastic setting. It also scales the updating vector elementwise by a nonincreasing preconditioner to take the advantages of AMSGRAD. We analyze the convergence properties for both convex and nonconvex problems by modeling the training process as a dynamic system, and provide a guideline to select the observation distance without grid search. A data-dependent regret bound is proposed to guarantee the convergence in the convex setting. Experiments demonstrate that NAMSG works well in practical problems and compares favorably to popular adaptive methods, such as ADAM, NADAM, and AMSGRAD.