 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling and Performance Analysis for Semantic Communications Based on Empirical Results
Apr 29, 2025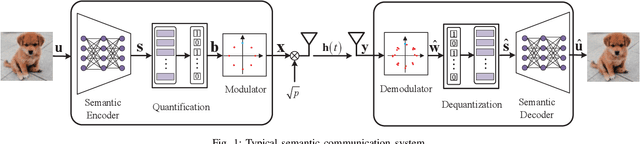
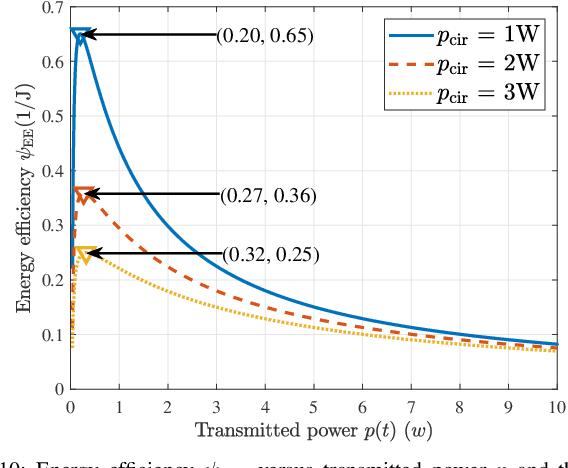
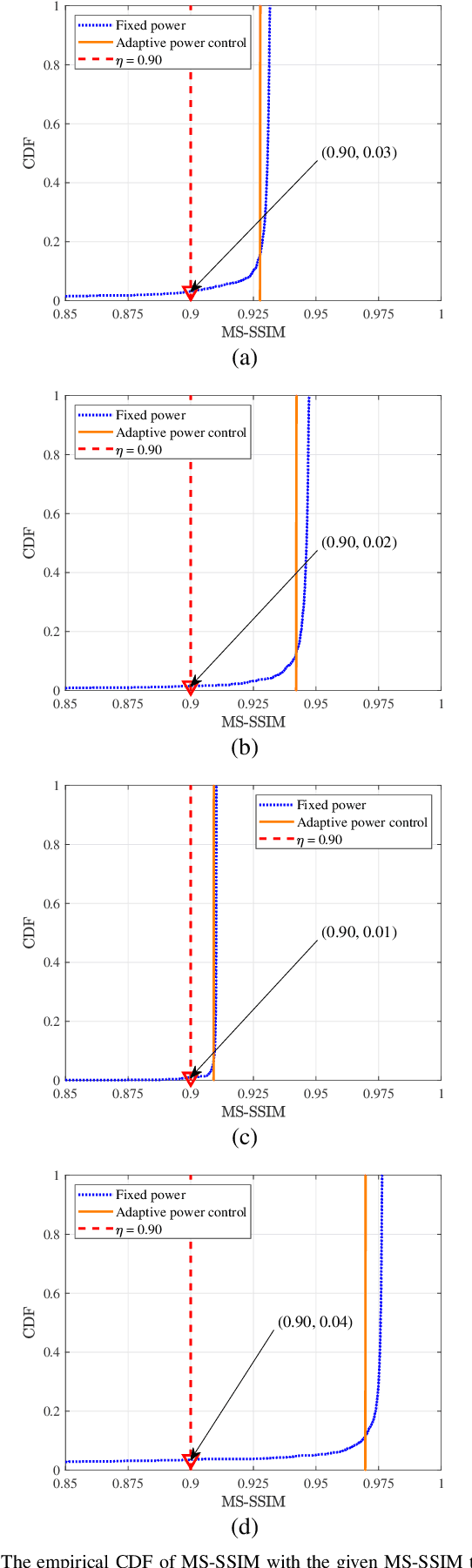
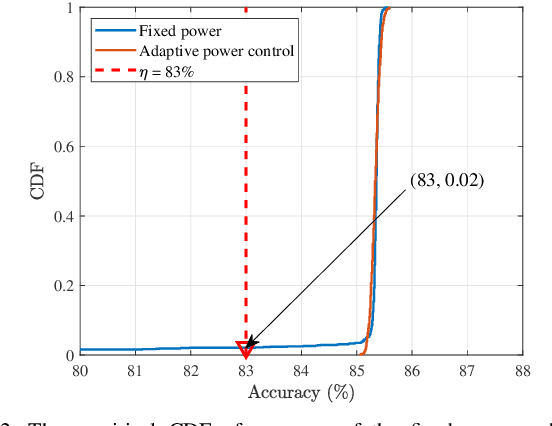
Due to the black-box characteristics of deep learning based semantic encoders and decoders, finding a tractable method for the performance analysis of semantic communications is a challenging problem. In this paper, we propose an Alpha-Beta-Gamma (ABG) formula to model the relationship between the end-to-end measurement and SNR, which can be applied for both image reconstruction tasks and inference tasks. Specifically, for image reconstruction tasks, the proposed ABG formula can well fit the commonly used DL networks, such as SCUNet, and Vision Transformer, for semantic encoding with the multi scale-structural similarity index measure (MS-SSIM) measurement. Furthermore, we find that the upper bound of the MS-SSIM depends on the number of quantized output bits of semantic encoders, and we also propose a closed-form expression to fit the relationship between the MS-SSIM and quantized output bits. To the best of our knowledge, this is the first theoretical expression between end-to-end performance metrics and SNR for semantic communications. Based on the proposed ABG formula, we investigate an adaptive power control scheme for semantic communications over random fading channels, which can effectively guarantee quality of service (QoS) for semantic communications, and then design the optimal power allocation scheme to maximize the energy efficiency of the semantic communication system. Furthermore, by exploiting the bisection algorithm, we develop the power allocation scheme to maximize the minimum QoS of multiple users for OFDMA downlink semantic communication Extensive simulations verify the effectiveness and superiority of the proposed ABG formula and power allocation schemes.
Visual Environment-Interactive Planning for Embodied Complex-Question Answering
Apr 01, 2025



This study focuses on Embodied Complex-Question Answering task, which means the embodied robot need to understand human questions with intricate structures and abstract semantics. The core of this task lies in making appropriate plans based on the perception of the visual environment. Existing methods often generate plans in a once-for-all manner, i.e., one-step planning. Such approach rely on large models, without sufficient understanding of the environment. Considering multi-step planning, the framework for formulating plans in a sequential manner is proposed in this paper. To ensure the ability of our framework to tackle complex questions, we create a structured semantic space, where hierarchical visual perception and chain expression of the question essence can achieve iterative interaction. This space makes sequential task planning possible. Within the framework, we first parse human natural language based on a visual hierarchical scene graph, which can clarify the intention of the question. Then, we incorporate external rules to make a plan for current step, weakening the reliance on large models. Every plan is generated based on feedback from visual perception, with multiple rounds of interaction until an answer is obtained. This approach enables continuous feedback and adjustment, allowing the robot to optimize its action strategy. To test our framework, we contribute a new dataset with more complex questions. Experimental results demonstrate that our approach performs excellently and stably on complex tasks. And also, the feasibility of our approach in real-world scenarios has been established, indicating its practical applicability.
Towards Agentic AI Networking in 6G: A Generative Foundation Model-as-Agent Approach
Mar 20, 2025The promising potential of AI and network convergence in improving networking performance and enabling new service capabilities has recently attracted significant interest. Existing network AI solutions, while powerful, are mainly built based on the close-loop and passive learning framework, resulting in major limitations in autonomous solution finding and dynamic environmental adaptation. Agentic AI has recently been introduced as a promising solution to address the above limitations and pave the way for true generally intelligent and beneficial AI systems. The key idea is to create a networking ecosystem to support a diverse range of autonomous and embodied AI agents in fulfilling their goals. In this paper, we focus on the novel challenges and requirements of agentic AI networking. We propose AgentNet, a novel framework for supporting interaction, collaborative learning, and knowledge transfer among AI agents. We introduce a general architectural framework of AgentNet and then propose a generative foundation model (GFM)-based implementation in which multiple GFM-as-agents have been created as an interactive knowledge-base to bootstrap the development of embodied AI agents according to different task requirements and environmental features. We consider two application scenarios, digital-twin-based industrial automation and metaverse-based infotainment system, to describe how to apply AgentNet for supporting efficient task-driven collaboration and interaction among AI agents.
Triad: Empowering LMM-based Anomaly Detection with Vision Expert-guided Visual Tokenizer and Manufacturing Process
Mar 17, 2025



Although recent methods have tried to introduce large multimodal models (LMMs) into industrial anomaly detection (IAD), their generalization in the IAD field is far inferior to that for general purposes. We summarize the main reasons for this gap into two aspects. On one hand, general-purpose LMMs lack cognition of defects in the visual modality, thereby failing to sufficiently focus on defect areas. Therefore, we propose to modify the AnyRes structure of the LLaVA model, providing the potential anomalous areas identified by existing IAD models to the LMMs. On the other hand, existing methods mainly focus on identifying defects by learning defect patterns or comparing with normal samples, yet they fall short of understanding the causes of these defects. Considering that the generation of defects is closely related to the manufacturing process, we propose a manufacturing-driven IAD paradigm. An instruction-tuning dataset for IAD (InstructIAD) and a data organization approach for Chain-of-Thought with manufacturing (CoT-M) are designed to leverage the manufacturing process for IAD. Based on the above two modifications, we present Triad, a novel LMM-based method incorporating an expert-guided region-of-interest tokenizer and manufacturing process for industrial anomaly detection. Extensive experiments show that our Triad not only demonstrates competitive performance against current LMMs but also achieves further improved accuracy when equipped with manufacturing processes. Source code, training data, and pre-trained models will be publicly available at https://github.com/tzjtatata/Triad.
EgoSplat: Open-Vocabulary Egocentric Scene Understanding with Language Embedded 3D Gaussian Splatting
Mar 14, 2025



Egocentric scenes exhibit frequent occlusions, varied viewpoints, and dynamic interactions compared to typical scene understanding tasks. Occlusions and varied viewpoints can lead to multi-view semantic inconsistencies, while dynamic objects may act as transient distractors, introducing artifacts into semantic feature modeling. To address these challenges, we propose EgoSplat, a language-embedded 3D Gaussian Splatting framework for open-vocabulary egocentric scene understanding. A multi-view consistent instance feature aggregation method is designed to leverage the segmentation and tracking capabilities of SAM2 to selectively aggregate complementary features across views for each instance, ensuring precise semantic representation of scenes. Additionally, an instance-aware spatial-temporal transient prediction module is constructed to improve spatial integrity and temporal continuity in predictions by incorporating spatial-temporal associations across multi-view instances, effectively reducing artifacts in the semantic reconstruction of egocentric scenes. EgoSplat achieves state-of-the-art performance in both localization and segmentation tasks on two datasets, outperforming existing methods with a 8.2% improvement in localization accuracy and a 3.7% improvement in segmentation mIoU on the ADT dataset, and setting a new benchmark in open-vocabulary egocentric scene understanding. The code will be made publicly available.
ACMo: Attribute Controllable Motion Generation
Mar 14, 2025Attributes such as style, fine-grained text, and trajectory are specific conditions for describing motion. However, existing methods often lack precise user control over motion attributes and suffer from limited generalizability to unseen motions. This work introduces an Attribute Controllable Motion generation architecture, to address these challenges via decouple any conditions and control them separately. Firstly, we explored the Attribute Diffusion Model to imporve text-to-motion performance via decouple text and motion learning, as the controllable model relies heavily on the pre-trained model. Then, we introduce Motion Adpater to quickly finetune previously unseen motion patterns. Its motion prompts inputs achieve multimodal text-to-motion generation that captures user-specified styles. Finally, we propose a LLM Planner to bridge the gap between unseen attributes and dataset-specific texts via local knowledage for user-friendly interaction. Our approach introduces the capability for motion prompts for stylize generation, enabling fine-grained and user-friendly attribute control while providing performance comparable to state-of-the-art methods. Project page: https://mjwei3d.github.io/ACMo/
Spatio-Temporal Progressive Attention Model for EEG Classification in Rapid Serial Visual Presentation Task
Feb 02, 2025



As a type of multi-dimensional sequential data, the spatial and temporal dependencies of electroencephalogram (EEG) signals should be further investigated. Thus, in this paper, we propose a novel spatial-temporal progressive attention model (STPAM) to improve EEG classification in rapid serial visual presentation (RSVP) tasks. STPAM first adopts three distinct spatial experts to learn the spatial topological information of brain regions progressively, which is used to minimize the interference of irrelevant brain regions. Concretely, the former expert filters out EEG electrodes in the relative brain regions to be used as prior knowledge for the next expert, ensuring that the subsequent experts gradually focus their attention on information from significant EEG electrodes. This process strengthens the effect of the important brain regions. Then, based on the above-obtained feature sequence with spatial information, three temporal experts are adopted to capture the temporal dependence by progressively assigning attention to the crucial EEG slices. Except for the above EEG classification method, in this paper, we build a novel Infrared RSVP EEG Dataset (IRED) which is based on dim infrared images with small targets for the first time, and conduct extensive experiments on it. The results show that our STPAM can achieve better performance than all the compared methods.
Adaptive Progressive Attention Graph Neural Network for EEG Emotion Recognition
Jan 24, 2025In recent years, numerous neuroscientific studies have shown that human emotions are closely linked to specific brain regions, with these regions exhibiting variability across individuals and emotional states. To fully leverage these neural patterns, we propose an Adaptive Progressive Attention Graph Neural Network (APAGNN), which dynamically captures the spatial relationships among brain regions during emotional processing. The APAGNN employs three specialized experts that progressively analyze brain topology. The first expert captures global brain patterns, the second focuses on region-specific features, and the third examines emotion-related channels. This hierarchical approach enables increasingly refined analysis of neural activity. Additionally, a weight generator integrates the outputs of all three experts, balancing their contributions to produce the final predictive label. Extensive experiments on three publicly available datasets (SEED, SEED-IV and MPED) demonstrate that the proposed method enhances EEG emotion recognition performance, achieving superior results compared to baseline methods.
Refinement Module based on Parse Graph of Feature Map for Human Pose Estimation
Jan 19, 2025



Parse graphs of the human body can be obtained in the human brain to help humans complete the human pose estimation (HPE). It contains a hierarchical structure, like a tree structure, and context relations among nodes. Many researchers pre-design the parse graph of body structure, and then design framework for HPE. However, these frameworks are difficulty adapting when encountering situations that differ from the preset human structure. Different from them, we regard the feature map as a whole, similarly to human body, so the feature map can be optimized based on parse graphs and each node feature is learned implicitly instead of explicitly, which means it can flexibly respond to different human body structure. In this paper, we design the Refinement Module based on the Parse Graph of feature map (RMPG), which includes two stages: top-down decomposition and bottom-up combination. In the top-down decomposition stage, the feature map is decomposed into multiple sub-feature maps along the channel and their context relations are calculated to obtain their respective context information. In the bottom-up combination stage, the sub-feature maps and their context information are combined to obtain refined sub-feature maps, and then these refined sub-feature maps are concatenated to obtain the refined feature map. Additionally ,we design a top-down framework by using multiple RMPG modules for HPE, some of which are supervised to obtain context relations among body parts. Our framework achieves excellent results on the COCO keypoint detection, CrowdPose and MPII human pose datasets. More importantly, our experiments also demonstrate the effectiveness of RMPG on different methods, including SimpleBaselines, Hourglass, and ViTPose.
ERVD: An Efficient and Robust ViT-Based Distillation Framework for Remote Sensing Image Retrieval
Dec 24, 2024



ERVD: An Efficient and Robust ViT-Based Distillation Framework for Remote Sensing Image Retrieval