 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasakhaNER: Named Entity Recognition for African Languages
Mar 22, 2021

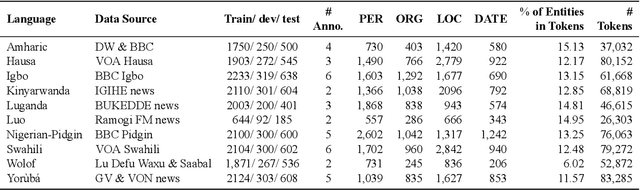
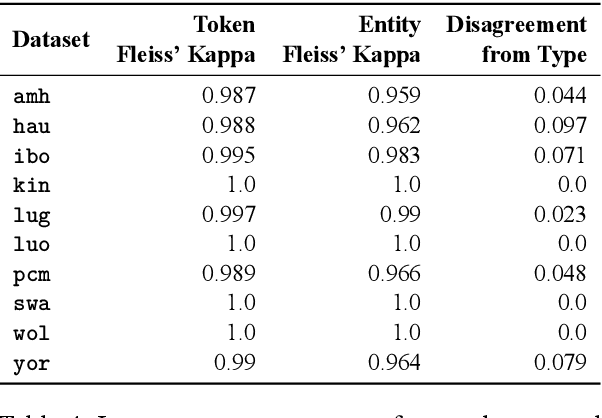
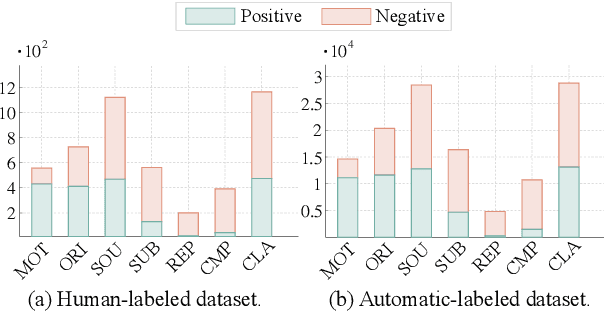
We take a step towards addressing the under-representation of the African continent in NLP research by creating the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages, bringing together a variety of stakeholders. We detail characteristics of the languages to help researchers understand the challenges that these languages pose for NER. We analyze our datasets and conduct an extensive empirical evaluation of state-of-the-art methods across both supervised and transfer learning settings. We release the data, code, and models in order to inspire future research on African NLP.
Meta Back-translation
Feb 15, 2021
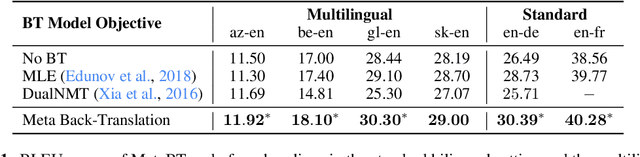
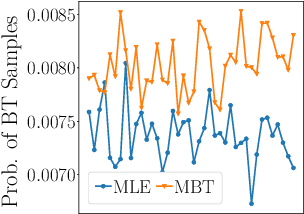

Back-translation is an effective strategy to improve the performance of Neural Machine Translation~(NMT) by generating pseudo-parallel data. However, several recent works have found that better translation quality of the pseudo-parallel data does not necessarily lead to better final translation models, while lower-quality but more diverse data often yields stronger results. In this paper, we propose a novel method to generate pseudo-parallel data from a pre-trained back-translation model. Our method is a meta-learning algorithm which adapts a pre-trained back-translation model so that the pseudo-parallel data it generates would train a forward-translation model to do well on a validation set. In our evaluations in both the standard datasets WMT En-De'14 and WMT En-Fr'14, as well as a multilingual translation setting, our method leads to significant improvements over strong baselines. Our code will be made available.
Towards More Fine-grained and Reliable NLP Performance Prediction
Feb 10, 2021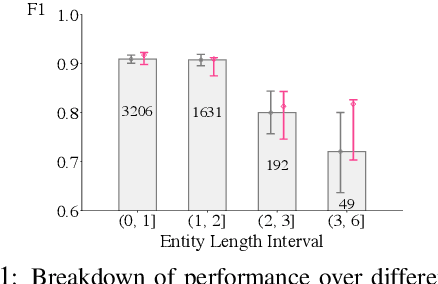
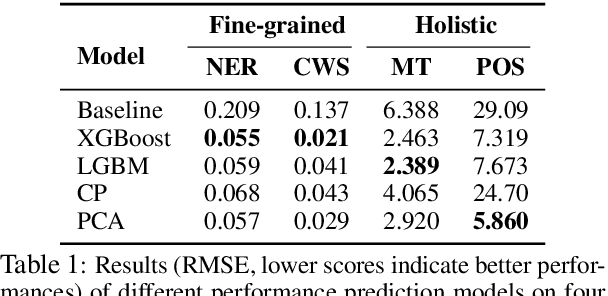
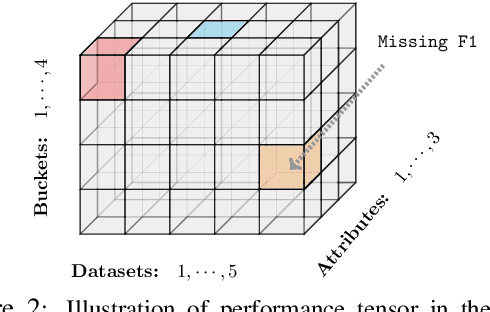
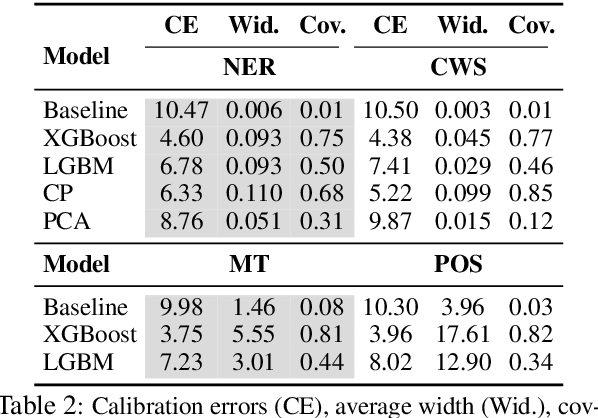
Performance prediction, the task of estimating a system's performance without performing experiments, allows us to reduce the experimental burden caused by the combinatorial explosion of different datasets, languages, tasks, and models. In this paper, we make two contributions to improving performance prediction for NLP tasks. First, we examine performance predictors not only for holistic measures of accuracy like F1 or BLEU but also fine-grained performance measures such as accuracy over individual classes of examples. Second, we propose methods to understand the reliability of a performance prediction model from two angles: confidence intervals and calibration. We perform an analysis of four types of NLP tasks, and both demonstrate the feasibility of fine-grained performance prediction and the necessity to perform reliability analysis for performance prediction methods in the future. We make our code publicly available: \url{https://github.com/neulab/Reliable-NLPPP}
Can We Automate Scientific Reviewing?
Jan 30, 2021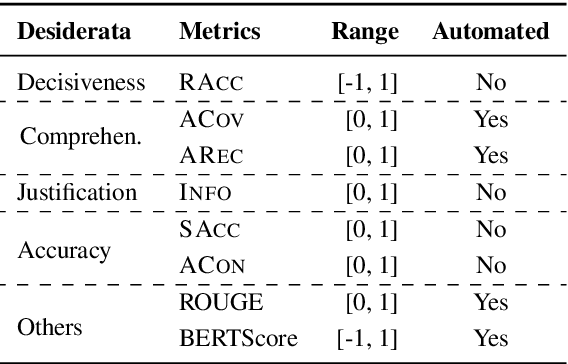
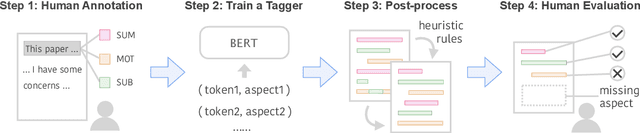
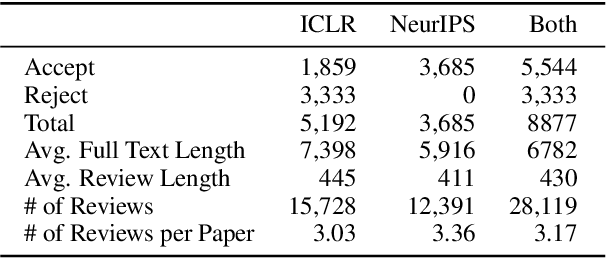
The rapid development of science and technology has been accompanied by an exponential growth in peer-reviewed scientific publications. At the same time, the review of each paper is a laborious process that must be carried out by subject matter experts. Thus, providing high-quality reviews of this growing number of papers is a significant challenge. In this work, we ask the question "can we automate scientific reviewing?", discussing the possibility of using state-of-the-art natural language processing (NLP) models to generate first-pass peer reviews for scientific papers. Arguably the most difficult part of this is defining what a "good" review is in the first place, so we first discuss possible evaluation measures for such reviews. We then collect a dataset of papers in the machine learning domain, annotate them with different aspects of content covered in each review, and train targeted summarization models that take in papers to generate reviews. Comprehensive experimental results show that system-generated reviews tend to touch upon more aspects of the paper than human-written reviews, but the generated text can suffer from lower constructiveness for all aspects except the explanation of the core ideas of the papers, which are largely factually correct. We finally summarize eight challenges in the pursuit of a good review generation system together with potential solutions, which, hopefully, will inspire more future research on this subject. We make all code, and the dataset publicly available: https://github.com/neulab/ReviewAdvisor, as well as a ReviewAdvisor system: http://review.nlpedia.ai/.
Learning Structural Edits via Incremental Tree Transformations
Jan 28, 2021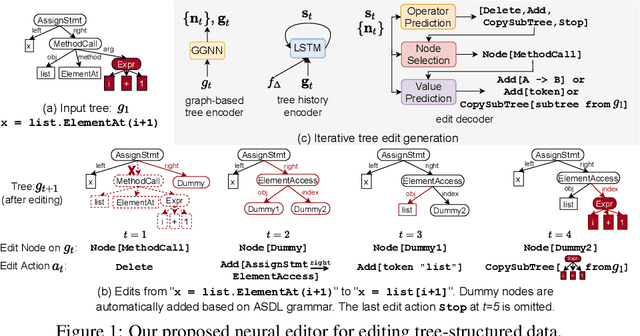


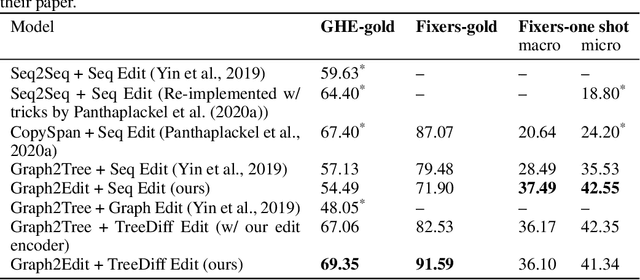
While most neural generative models generate outputs in a single pass, the human creative process is usually one of iterative building and refinement. Recent work has proposed models of editing processes, but these mostly focus on editing sequential data and/or only model a single editing pass. In this paper, we present a generic model for incremental editing of structured data (i.e., "structural edits"). Particularly, we focus on tree-structured data, taking abstract syntax trees of computer programs as our canonical example. Our editor learns to iteratively generate tree edits (e.g., deleting or adding a subtree) and applies them to the partially edited data, thereby the entire editing process can be formulated as consecutive, incremental tree transformations. To show the unique benefits of modeling tree edits directly, we further propose a novel edit encoder for learning to represent edits, as well as an imitation learning method that allows the editor to be more robust. We evaluate our proposed editor on two source code edit datasets, where results show that, with the proposed edit encoder, our editor significantly improves accuracy over previous approaches that generate the edited program directly in one pass. Finally, we demonstrate that training our editor to imitate experts and correct its mistakes dynamically can further improve its performance.
Word Alignment by Fine-tuning Embeddings on Parallel Corpora
Jan 24, 2021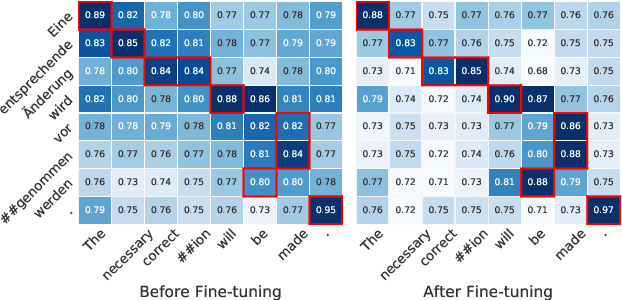

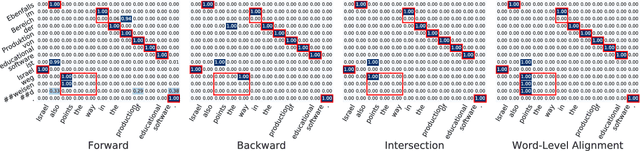
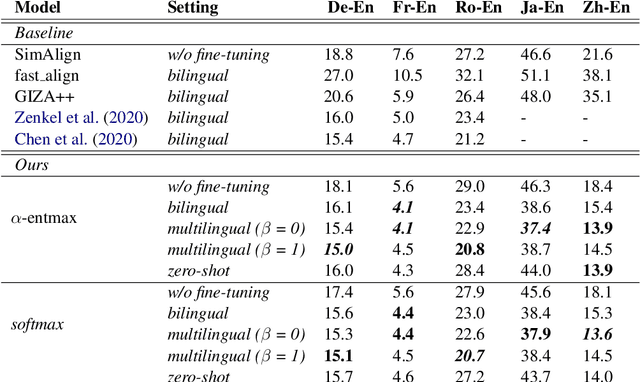
Word alignment over parallel corpora has a wide variety of applications, including learning translation lexicons, cross-lingual transfer of language processing tools, and automatic evaluation or analysis of translation outputs. The great majority of past work on word alignment has worked by performing unsupervised learning on parallel texts. Recently, however, other work has demonstrated that pre-trained contextualized word embeddings derived from multilingually trained language models (LMs) prove an attractive alternative, achieving competitive results on the word alignment task even in the absence of explicit training on parallel data. In this paper, we examine methods to marry the two approaches: leveraging pre-trained LMs but fine-tuning them on parallel text with objectives designed to improve alignment quality, and proposing methods to effectively extract alignments from these fine-tuned models. We perform experiments on five language pairs and demonstrate that our model can consistently outperform previous state-of-the-art models of all varieties. In addition, we demonstrate that we are able to train multilingual word aligners that can obtain robust performance on different language pairs. Our aligner, AWESOME (Aligning Word Embedding Spaces of Multilingual Encoders), with pre-trained models is available at https://github.com/neulab/awesome-align
Interpretable Multi-dataset Evaluation for Named Entity Recognition
Dec 09, 2020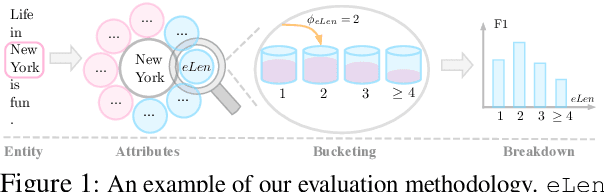
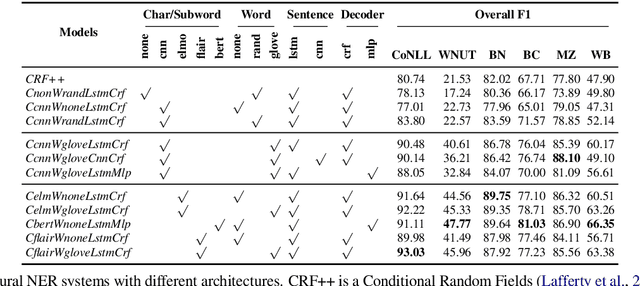
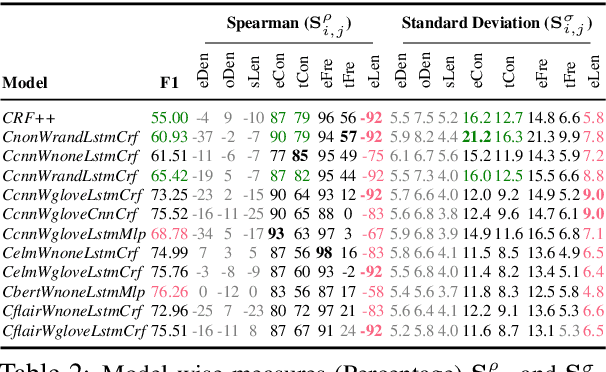
With the proliferation of models for natural language processing tasks, it is even harder to understand the differences between models and their relative merits. Simply looking at differences between holistic metrics such as accuracy, BLEU, or F1 does not tell us why or how particular methods perform differently and how diverse datasets influence the model design choices. In this paper, we present a general methodology for interpretable evaluation for the named entity recognition (NER) task. The proposed evaluation method enables us to interpret the differences in models and datasets, as well as the interplay between them, identifying the strengths and weaknesses of current systems. By making our analysis tool available, we make it easy for future researchers to run similar analyses and drive progress in this area: https://github.com/neulab/InterpretEval.
How Can We Know When Language Models Know?
Dec 02, 2020Recent works have shown that language models (LM) capture different types of knowledge regarding facts or common sense. However, because no model is perfect, they still fail to provide appropriate answers in many cases. In this paper, we ask the question "how can we know when language models know, with confidence, the answer to a particular query?" We examine this question from the point of view of calibration, the property of a probabilistic model's predicted probabilities actually being well correlated with the probability of correctness. We first examine a state-of-the-art generative QA model, T5, and examine whether its probabilities are well calibrated, finding the answer is a relatively emphatic no. We then examine methods to calibrate such models to make their confidence scores correlate better with the likelihood of correctness through fine-tuning, post-hoc probability modification, or adjustment of the predicted outputs or inputs. Experiments on a diverse range of datasets demonstrate the effectiveness of our methods. We also perform analysis to study the strengths and limitations of these methods, shedding light on further improvements that may be made in methods for calibrating LMs.
Evaluating Explanations: How much do explanations from the teacher aid students?
Dec 01, 2020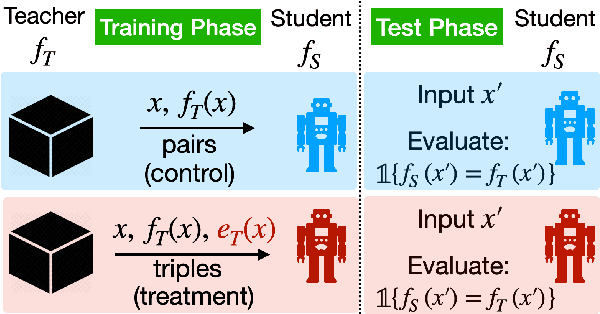
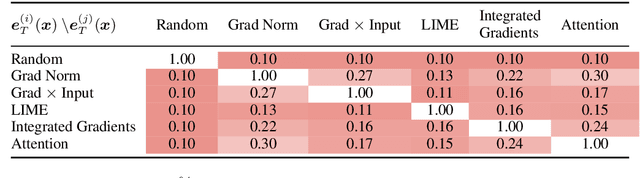

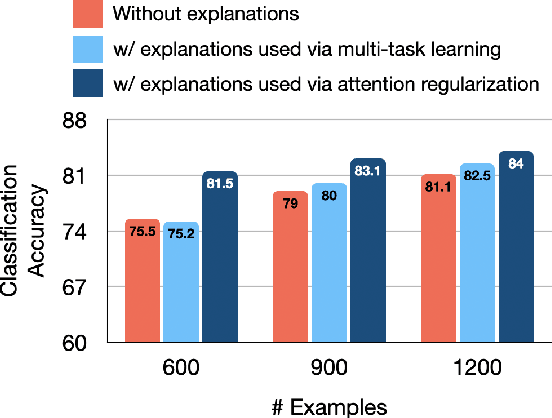
While many methods purport to explain predictions by highlighting salient features, what precise aims these explanations serve and how to evaluate their utility are often unstated. In this work, we formalize the value of explanations using a student-teacher paradigm that measures the extent to which explanations improve student models in learning to simulate the teacher model on unseen examples for which explanations are unavailable. Student models incorporate explanations in training (but not prediction) procedures. Unlike many prior proposals to evaluate explanations, our approach cannot be easily gamed, enabling principled, scalable, and automatic evaluation of attributions. Using our framework, we compare multiple attribution methods and observe consistent and quantitative differences amongst them across multiple learning strategies.
Decoding and Diversity in Machine Translation
Nov 26, 2020

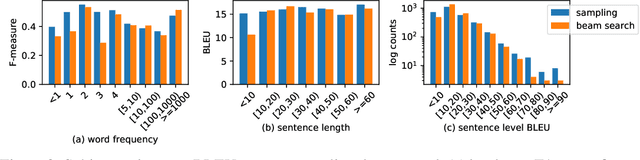
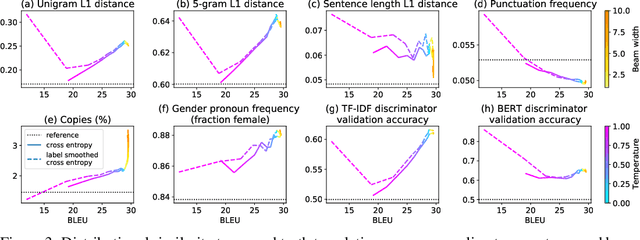
Neural Machine Translation (NMT) systems are typically evaluated using automated metrics that assess the agreement between generated translations and ground truth candidates. To improve systems with respect to these metrics, NLP researchers employ a variety of heuristic techniques, including searching for the conditional mode (vs. sampling) and incorporating various training heuristics (e.g., label smoothing). While search strategies significantly improve BLEU score, they yield deterministic outputs that lack the diversity of human translations. Moreover, search tends to bias the distribution of translated gender pronouns. This makes human-level BLEU a misleading benchmark in that modern MT systems cannot approach human-level BLEU while simultaneously maintaining human-level translation diversity. In this paper, we characterize distributional differences between generated and real translations, examining the cost in diversity paid for the BLEU scores enjoyed by NMT. Moreover, our study implicates search as a salient source of known bias when translating gender pronouns.