 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Quantification for LLM Function-Calling
Apr 24, 2026Large Language Models (LLMs) are increasingly deployed to autonomously solve real-world tasks. A key ingredient for this is the LLM Function-Calling paradigm, a widely used approach for equipping LLMs with tool-use capabilities. However, an LLM calling functions incorrectly can have severe implications, especially when their effects are irreversible, e.g., transferring money or deleting data. Hence, it is of paramount importance to consider the LLM's confidence that a function call solves the task correctly prior to executing it. Uncertainty Quantification (UQ) methods can be used to quantify this confidence and prevent potentially incorrect function calls. In this work, we present what is, to our knowledge, the first evaluation of UQ methods for LLM Function-Calling (FC). While multi-sample UQ methods, such as Semantic Entropy, show strong performance for natural language Q&A tasks, we find that in the FC setting, it offers no clear advantage over simple single-sample UQ methods. Additionally, we find that the particularities of FC outputs can be leveraged to improve the performance of existing UQ methods in this setting. Specifically, multi-sample UQ methods benefit from clustering FC outputs based on their abstract syntax tree parsing, while single-sample UQ methods can be improved by selecting only semantically meaningful tokens when calculating logit-based uncertainty scores.
Likelihood hacking in probabilistic program synthesis
Mar 25, 2026When language models are trained by reinforcement learning (RL) to write probabilistic programs, they can artificially inflate their marginal-likelihood reward by producing programs whose data distribution fails to normalise instead of fitting the data better. We call this failure likelihood hacking (LH). We formalise LH in a core probabilistic programming language (PPL) and give sufficient syntactic conditions for its prevention, proving that a safe language fragment $\mathcal{L}_{\text{safe}}$ satisfying these conditions cannot produce likelihood-hacking programs. Empirically, we show that GRPO-trained models generating PyMC code discover LH exploits within the first few training steps, driving violation rates well above the untrained-model baseline. We implement $\mathcal{L}_{\text{safe}}$'s conditions as $\texttt{SafeStan}$, a LH-resistant modification of Stan, and show empirically that it prevents LH under optimisation pressure. These results show that language-level safety constraints are both theoretically grounded and effective in practice for automated Bayesian model discovery.
Improving Reward Models with Synthetic Critiques
May 31, 2024



Reward models (RM) play a critical role in aligning language models through the process of reinforcement learning from human feedback. RMs are trained to predict a score reflecting human preference, which requires significant time and cost for human annotation. Additionally, RMs tend to quickly overfit on superficial features in the training set, hindering their generalization performance on unseen distributions. We propose a novel approach using synthetic natural language critiques generated by large language models to provide additional feedback, evaluating aspects such as instruction following, correctness, and style. This offers richer signals and more robust features for RMs to assess and score on. We demonstrate that high-quality critiques improve the performance and data efficiency of RMs initialized from different pretrained models. Conversely, we also show that low-quality critiques negatively impact performance. Furthermore, incorporating critiques enhances the interpretability and robustness of RM training.
EXPLAINABOARD: An Explainable Leaderboard for NLP
Apr 13, 2021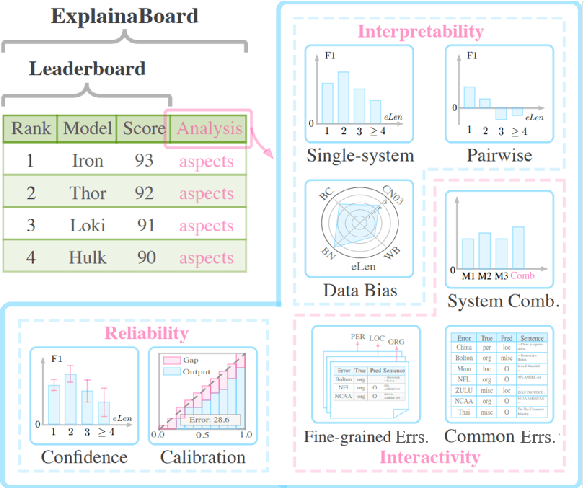
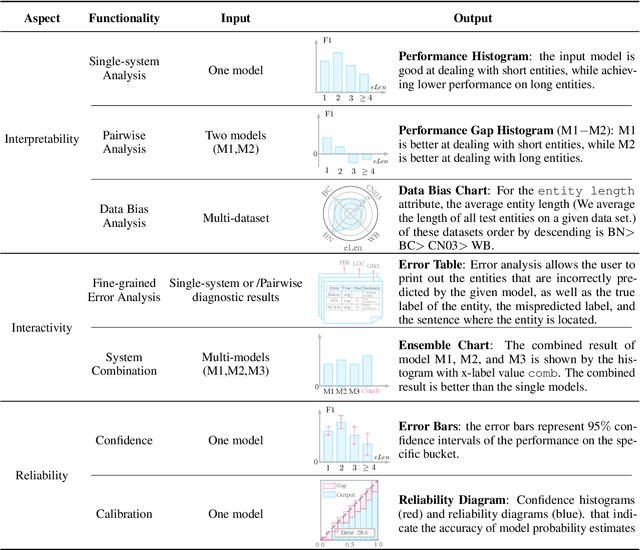
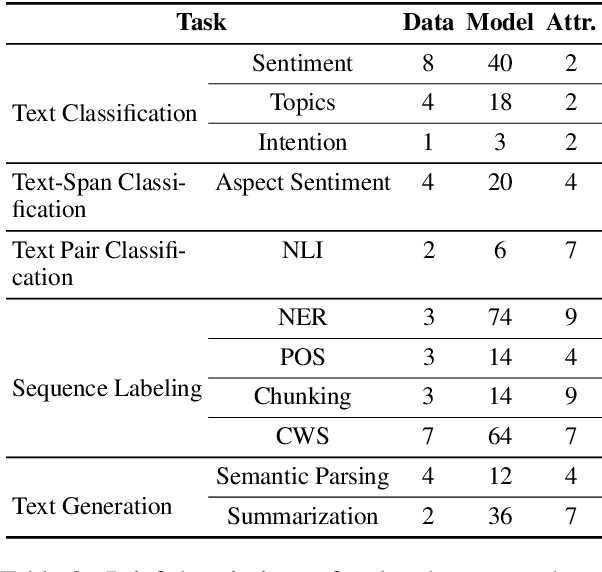
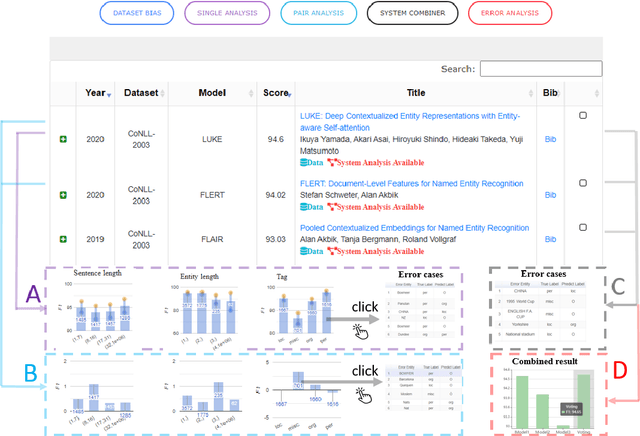
With the rapid development of NLP research, leaderboards have emerged as one tool to track the performance of various systems on various NLP tasks. They are effective in this goal to some extent, but generally present a rather simplistic one-dimensional view of the submitted systems, communicated only through holistic accuracy numbers. In this paper, we present a new conceptualization and implementation of NLP evaluation: the ExplainaBoard, which in addition to inheriting the functionality of the standard leaderboard, also allows researchers to (i) diagnose strengths and weaknesses of a single system (e.g. what is the best-performing system bad at?) (ii) interpret relationships between multiple systems. (e.g. where does system A outperform system B? What if we combine systems A, B, C?) and (iii) examine prediction results closely (e.g. what are common errors made by multiple systems or and in what contexts do particular errors occur?). ExplainaBoard has been deployed at \url{http://explainaboard.nlpedia.ai/}, and we have additionally released our interpretable evaluation code at \url{https://github.com/neulab/ExplainaBoard} and output files from more than 300 systems, 40 datasets, and 9 tasks to motivate the "output-driven" research in the future.
Towards More Fine-grained and Reliable NLP Performance Prediction
Feb 10, 2021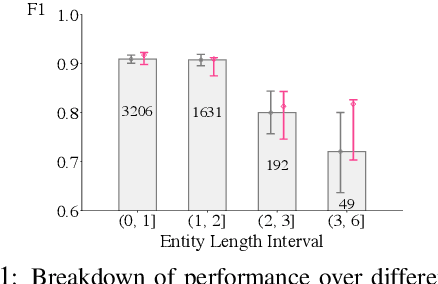
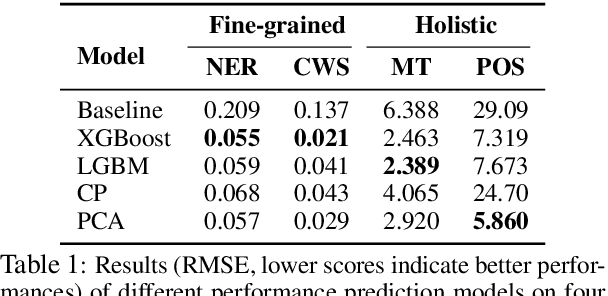
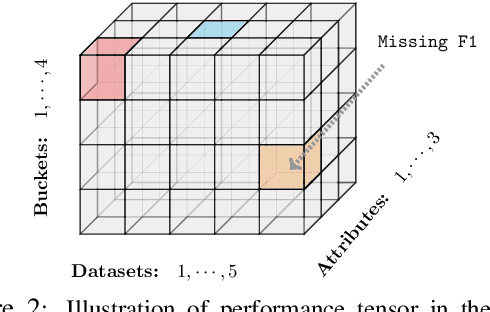
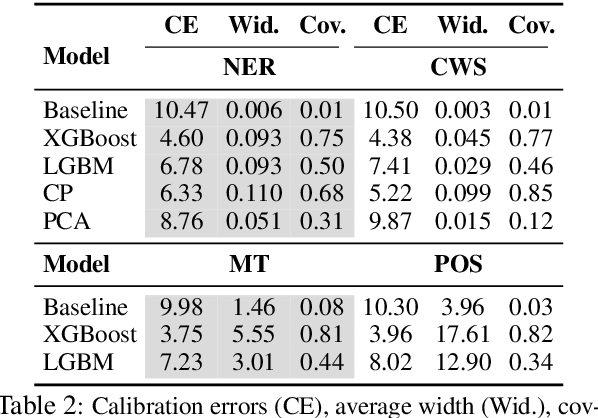
Performance prediction, the task of estimating a system's performance without performing experiments, allows us to reduce the experimental burden caused by the combinatorial explosion of different datasets, languages, tasks, and models. In this paper, we make two contributions to improving performance prediction for NLP tasks. First, we examine performance predictors not only for holistic measures of accuracy like F1 or BLEU but also fine-grained performance measures such as accuracy over individual classes of examples. Second, we propose methods to understand the reliability of a performance prediction model from two angles: confidence intervals and calibration. We perform an analysis of four types of NLP tasks, and both demonstrate the feasibility of fine-grained performance prediction and the necessity to perform reliability analysis for performance prediction methods in the future. We make our code publicly available: \url{https://github.com/neulab/Reliable-NLPPP}