 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoop Closure Prioritization for Efficient and Scalable Multi-Robot SLAM
May 24, 2022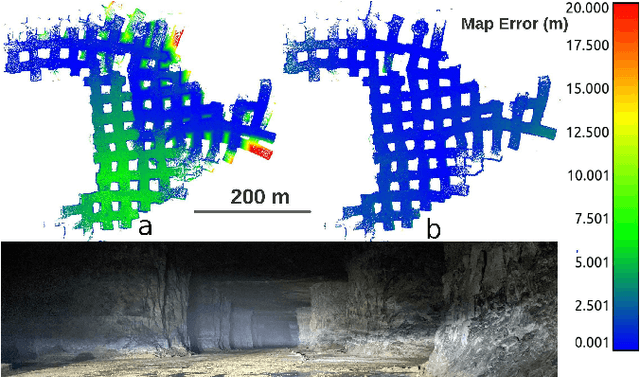
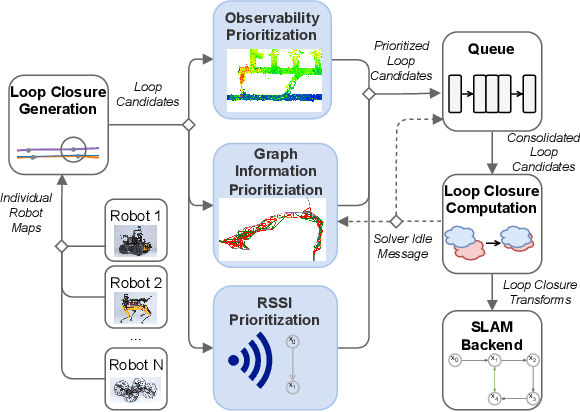
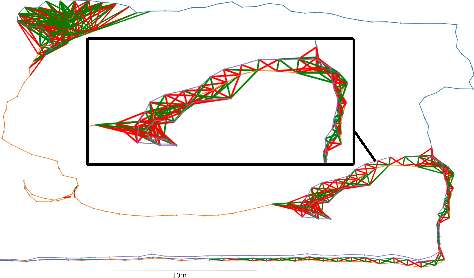
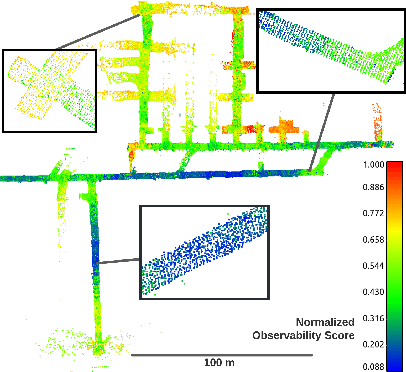
Multi-robot SLAM systems in GPS-denied environments require loop closures to maintain a drift-free centralized map. With an increasing number of robots and size of the environment, checking and computing the transformation for all the loop closure candidates becomes computationally infeasible. In this work, we describe a loop closure module that is able to prioritize which loop closures to compute based on the underlying pose graph, the proximity to known beacons, and the characteristics of the point clouds. We validate this system in the context of the DARPA Subterranean Challenge and on numerous challenging underground datasets and demonstrate the ability of this system to generate and maintain a map with low error. We find that our proposed techniques are able to select effective loop closures which results in 51% mean reduction in median error when compared to an odometric solution and 75% mean reduction in median error when compared to a baseline version of this system with no prioritization. We also find our proposed system is able to find a lower error in the mission time of one hour when compared to a system that processes every possible loop closure in four and a half hours.
Inferring Articulated Rigid Body Dynamics from RGBD Video
Mar 20, 2022
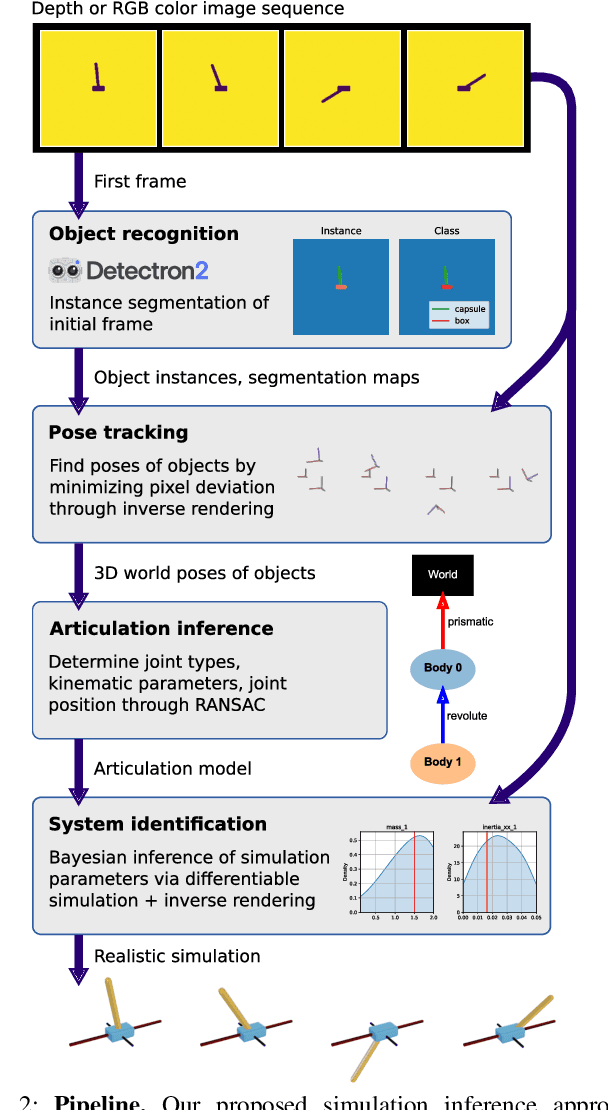
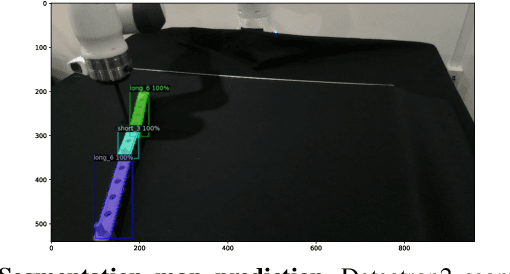
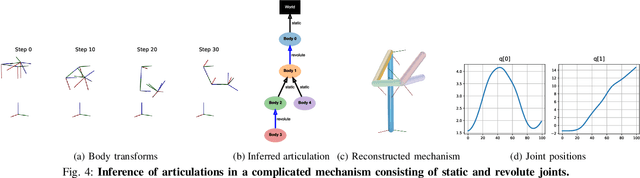
Being able to reproduce physical phenomena ranging from light interaction to contact mechanics, simulators are becoming increasingly useful in more and more application domains where real-world interaction or labeled data are difficult to obtain. Despite recent progress, significant human effort is needed to configure simulators to accurately reproduce real-world behavior. We introduce a pipeline that combines inverse rendering with differentiable simulation to create digital twins of real-world articulated mechanisms from depth or RGB videos. Our approach automatically discovers joint types and estimates their kinematic parameters, while the dynamic properties of the overall mechanism are tuned to attain physically accurate simulations. Control policies optimized in our derived simulation transfer successfully back to the original system, as we demonstrate on a simulated system. Further, our approach accurately reconstructs the kinematic tree of an articulated mechanism being manipulated by a robot, and highly nonlinear dynamics of a real-world coupled pendulum mechanism. Website: https://eric-heiden.github.io/video2sim
DialFRED: Dialogue-Enabled Agents for Embodied Instruction Following
Feb 27, 2022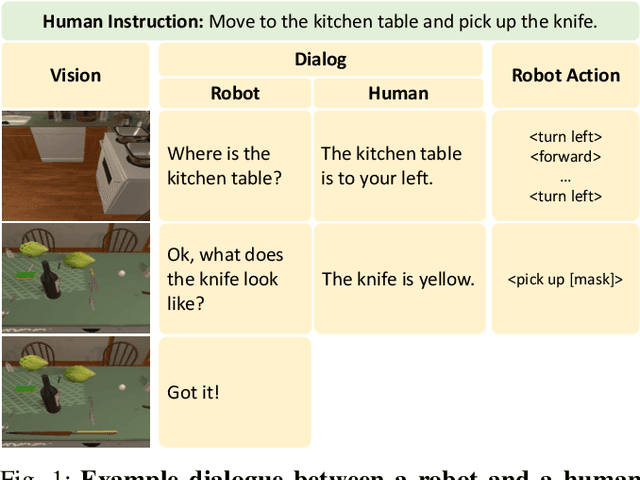


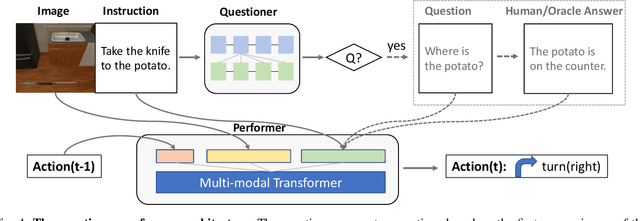
Language-guided Embodied AI benchmarks requiring an agent to navigate an environment and manipulate objects typically allow one-way communication: the human user gives a natural language command to the agent, and the agent can only follow the command passively. We present DialFRED, a dialogue-enabled embodied instruction following benchmark based on the ALFRED benchmark. DialFRED allows an agent to actively ask questions to the human user; the additional information in the user's response is used by the agent to better complete its task. We release a human-annotated dataset with 53K task-relevant questions and answers and an oracle to answer questions. To solve DialFRED, we propose a questioner-performer framework wherein the questioner is pre-trained with the human-annotated data and fine-tuned with reinforcement learning. We make DialFRED publicly available and encourage researchers to propose and evaluate their solutions to building dialog-enabled embodied agents.
Privacy Preserving Visual Question Answering
Feb 15, 2022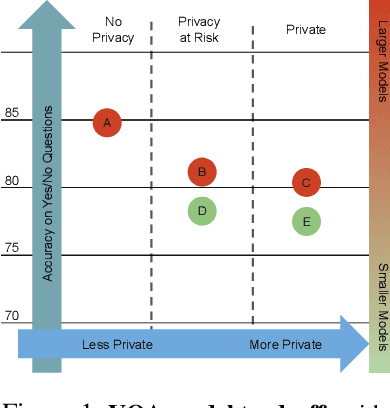

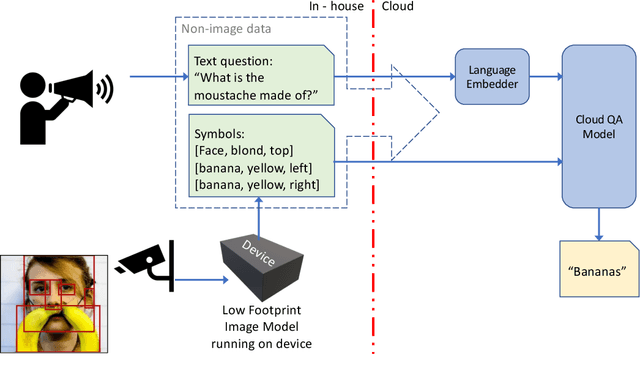

We introduce a novel privacy-preserving methodology for performing Visual Question Answering on the edge. Our method constructs a symbolic representation of the visual scene, using a low-complexity computer vision model that jointly predicts classes, attributes and predicates. This symbolic representation is non-differentiable, which means it cannot be used to recover the original image, thereby keeping the original image private. Our proposed hybrid solution uses a vision model which is more than 25 times smaller than the current state-of-the-art (SOTA) vision models, and 100 times smaller than end-to-end SOTA VQA models. We report detailed error analysis and discuss the trade-offs of using a distilled vision model and a symbolic representation of the visual scene.
Adaptive Sampling to Estimate Quantiles for Guiding Physical Sampling
Jan 25, 2022
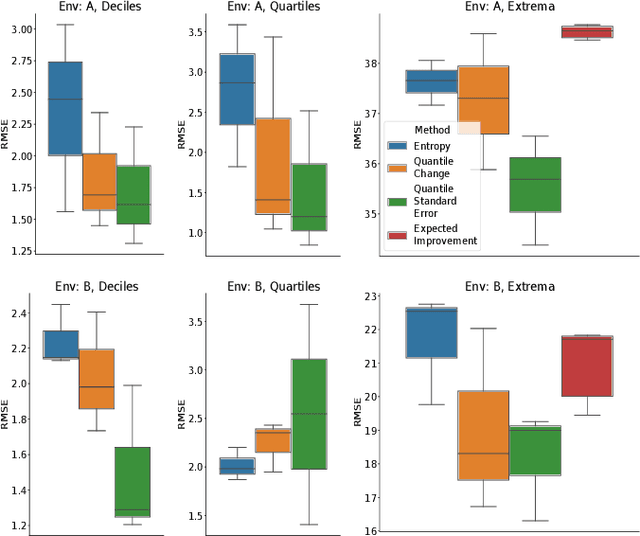
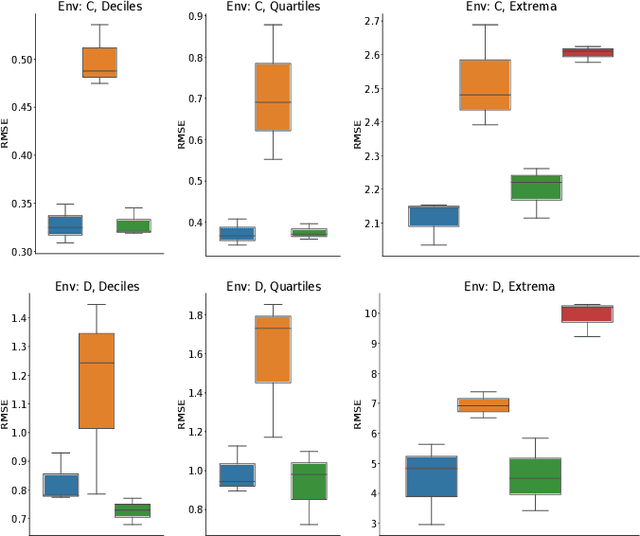
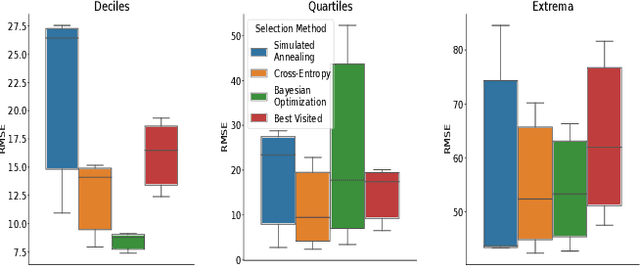
Scientists interested in studying natural phenomena often take physical samples for later analysis at locations specified by expert heuristics. Instead, we propose to guide scientists' physical sampling by using a robot to perform an adaptive sampling survey to find locations to suggest that correspond to the quantile values of pre-specified quantiles of interest. We develop a robot planner using novel objective functions to improve the estimates of the quantile values over time and an approach to find locations which correspond to the quantile values. We demonstrate our approach on two different sampling tasks in simulation using previously collected aquatic data and validate it in a field trial. Our approach outperforms objectives that maximize spatial coverage or find extrema in planning and is able to localize the quantile spatial locations.
Distilling Motion Planner Augmented Policies into Visual Control Policies for Robot Manipulation
Nov 11, 2021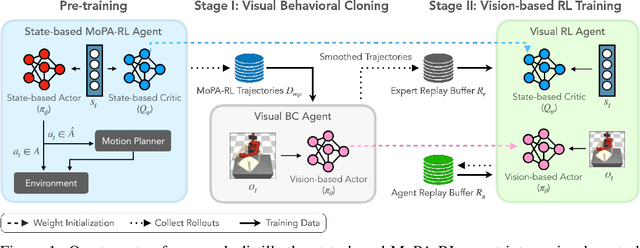
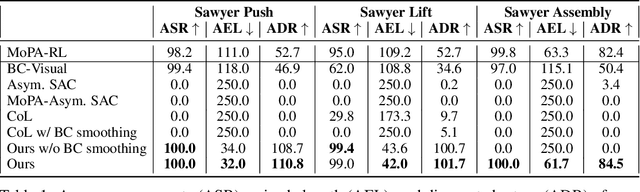
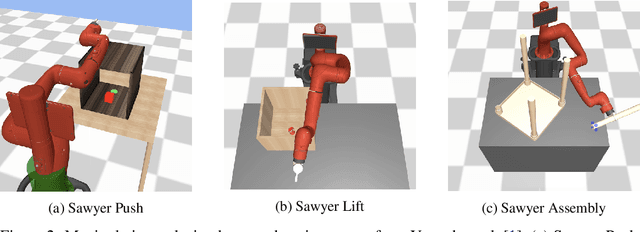

Learning complex manipulation tasks in realistic, obstructed environments is a challenging problem due to hard exploration in the presence of obstacles and high-dimensional visual observations. Prior work tackles the exploration problem by integrating motion planning and reinforcement learning. However, the motion planner augmented policy requires access to state information, which is often not available in the real-world settings. To this end, we propose to distill a state-based motion planner augmented policy to a visual control policy via (1) visual behavioral cloning to remove the motion planner dependency along with its jittery motion, and (2) vision-based reinforcement learning with the guidance of the smoothed trajectories from the behavioral cloning agent. We evaluate our method on three manipulation tasks in obstructed environments and compare it against various reinforcement learning and imitation learning baselines. The results demonstrate that our framework is highly sample-efficient and outperforms the state-of-the-art algorithms. Moreover, coupled with domain randomization, our policy is capable of zero-shot transfer to unseen environment settings with distractors. Code and videos are available at https://clvrai.com/mopa-pd
LUMINOUS: Indoor Scene Generation for Embodied AI Challenges
Nov 10, 2021

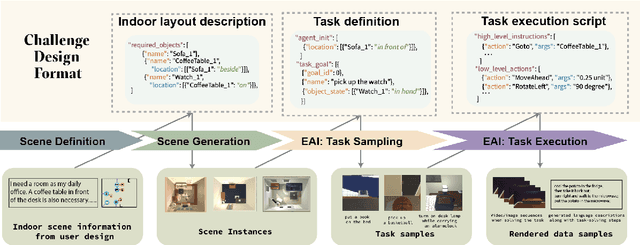
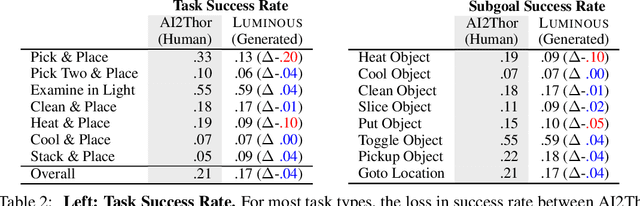
Learning-based methods for training embodied agents typically require a large number of high-quality scenes that contain realistic layouts and support meaningful interactions. However, current simulators for Embodied AI (EAI) challenges only provide simulated indoor scenes with a limited number of layouts. This paper presents Luminous, the first research framework that employs state-of-the-art indoor scene synthesis algorithms to generate large-scale simulated scenes for Embodied AI challenges. Further, we automatically and quantitatively evaluate the quality of generated indoor scenes via their ability to support complex household tasks. Luminous incorporates a novel scene generation algorithm (Constrained Stochastic Scene Generation (CSSG)), which achieves competitive performance with human-designed scenes. Within Luminous, the EAI task executor, task instruction generation module, and video rendering toolkit can collectively generate a massive multimodal dataset of new scenes for the training and evaluation of Embodied AI agents. Extensive experimental results demonstrate the effectiveness of the data generated by Luminous, enabling the comprehensive assessment of embodied agents on generalization and robustness.
A Simple Approach to Continual Learning by Transferring Skill Parameters
Oct 19, 2021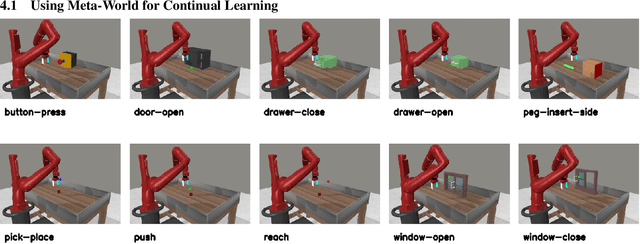
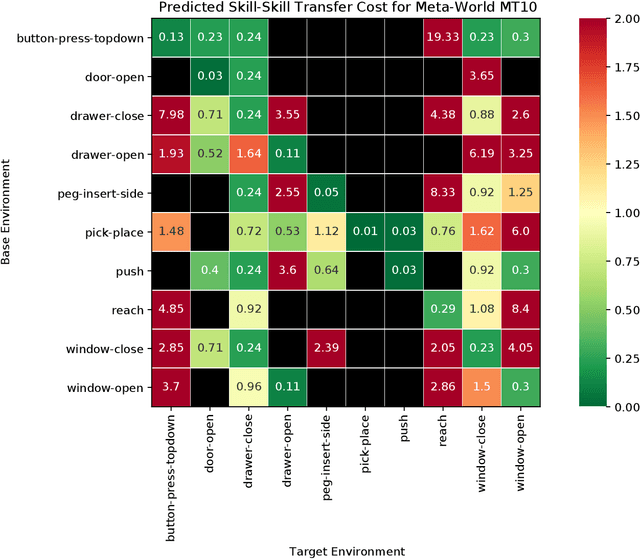
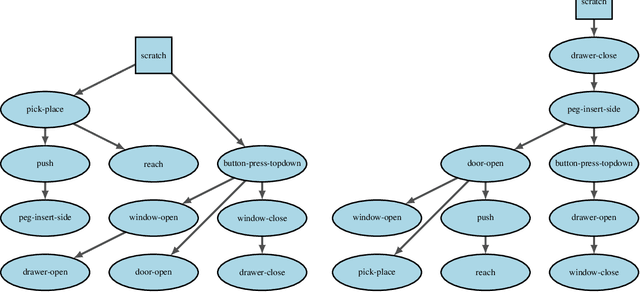
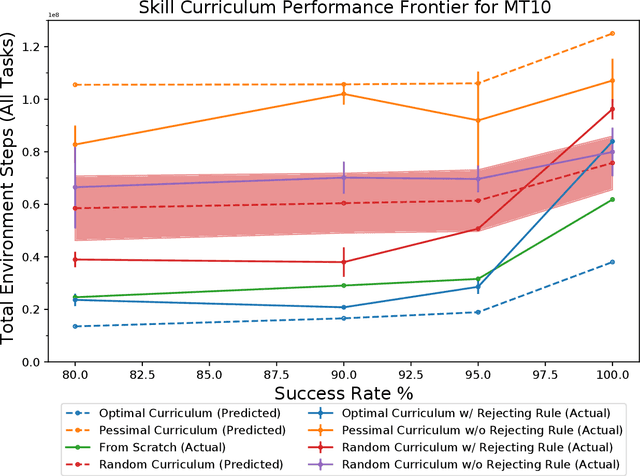
In order to be effective general purpose machines in real world environments, robots not only will need to adapt their existing manipulation skills to new circumstances, they will need to acquire entirely new skills on-the-fly. A great promise of continual learning is to endow robots with this ability, by using their accumulated knowledge and experience from prior skills. We take a fresh look at this problem, by considering a setting in which the robot is limited to storing that knowledge and experience only in the form of learned skill policies. We show that storing skill policies, careful pre-training, and appropriately choosing when to transfer those skill policies is sufficient to build a continual learner in the context of robotic manipulation. We analyze which conditions are needed to transfer skills in the challenging Meta-World simulation benchmark. Using this analysis, we introduce a pair-wise metric relating skills that allows us to predict the effectiveness of skill transfer between tasks, and use it to reduce the problem of continual learning to curriculum selection. Given an appropriate curriculum, we show how to continually acquire robotic manipulation skills without forgetting, and using far fewer samples than needed to train them from scratch.
Beyond Robustness: A Taxonomy of Approaches towards Resilient Multi-Robot Systems
Sep 25, 2021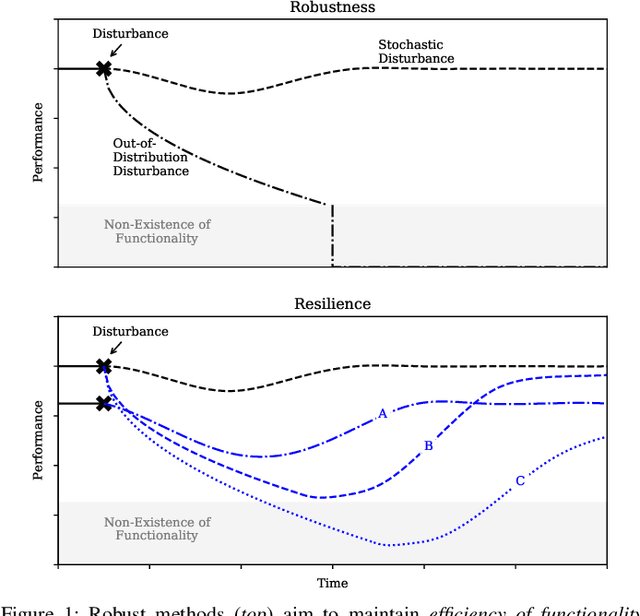
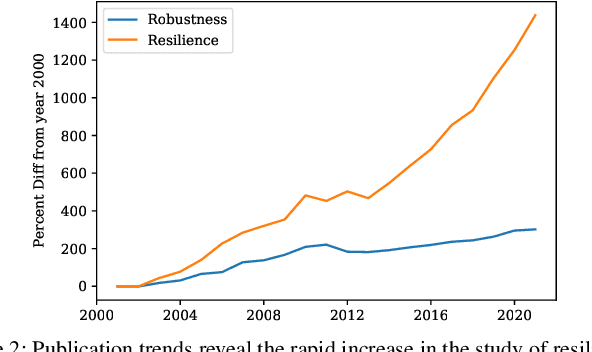

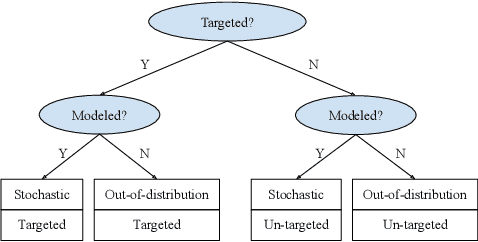
Robustness is key to engineering, automation, and science as a whole. However, the property of robustness is often underpinned by costly requirements such as over-provisioning, known uncertainty and predictive models, and known adversaries. These conditions are idealistic, and often not satisfiable. Resilience on the other hand is the capability to endure unexpected disruptions, to recover swiftly from negative events, and bounce back to normality. In this survey article, we analyze how resilience is achieved in networks of agents and multi-robot systems that are able to overcome adversity by leveraging system-wide complementarity, diversity, and redundancy - often involving a reconfiguration of robotic capabilities to provide some key ability that was not present in the system a priori. As society increasingly depends on connected automated systems to provide key infrastructure services (e.g., logistics, transport, and precision agriculture), providing the means to achieving resilient multi-robot systems is paramount. By enumerating the consequences of a system that is not resilient (fragile), we argue that resilience must become a central engineering design consideration. Towards this goal, the community needs to gain clarity on how it is defined, measured, and maintained. We address these questions across foundational robotics domains, spanning perception, control, planning, and learning. One of our key contributions is a formal taxonomy of approaches, which also helps us discuss the defining factors and stressors for a resilient system. Finally, this survey article gives insight as to how resilience may be achieved. Importantly, we highlight open problems that remain to be tackled in order to reap the benefits of resilient robotic systems.
Adaptive Sampling using POMDPs with Domain-Specific Considerations
Sep 23, 2021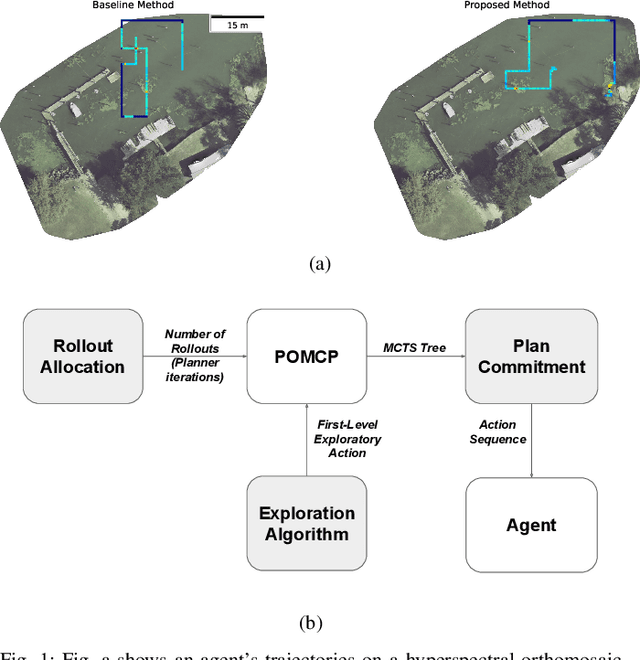
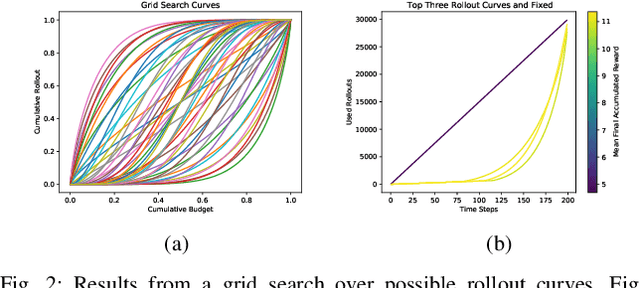

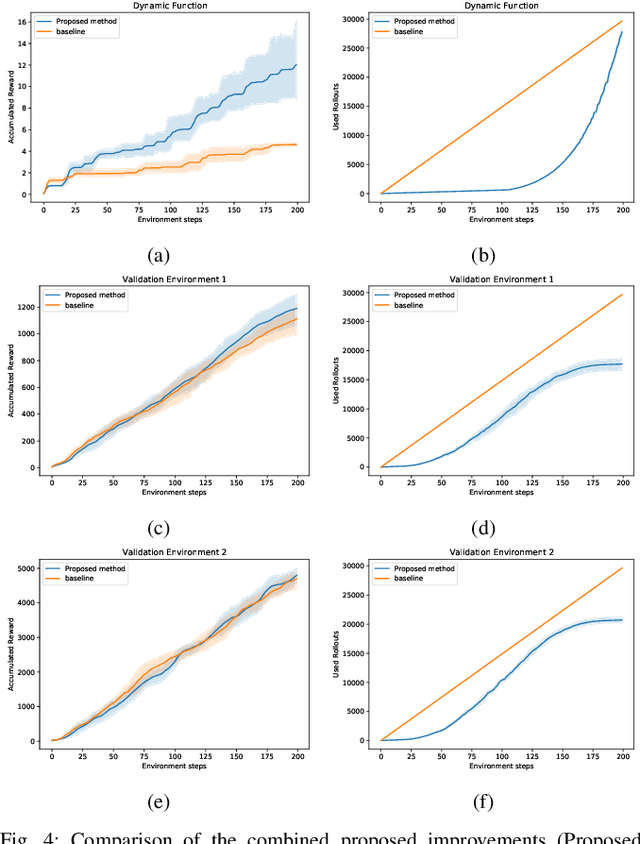
We investigate improving Monte Carlo Tree Search based solvers for Partially Observable Markov Decision Processes (POMDPs), when applied to adaptive sampling problems. We propose improvements in rollout allocation, the action exploration algorithm, and plan commitment. The first allocates a different number of rollouts depending on how many actions the agent has taken in an episode. We find that rollouts are more valuable after some initial information is gained about the environment. Thus, a linear increase in the number of rollouts, i.e. allocating a fixed number at each step, is not appropriate for adaptive sampling tasks. The second alters which actions the agent chooses to explore when building the planning tree. We find that by using knowledge of the number of rollouts allocated, the agent can more effectively choose actions to explore. The third improvement is in determining how many actions the agent should take from one plan. Typically, an agent will plan to take the first action from the planning tree and then call the planner again from the new state. Using statistical techniques, we show that it is possible to greatly reduce the number of rollouts by increasing the number of actions taken from a single planning tree without affecting the agent's final reward. Finally, we demonstrate experimentally, on simulated and real aquatic data from an underwater robot, that these improvements can be combined, leading to better adaptive sampling. The code for this work is available at https://github.com/uscresl/AdaptiveSamplingPOMCP