 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogit Clipping for Robust Learning against Label Noise
Dec 08, 2022



In the presence of noisy labels, designing robust loss functions is critical for securing the generalization performance of deep neural networks. Cross Entropy (CE) loss has been shown to be not robust to noisy labels due to its unboundedness. To alleviate this issue, existing works typically design specialized robust losses with the symmetric condition, which usually lead to the underfitting issue. In this paper, our key idea is to induce a loss bound at the logit level, thus universally enhancing the noise robustness of existing losses. Specifically, we propose logit clipping (LogitClip), which clamps the norm of the logit vector to ensure that it is upper bounded by a constant. In this manner, CE loss equipped with our LogitClip method is effectively bounded, mitigating the overfitting to examples with noisy labels. Moreover, we present theoretical analyses to certify the noise-tolerant ability of LogitClip. Extensive experiments show that LogitClip not only significantly improves the noise robustness of CE loss, but also broadly enhances the generalization performance of popular robust losses.
Adversarial Training with Complementary Labels: On the Benefit of Gradually Informative Attacks
Nov 01, 2022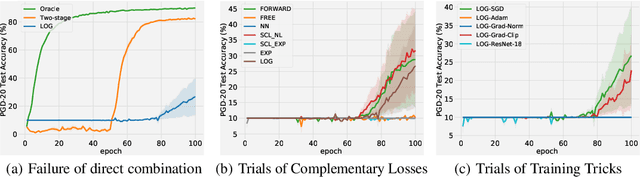
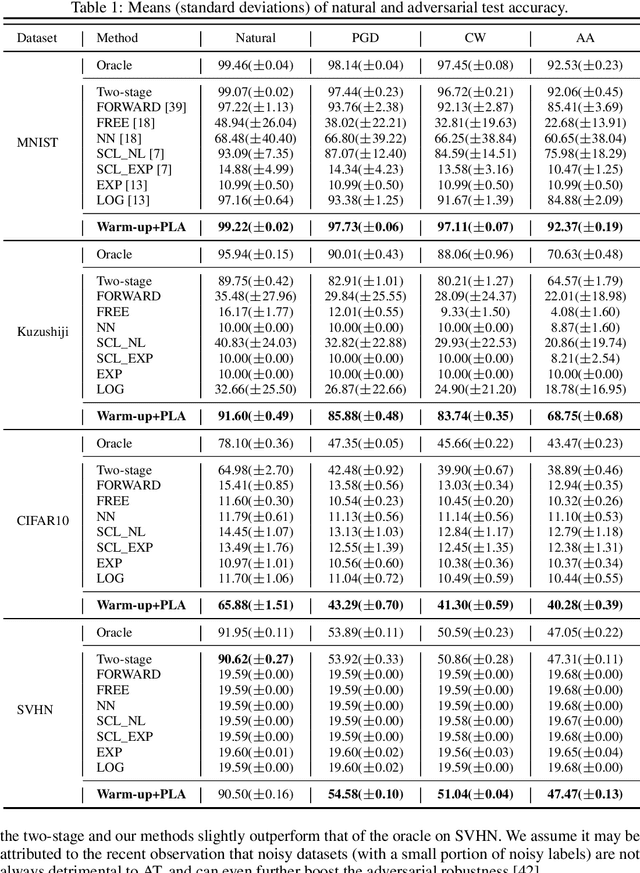
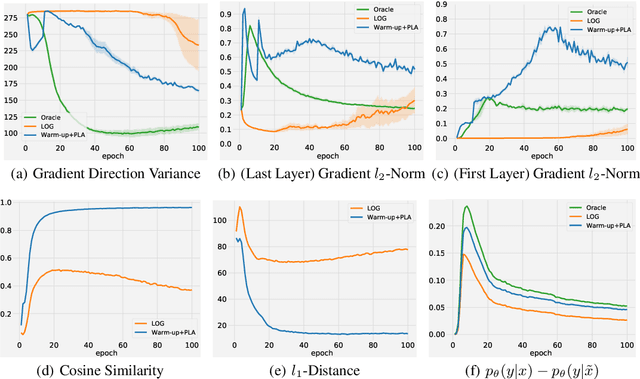

Adversarial training (AT) with imperfect supervision is significant but receives limited attention. To push AT towards more practical scenarios, we explore a brand new yet challenging setting, i.e., AT with complementary labels (CLs), which specify a class that a data sample does not belong to. However, the direct combination of AT with existing methods for CLs results in consistent failure, but not on a simple baseline of two-stage training. In this paper, we further explore the phenomenon and identify the underlying challenges of AT with CLs as intractable adversarial optimization and low-quality adversarial examples. To address the above problems, we propose a new learning strategy using gradually informative attacks, which consists of two critical components: 1) Warm-up Attack (Warm-up) gently raises the adversarial perturbation budgets to ease the adversarial optimization with CLs; 2) Pseudo-Label Attack (PLA) incorporates the progressively informative model predictions into a corrected complementary loss. Extensive experiments are conducted to demonstrate the effectiveness of our method on a range of benchmarked datasets. The code is publicly available at: https://github.com/RoyalSkye/ATCL.
FedMT: Federated Learning with Mixed-type Labels
Oct 05, 2022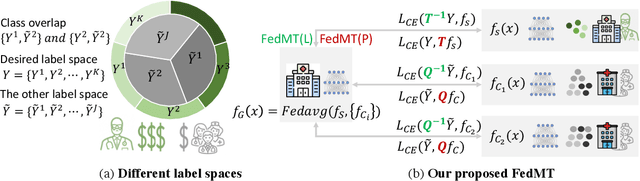
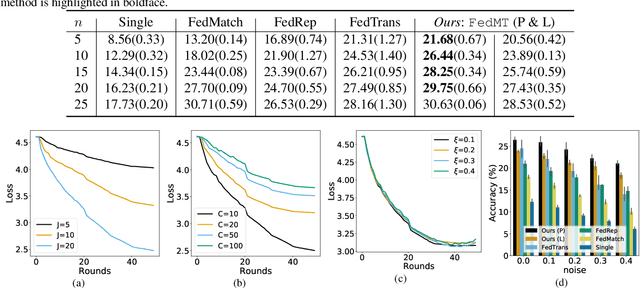
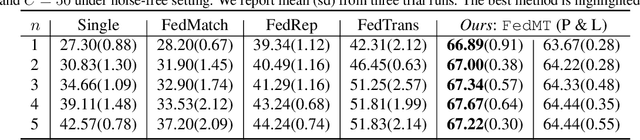

In federated learning (FL), classifiers (e.g., deep networks) are trained on datasets from multiple centers without exchanging data across them, and thus improves sample efficiency. In the classical setting of FL, the same labeling criterion is usually employed across all centers being involved in training. This constraint greatly limits the applicability of FL. For example, standards used for disease diagnosis are more likely to be different across clinical centers, which mismatches the classical FL setting. In this paper, we consider an important yet under-explored setting of FL, namely FL with mixed-type labels where different labeling criteria can be employed by various centers, leading to inter-center label space differences and challenging existing FL methods designed for the classical setting. To effectively and efficiently train models with mixed-type labels, we propose a theory-guided and model-agnostic approach that can make use of the underlying correspondence between those label spaces and can be easily combined with various FL methods such as FedAvg. We present convergence analysis based on over-parameterized ReLU networks. We show that the proposed method can achieve linear convergence in label projection, and demonstrate the impact of the parameters of our new setting on the convergence rate. The proposed method is evaluated and the theoretical findings are validated on benchmark and medical datasets.
Fast and Reliable Evaluation of Adversarial Robustness with Minimum-Margin Attack
Jun 15, 2022The AutoAttack (AA) has been the most reliable method to evaluate adversarial robustness when considerable computational resources are available. However, the high computational cost (e.g., 100 times more than that of the project gradient descent attack) makes AA infeasible for practitioners with limited computational resources, and also hinders applications of AA in the adversarial training (AT). In this paper, we propose a novel method, minimum-margin (MM) attack, to fast and reliably evaluate adversarial robustness. Compared with AA, our method achieves comparable performance but only costs 3% of the computational time in extensive experiments. The reliability of our method lies in that we evaluate the quality of adversarial examples using the margin between two targets that can precisely identify the most adversarial example. The computational efficiency of our method lies in an effective Sequential TArget Ranking Selection (STARS) method, ensuring that the cost of the MM attack is independent of the number of classes. The MM attack opens a new way for evaluating adversarial robustness and provides a feasible and reliable way to generate high-quality adversarial examples in AT.
Instance-Dependent Label-Noise Learning with Manifold-Regularized Transition Matrix Estimation
Jun 06, 2022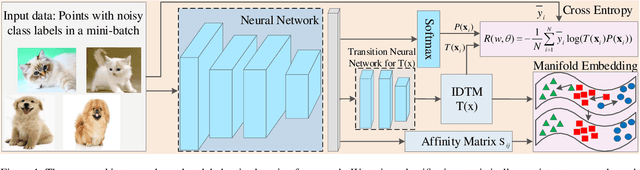
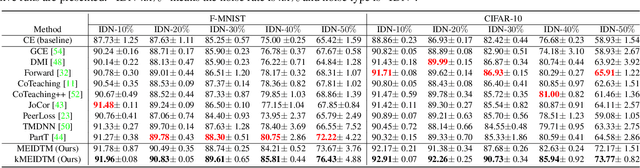
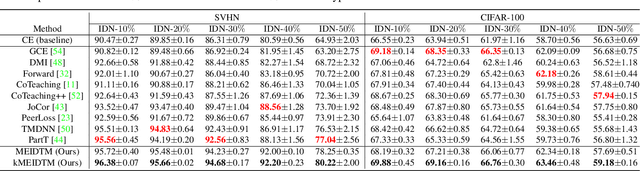
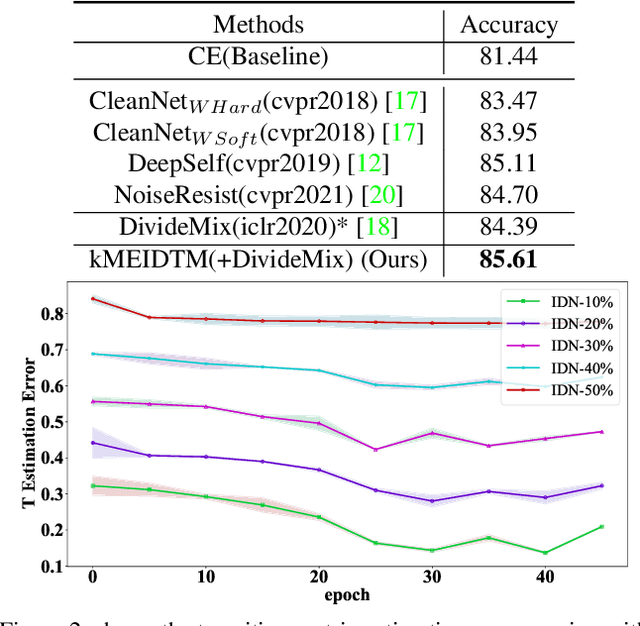
In label-noise learning, estimating the transition matrix has attracted more and more attention as the matrix plays an important role in building statistically consistent classifiers. However, it is very challenging to estimate the transition matrix T(x), where x denotes the instance, because it is unidentifiable under the instance-dependent noise(IDN). To address this problem, we have noticed that, there are psychological and physiological evidences showing that we humans are more likely to annotate instances of similar appearances to the same classes, and thus poor-quality or ambiguous instances of similar appearances are easier to be mislabeled to the correlated or same noisy classes. Therefore, we propose assumption on the geometry of T(x) that "the closer two instances are, the more similar their corresponding transition matrices should be". More specifically, we formulate above assumption into the manifold embedding, to effectively reduce the degree of freedom of T(x) and make it stably estimable in practice. The proposed manifold-regularized technique works by directly reducing the estimation error without hurting the approximation error about the estimation problem of T(x). Experimental evaluations on four synthetic and two real-world datasets demonstrate that our method is superior to state-of-the-art approaches for label-noise learning under the challenging IDN.
Federated Learning from Only Unlabeled Data with Class-Conditional-Sharing Clients
Apr 07, 2022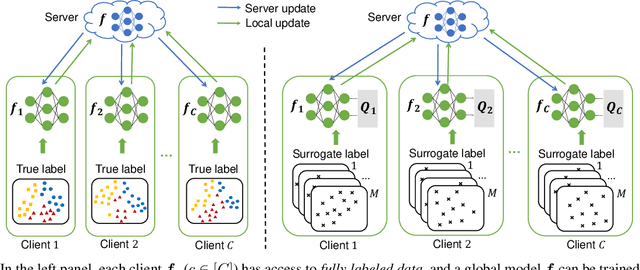
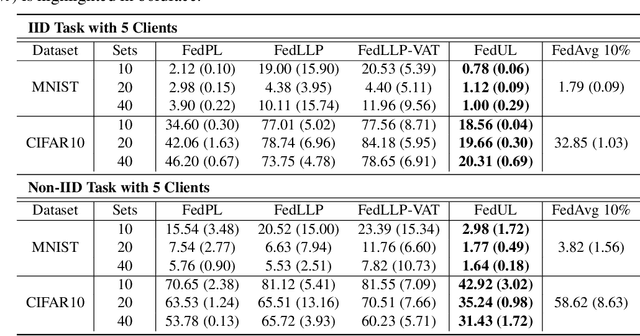
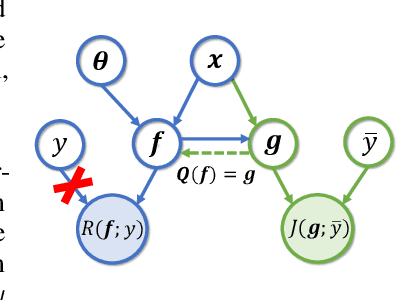
Supervised federated learning (FL) enables multiple clients to share the trained model without sharing their labeled data. However, potential clients might even be reluctant to label their own data, which could limit the applicability of FL in practice. In this paper, we show the possibility of unsupervised FL whose model is still a classifier for predicting class labels, if the class-prior probabilities are shifted while the class-conditional distributions are shared among the unlabeled data owned by the clients. We propose federation of unsupervised learning (FedUL), where the unlabeled data are transformed into surrogate labeled data for each of the clients, a modified model is trained by supervised FL, and the wanted model is recovered from the modified model. FedUL is a very general solution to unsupervised FL: it is compatible with many supervised FL methods, and the recovery of the wanted model can be theoretically guaranteed as if the data have been labeled. Experiments on benchmark and real-world datasets demonstrate the effectiveness of FedUL. Code is available at https://github.com/lunanbit/FedUL.
On the Effectiveness of Adversarial Training against Backdoor Attacks
Feb 22, 2022

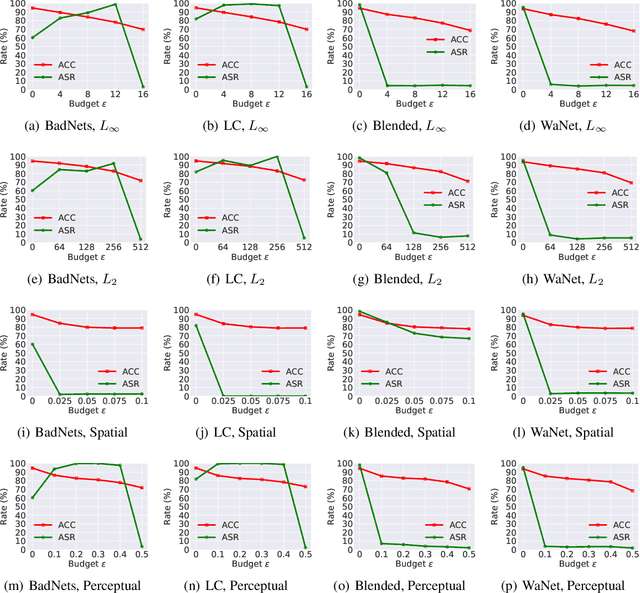
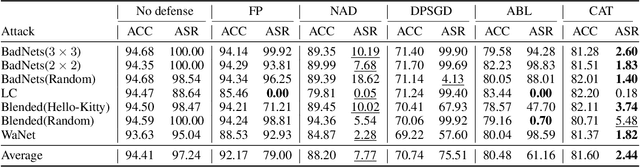
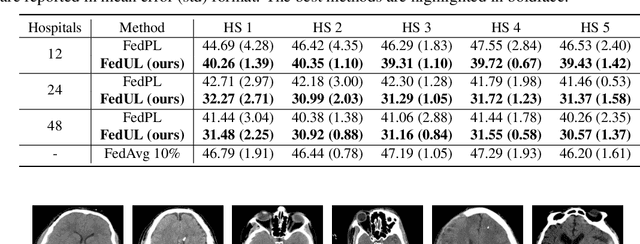
DNNs' demand for massive data forces practitioners to collect data from the Internet without careful check due to the unacceptable cost, which brings potential risks of backdoor attacks. A backdoored model always predicts a target class in the presence of a predefined trigger pattern, which can be easily realized via poisoning a small amount of data. In general, adversarial training is believed to defend against backdoor attacks since it helps models to keep their prediction unchanged even if we perturb the input image (as long as within a feasible range). Unfortunately, few previous studies succeed in doing so. To explore whether adversarial training could defend against backdoor attacks or not, we conduct extensive experiments across different threat models and perturbation budgets, and find the threat model in adversarial training matters. For instance, adversarial training with spatial adversarial examples provides notable robustness against commonly-used patch-based backdoor attacks. We further propose a hybrid strategy which provides satisfactory robustness across different backdoor attacks.
Is the Performance of My Deep Network Too Good to Be True? A Direct Approach to Estimating the Bayes Error in Binary Classification
Feb 01, 2022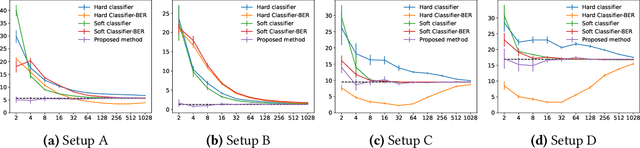

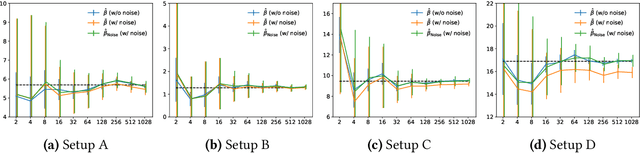

There is a fundamental limitation in the prediction performance that a machine learning model can achieve due to the inevitable uncertainty of the prediction target. In classification problems, this can be characterized by the Bayes error, which is the best achievable error with any classifier. The Bayes error can be used as a criterion to evaluate classifiers with state-of-the-art performance and can be used to detect test set overfitting. We propose a simple and direct Bayes error estimator, where we just take the mean of the labels that show \emph{uncertainty} of the classes. Our flexible approach enables us to perform Bayes error estimation even for weakly supervised data. In contrast to others, our method is model-free and even instance-free. Moreover, it has no hyperparameters and gives a more accurate estimate of the Bayes error than classifier-based baselines. Experiments using our method suggest that a recently proposed classifier, the Vision Transformer, may have already reached the Bayes error for certain benchmark datasets.
PiCO: Contrastive Label Disambiguation for Partial Label Learning
Jan 29, 2022
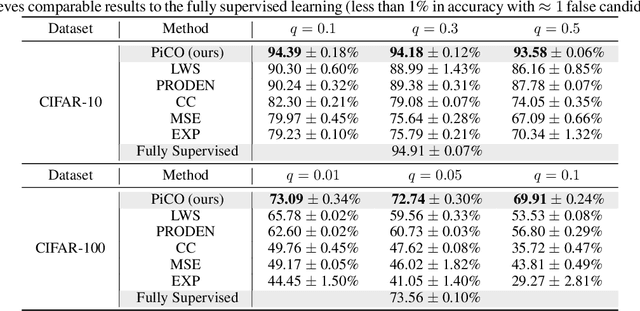
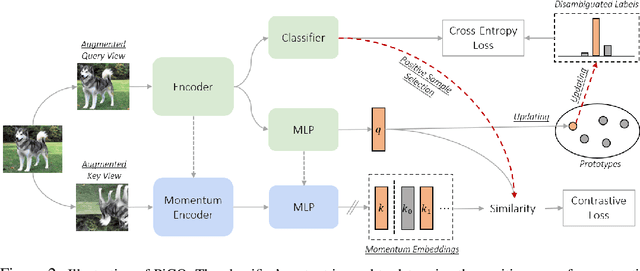

Partial label learning (PLL) is an important problem that allows each training example to be labeled with a coarse candidate set, which well suits many real-world data annotation scenarios with label ambiguity. Despite the promise, the performance of PLL often lags behind the supervised counterpart. In this work, we bridge the gap by addressing two key research challenges in PLL -- representation learning and label disambiguation -- in one coherent framework. Specifically, our proposed framework PiCO consists of a contrastive learning module along with a novel class prototype-based label disambiguation algorithm. PiCO produces closely aligned representations for examples from the same classes and facilitates label disambiguation. Theoretically, we show that these two components are mutually beneficial, and can be rigorously justified from an expectation-maximization (EM) algorithm perspective. Extensive experiments demonstrate that PiCO significantly outperforms the current state-of-the-art approaches in PLL and even achieves comparable results to fully supervised learning. Code and data available: https://github.com/hbzju/PiCO.
Learning with Noisy Labels Revisited: A Study Using Real-World Human Annotations
Oct 22, 2021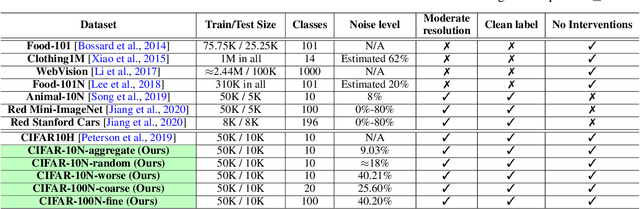


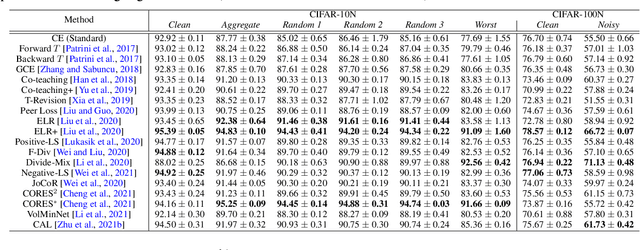
Existing research on learning with noisy labels mainly focuses on synthetic label noise. Synthetic label noise, though has clean structures which greatly enable statistical analyses, often fails to model the real-world noise patterns. The recent literature has observed several efforts to offer real-world noisy datasets, yet the existing efforts suffer from two caveats: firstly, the lack of ground-truth verification makes it hard to theoretically study the property and treatment of real-world label noise. Secondly, these efforts are often of large scales, which may lead to unfair comparisons of robust methods within reasonable and accessible computation power. To better understand real-world label noise, it is important to establish controllable and moderate-sized real-world noisy datasets with both ground-truth and noisy labels. This work presents two new benchmark datasets (CIFAR-10N, CIFAR-100N), equipping the train dataset of CIFAR-10 and CIFAR-100 with human-annotated real-world noisy labels that we collect from Amazon Mechanical Turk. We quantitatively and qualitatively show that real-world noisy labels follow an instance-dependent pattern rather than the classically adopted class-dependent ones. We then initiate an effort to benchmark a subset of existing solutions using CIFAR-10N, CIFAR-100N. We next proceed to study the memorization of model predictions, which further illustrates the difference between human noise and class-dependent synthetic noise. We show indeed the real-world noise patterns impose new and outstanding challenges as compared to synthetic ones. These observations require us to rethink the treatment of noisy labels, and we hope the availability of these two datasets would facilitate the development and evaluation of future learning with noisy label solutions. The corresponding datasets and the leaderboard are publicly available at \url{http://noisylabels.com}.