 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCoNaLa: A Benchmark for Code Generation from Multiple Natural Languages
Mar 16, 2022
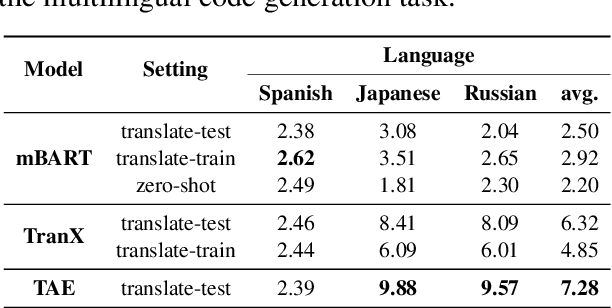

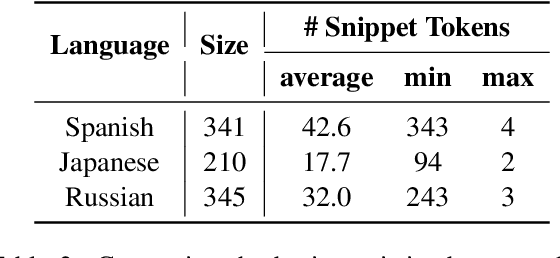
While there has been a recent burgeoning of applications at the intersection of natural and programming languages, such as code generation and code summarization, these applications are usually English-centric. This creates a barrier for program developers who are not proficient in English. To mitigate this gap in technology development across languages, we propose a multilingual dataset, MCoNaLa, to benchmark code generation from natural language commands extending beyond English. Modeled off of the methodology from the English Code/Natural Language Challenge (CoNaLa) dataset, we annotated a total of 896 NL-code pairs in three languages: Spanish, Japanese, and Russian. We present a quantitative evaluation of performance on the MCoNaLa dataset by testing with state-of-the-art code generation systems. While the difficulties vary across these three languages, all systems lag significantly behind their English counterparts, revealing the challenges in adapting code generation to new languages.
A Systematic Evaluation of Large Language Models of Code
Mar 01, 2022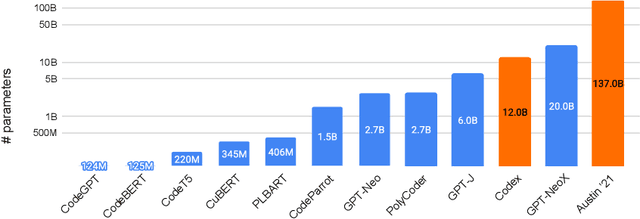
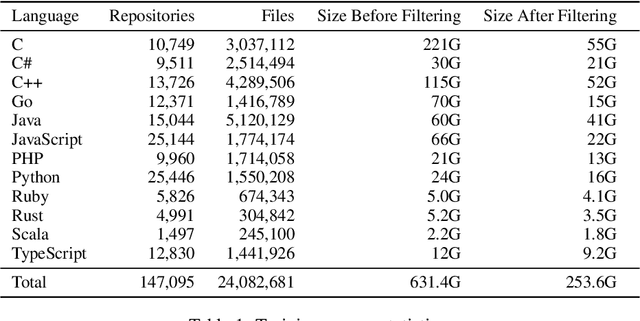

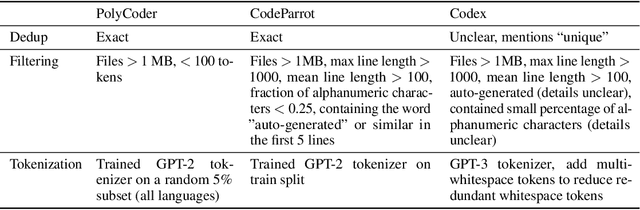
Large language models (LMs) of code have recently shown tremendous promise in completing code and synthesizing code from natural language descriptions. However, the current state-of-the-art code LMs (e.g., Codex (Chen et al., 2021)) are not publicly available, leaving many questions about their model and data design decisions. We aim to fill in some of these blanks through a systematic evaluation of the largest existing models: Codex, GPT-J, GPT-Neo, GPT-NeoX-20B, and CodeParrot, across various programming languages. Although Codex itself is not open-source, we find that existing open-source models do achieve close results in some programming languages, although targeted mainly for natural language modeling. We further identify an important missing piece in the form of a large open-source model trained exclusively on a multi-lingual corpus of code. We release a new model, PolyCoder, with 2.7B parameters based on the GPT-2 architecture, which was trained on 249GB of code across 12 programming languages on a single machine. In the C programming language, PolyCoder outperforms all models including Codex. Our trained models are open-source and publicly available at https://github.com/VHellendoorn/Code-LMs, which enables future research and application in this area.
Neuro-Symbolic Language Modeling with Automaton-augmented Retrieval
Jan 28, 2022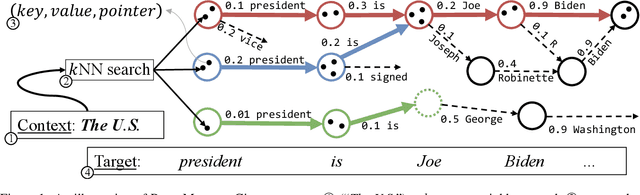
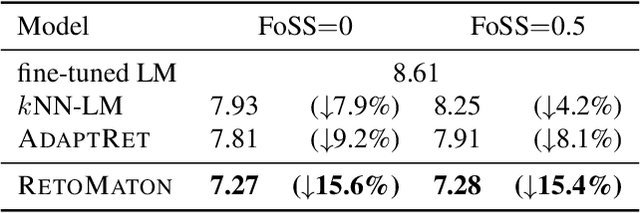
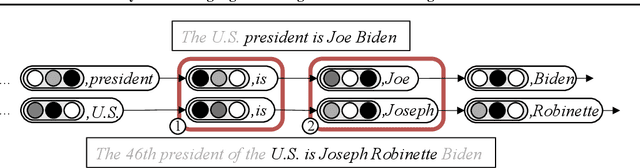

Retrieval-based language models (R-LM) model the probability of natural language text by combining a standard language model (LM) with examples retrieved from an external datastore at test time. While effective, a major bottleneck of using these models in practice is the computationally costly datastore search, which can be performed as frequently as every time step. In this paper, we present RetoMaton -- retrieval automaton -- which approximates the datastore search, based on (1) clustering of entries into "states", and (2) state transitions from previous entries. This effectively results in a weighted finite automaton built on top of the datastore, instead of representing the datastore as a flat list. The creation of the automaton is unsupervised, and a RetoMaton can be constructed from any text collection: either the original training corpus or from another domain. Traversing this automaton at inference time, in parallel to the LM inference, reduces its perplexity, or alternatively saves up to 83% of the nearest neighbor searches over kNN-LM (Khandelwal et al., 2020), without hurting perplexity.
Capturing Structural Locality in Non-parametric Language Models
Oct 06, 2021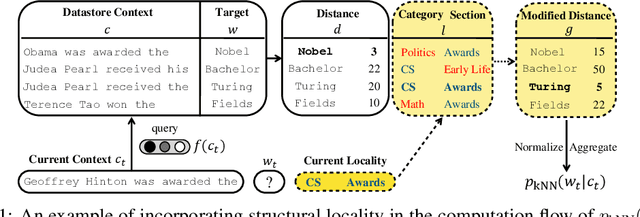

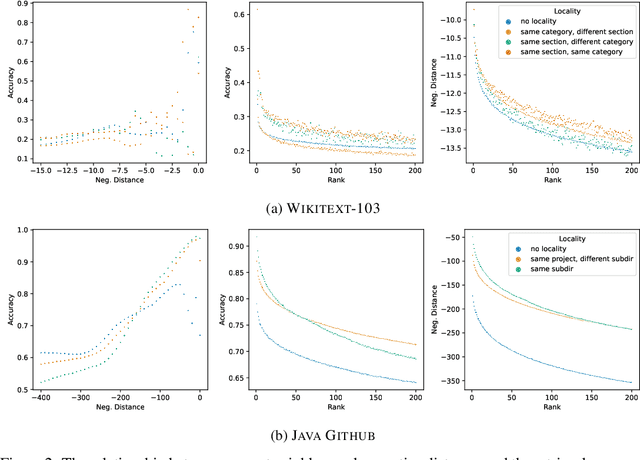
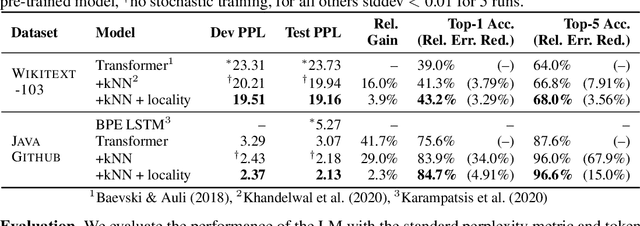
Structural locality is a ubiquitous feature of real-world datasets, wherein data points are organized into local hierarchies. Some examples include topical clusters in text or project hierarchies in source code repositories. In this paper, we explore utilizing this structural locality within non-parametric language models, which generate sequences that reference retrieved examples from an external source. We propose a simple yet effective approach for adding locality information into such models by adding learned parameters that improve the likelihood of retrieving examples from local neighborhoods. Experiments on two different domains, Java source code and Wikipedia text, demonstrate that locality features improve model efficacy over models without access to these features, with interesting differences. We also perform an analysis of how and where locality features contribute to improved performance and why the traditionally used contextual similarity metrics alone are not enough to grasp the locality structure.
Learning Structural Edits via Incremental Tree Transformations
Jan 28, 2021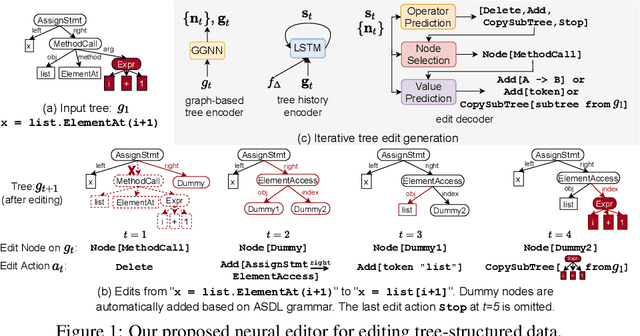


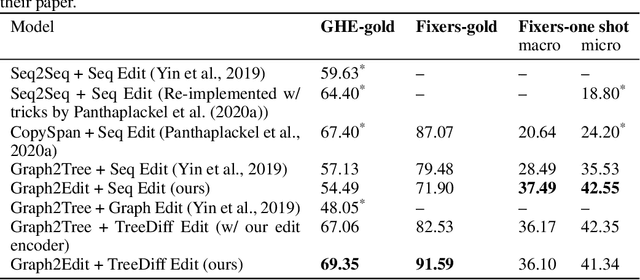
While most neural generative models generate outputs in a single pass, the human creative process is usually one of iterative building and refinement. Recent work has proposed models of editing processes, but these mostly focus on editing sequential data and/or only model a single editing pass. In this paper, we present a generic model for incremental editing of structured data (i.e., "structural edits"). Particularly, we focus on tree-structured data, taking abstract syntax trees of computer programs as our canonical example. Our editor learns to iteratively generate tree edits (e.g., deleting or adding a subtree) and applies them to the partially edited data, thereby the entire editing process can be formulated as consecutive, incremental tree transformations. To show the unique benefits of modeling tree edits directly, we further propose a novel edit encoder for learning to represent edits, as well as an imitation learning method that allows the editor to be more robust. We evaluate our proposed editor on two source code edit datasets, where results show that, with the proposed edit encoder, our editor significantly improves accuracy over previous approaches that generate the edited program directly in one pass. Finally, we demonstrate that training our editor to imitate experts and correct its mistakes dynamically can further improve its performance.
Minimally Supervised Categorization of Text with Metadata
Jun 02, 2020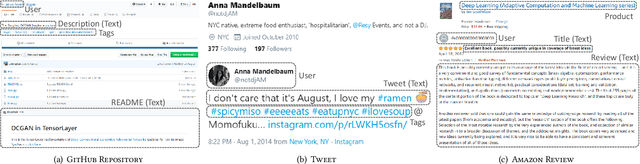
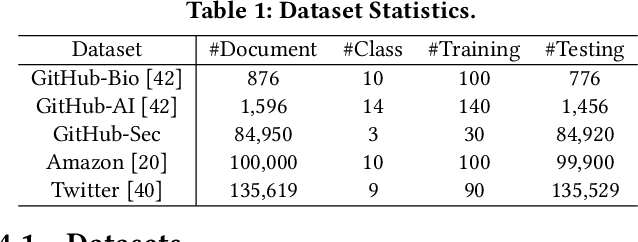
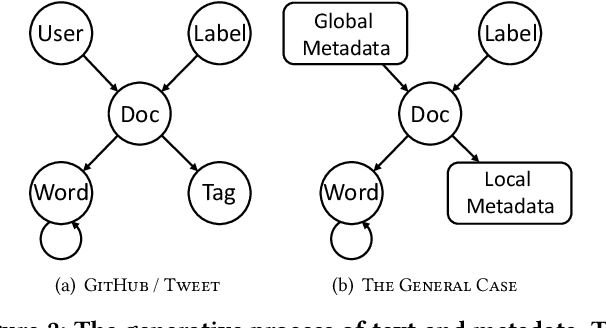
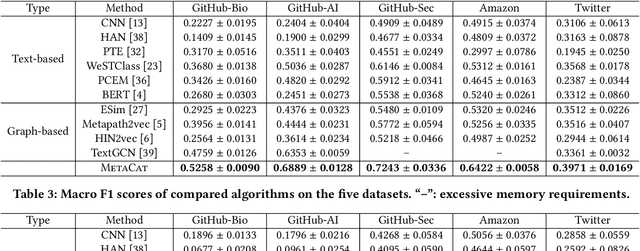
Document categorization, which aims to assign a topic label to each document, plays a fundamental role in a wide variety of applications. Despite the success of existing studies in conventional supervised document classification, they are less concerned with two real problems: (1) \textit{the presence of metadata}: in many domains, text is accompanied by various additional information such as authors and tags. Such metadata serve as compelling topic indicators and should be leveraged into the categorization framework; (2) \textit{label scarcity}: labeled training samples are expensive to obtain in some cases, where categorization needs to be performed using only a small set of annotated data. In recognition of these two challenges, we propose \textsc{MetaCat}, a minimally supervised framework to categorize text with metadata. Specifically, we develop a generative process describing the relationships between words, documents, labels, and metadata. Guided by the generative model, we embed text and metadata into the same semantic space to encode heterogeneous signals. Then, based on the same generative process, we synthesize training samples to address the bottleneck of label scarcity. We conduct a thorough evaluation on a wide range of datasets. Experimental results prove the effectiveness of \textsc{MetaCat} over many competitive baselines.
A Benchmark for Structured Procedural Knowledge Extraction from Cooking Videos
May 02, 2020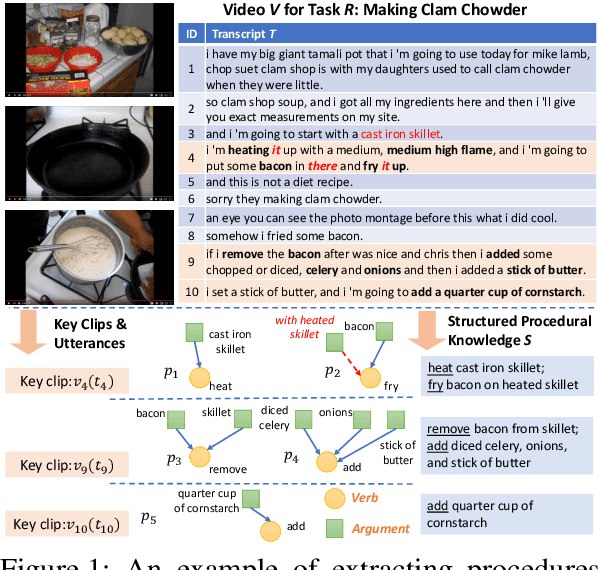
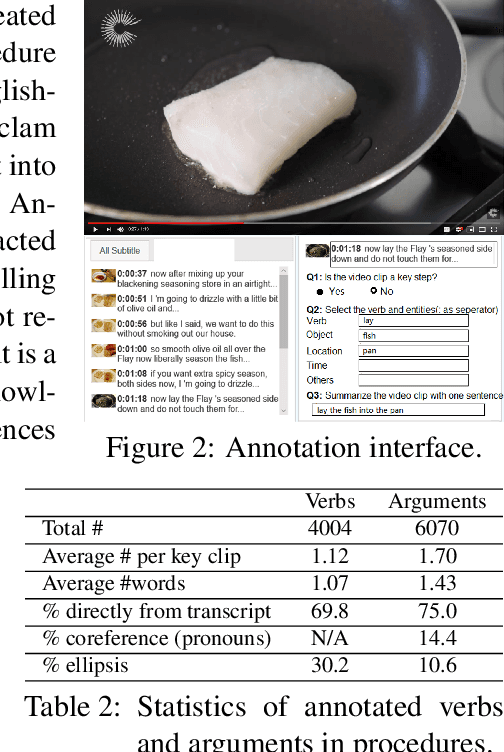

Procedural knowledge, which we define as concrete information about the sequence of actions that go into performing a particular procedure, plays an important role in understanding real-world tasks and actions. Humans often learn this knowledge from instructional text and video, and in this paper we aim to perform automatic extraction of this knowledge in a similar way. As a concrete step in this direction, we propose the new task of inferring procedures in a structured form(a data structure containing verbs and arguments) from multimodal instructional video contents and their corresponding transcripts. We first create a manually annotated, large evaluation dataset including over350 instructional cooking videos along with over 15,000 English sentences in transcripts spanning over 89 recipes. We conduct analysis of the challenges posed by this task and dataset with experiments with unsupervised segmentation, semantic role labeling, and visual action detection based baselines. The dataset and code will be publicly available at https://github.com/frankxu2004/cooking-procedural-extraction.
Incorporating External Knowledge through Pre-training for Natural Language to Code Generation
Apr 20, 2020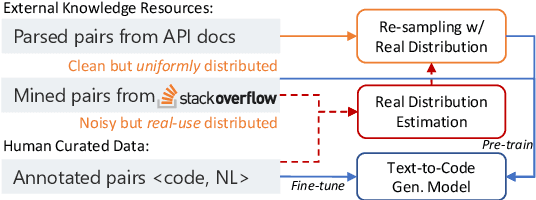
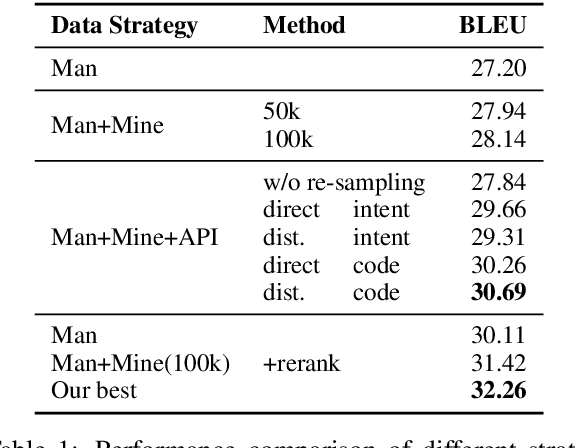


Open-domain code generation aims to generate code in a general-purpose programming language (such as Python) from natural language (NL) intents. Motivated by the intuition that developers usually retrieve resources on the web when writing code, we explore the effectiveness of incorporating two varieties of external knowledge into NL-to-code generation: automatically mined NL-code pairs from the online programming QA forum StackOverflow and programming language API documentation. Our evaluations show that combining the two sources with data augmentation and retrieval-based data re-sampling improves the current state-of-the-art by up to 2.2% absolute BLEU score on the code generation testbed CoNaLa. The code and resources are available at https://github.com/neulab/external-knowledge-codegen.
How Can We Know What Language Models Know?
Nov 28, 2019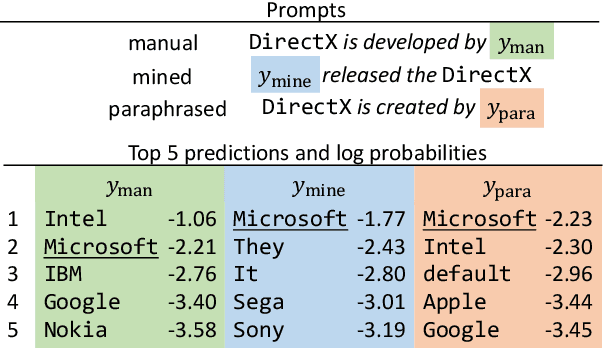
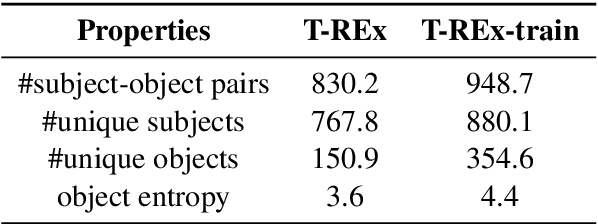
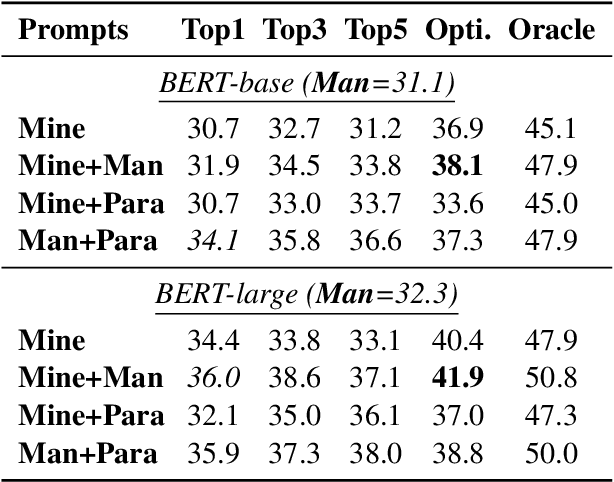
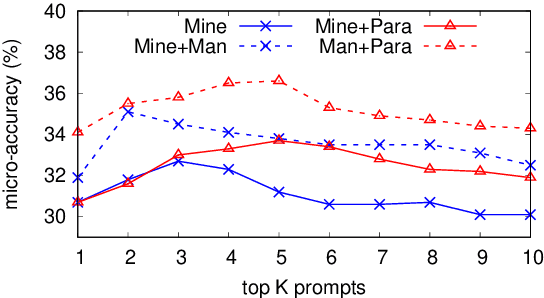
Recent work has presented intriguing results examining the knowledge contained in language models (LM) by having the LM fill in the blanks of prompts such as "Obama is a _ by profession". These prompts are usually manually created, and quite possibly sub-optimal; another prompt such as "Obama worked as a _" may result in more accurately predicting the correct profession. Because of this, given an inappropriate prompt, we might fail to retrieve facts that the LM does know, and thus any given prompt only provides a lower bound estimate of the knowledge contained in an LM. In this paper, we attempt to more accurately estimate the knowledge contained in LMs by automatically discovering better prompts to use in this querying process. Specifically, we propose mining-based and paraphrasing-based methods to automatically generate high-quality and diverse prompts and ensemble methods to combine answers from different prompts. Extensive experiments on the LAMA benchmark for extracting relational knowledge from LMs demonstrate that our methods can improve accuracy from 31.1% to 38.1%, providing a tighter lower bound on what LMs know. We have released the code and the resulting LM Prompt And Query Archive (LPAQA) at https://github.com/jzbjyb/LPAQA.
HiGitClass: Keyword-Driven Hierarchical Classification of GitHub Repositories
Oct 16, 2019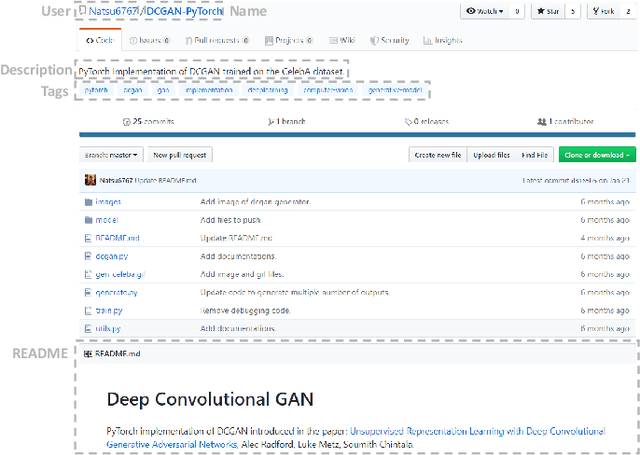
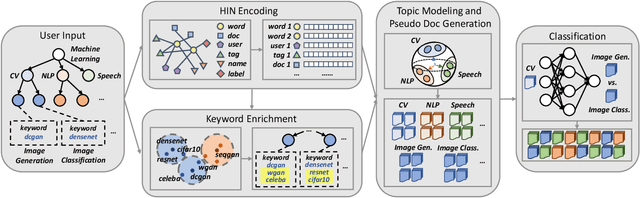
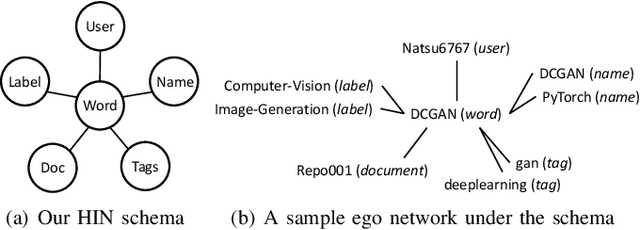
GitHub has become an important platform for code sharing and scientific exchange. With the massive number of repositories available, there is a pressing need for topic-based search. Even though the topic label functionality has been introduced, the majority of GitHub repositories do not have any labels, impeding the utility of search and topic-based analysis. This work targets the automatic repository classification problem as \textit{keyword-driven hierarchical classification}. Specifically, users only need to provide a label hierarchy with keywords to supply as supervision. This setting is flexible, adaptive to the users' needs, accounts for the different granularity of topic labels and requires minimal human effort. We identify three key challenges of this problem, namely (1) the presence of multi-modal signals; (2) supervision scarcity and bias; (3) supervision format mismatch. In recognition of these challenges, we propose the \textsc{HiGitClass} framework, comprising of three modules: heterogeneous information network embedding; keyword enrichment; topic modeling and pseudo document generation. Experimental results on two GitHub repository collections confirm that \textsc{HiGitClass} is superior to existing weakly-supervised and dataless hierarchical classification methods, especially in its ability to integrate both structured and unstructured data for repository classification.