 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating Impactful Autonomous Driving Datasets: A Strategic Guide from Research Gap to Benchmark
Jul 01, 2026Well-designed autonomous driving datasets have fundamentally shaped research progress, yet existing literature primarily describes what datasets contain rather than how to strategically design impactful ones. This is especially limiting for small and medium-sized labs and startups that cannot afford to misallocate scarce resources. We argue that impactful dataset creation begins with a diagnosis: whether a research question is blocked by a data problem or an evaluation problem, and proceeds by selecting the minimal data operator(s) that closes the resulting gap, recording new data only when no cheaper operator(s) suffices. We analyze the evolution of major autonomous driving (AD) datasets through this lens and distill a strategic framework spanning gap identification, operator choice, sensor suite design, and annotation strategy. We ground the framework in a running case study of our KITScenes dataset family. The datasets are available at: https://kitscenes.com/
The Road Ahead in Autonomous Driving: The KITScenes Multimodal Dataset
Jun 01, 2026Existing autonomous driving datasets have enabled major progress, but fall short in sensor fidelity, map completeness, or geographic diversity. We present KITScenes Multimodal, a European dataset built around high-fidelity sensors and maps. Our fully synchronized sensor suite combines high-resolution global-shutter cameras, long-range lidar beyond 400m, 4D imaging radar, and redundant GNSS/INS localization. Our HD maps are, to our knowledge, the most complete of any sensor dataset, validated through autonomous driving trials on open-source software. For the first time in a public dataset, all driving-relevant traffic elements, such as traffic lights, are mapped in 3D to a reprojection-accurate level with full topological connectivity. Recorded in cities with irregular street layouts and mixed traffic modes, our dataset complements existing datasets by broadening the available geographic diversity. We also introduce four benchmarks, each advancing spatial learning for embodied AI: online HD map construction, long-range depth estimation, novel view synthesis, and end-to-end driving. Project page: https://kitscenes.com/
Impact of Localization Errors on Label Quality for Online HD Map Construction
Mar 03, 2026High-definition (HD) maps are crucial for autonomous vehicles, but their creation and maintenance is very costly. This motivates the idea of online HD map construction. To provide a continuous large-scale stream of training data, existing HD maps can be used as labels for onboard sensor data from consumer vehicle fleets. However, compared to current, well curated HD map perception datasets, this fleet data suffers from localization errors, resulting in distorted map labels. We introduce three kinds of localization errors, Ramp, Gaussian, and Perlin noise, to examine their influence on generated map labels. We train a variant of MapTRv2, a state-of-the-art online HD map construction model, on the Argoverse 2 dataset with various levels of localization errors and assess the degradation of model performance. Since localization errors affect distant labels more severely, but are also less significant to driving performance, we introduce a distance-based map construction metric. Our experiments reveal that localization noise affects the model performance significantly. We demonstrate that errors in heading angle exert a more substantial influence than position errors, as angle errors result in a greater distortion of labels as distance to the vehicle increases. Furthermore, we can demonstrate that the model benefits from non-distorted ground truth (GT) data and that the performance decreases more than linearly with the increase in noisy data. Our study additionally provides a qualitative evaluation of the extent to which localization errors influence the construction of HD maps.
XD-MAP: Cross-Modal Domain Adaptation using Semantic Parametric Mapping
Jan 20, 2026Until open-world foundation models match the performance of specialized approaches, the effectiveness of deep learning models remains heavily dependent on dataset availability. Training data must align not only with the target object categories but also with the sensor characteristics and modalities. To bridge the gap between available datasets and deployment domains, domain adaptation strategies are widely used. In this work, we propose a novel approach to transferring sensor-specific knowledge from an image dataset to LiDAR, an entirely different sensing domain. Our method XD-MAP leverages detections from a neural network on camera images to create a semantic parametric map. The map elements are modeled to produce pseudo labels in the target domain without any manual annotation effort. Unlike previous domain transfer approaches, our method does not require direct overlap between sensors and enables extending the angular perception range from a front-view camera to a full 360 view. On our large-scale road feature dataset, XD-MAP outperforms single shot baseline approaches by +19.5 mIoU for 2D semantic segmentation, +19.5 PQth for 2D panoptic segmentation, and +32.3 mIoU in 3D semantic segmentation. The results demonstrate the effectiveness of our approach achieving strong performance on LiDAR data without any manual labeling.
SDTagNet: Leveraging Text-Annotated Navigation Maps for Online HD Map Construction
Jun 10, 2025Autonomous vehicles rely on detailed and accurate environmental information to operate safely. High definition (HD) maps offer a promising solution, but their high maintenance cost poses a significant barrier to scalable deployment. This challenge is addressed by online HD map construction methods, which generate local HD maps from live sensor data. However, these methods are inherently limited by the short perception range of onboard sensors. To overcome this limitation and improve general performance, recent approaches have explored the use of standard definition (SD) maps as prior, which are significantly easier to maintain. We propose SDTagNet, the first online HD map construction method that fully utilizes the information of widely available SD maps, like OpenStreetMap, to enhance far range detection accuracy. Our approach introduces two key innovations. First, in contrast to previous work, we incorporate not only polyline SD map data with manually selected classes, but additional semantic information in the form of textual annotations. In this way, we enrich SD vector map tokens with NLP-derived features, eliminating the dependency on predefined specifications or exhaustive class taxonomies. Second, we introduce a point-level SD map encoder together with orthogonal element identifiers to uniformly integrate all types of map elements. Experiments on Argoverse 2 and nuScenes show that this boosts map perception performance by up to +5.9 mAP (+45%) w.r.t. map construction without priors and up to +3.2 mAP (+20%) w.r.t. previous approaches that already use SD map priors. Code is available at https://github.com/immel-f/SDTagNet
M3TR: Generalist HD Map Construction with Variable Map Priors
Nov 15, 2024Autonomous vehicles require road information for their operation, usually in form of HD maps. Since offline maps eventually become outdated or may only be partially available, online HD map construction methods have been proposed to infer map information from live sensor data. A key issue remains how to exploit such partial or outdated map information as a prior. We introduce M3TR (Multi-Masking Map Transformer), a generalist approach for HD map construction both with and without map priors. We address shortcomings in ground truth generation for Argoverse 2 and nuScenes and propose the first realistic scenarios with semantically diverse map priors. Examining various query designs, we use an improved method for integrating prior map elements into a HD map construction model, increasing performance by +4.3 mAP. Finally, we show that training across all prior scenarios yields a single Generalist model, whose performance is on par with previous Expert models that can handle only one specific type of map prior. M3TR thus is the first model capable of leveraging variable map priors, making it suitable for real-world deployment. Code is available at https://github.com/immel-f/m3tr
Generation of Training Data from HD Maps in the Lanelet2 Framework
Jul 24, 2024Using HD maps directly as training data for machine learning tasks has seen a massive surge in popularity and shown promising results, e.g. in the field of map perception. Despite that, a standardized HD map framework supporting all parts of map-based automated driving and training label generation from map data does not exist. Furthermore, feeding map perception models with map data as part of the input during real-time inference is not addressed by the research community. In order to fill this gap, we presentlanelet2_ml_converter, an integrated extension to the HD map framework Lanelet2, widely used in automated driving systems by academia and industry. With this addition Lanelet2 unifies map based automated driving, machine learning inference and training, all from a single source of map data and format. Requirements for a unified framework are analyzed and the implementation of these requirements is described. The usability of labels in state of the art machine learning is demonstrated with application examples from the field of map perception. The source code is available embedded in the Lanelet2 framework under https://github.com/fzi-forschungszentrum-informatik/Lanelet2/tree/feature_ml_converter
Mapping LiDAR and Camera Measurements in a Dual Top-View Grid Representation Tailored for Automated Vehicles
Apr 21, 2022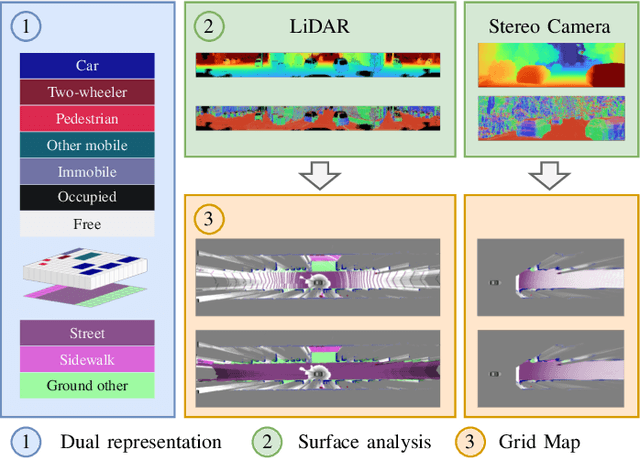

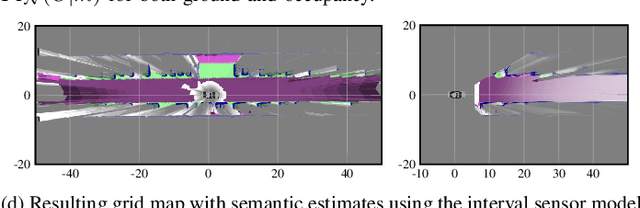

We present a generic evidential grid mapping pipeline designed for imaging sensors such as LiDARs and cameras. Our grid-based evidential model contains semantic estimates for cell occupancy and ground separately. We specify the estimation steps for input data represented by point sets, but mainly focus on input data represented by images such as disparity maps or LiDAR range images. Instead of relying on an external ground segmentation only, we deduce occupancy evidence by analyzing the surface orientation around measurements. We conduct experiments and evaluate the presented method using LiDAR and stereo camera data recorded in real traffic scenarios. Our method estimates cell occupancy robustly and with a high level of detail while maximizing efficiency and minimizing the dependency to external processing modules.
Sensor Data Fusion in Top-View Grid Maps using Evidential Reasoning with Advanced Conflict Resolution
Apr 19, 2022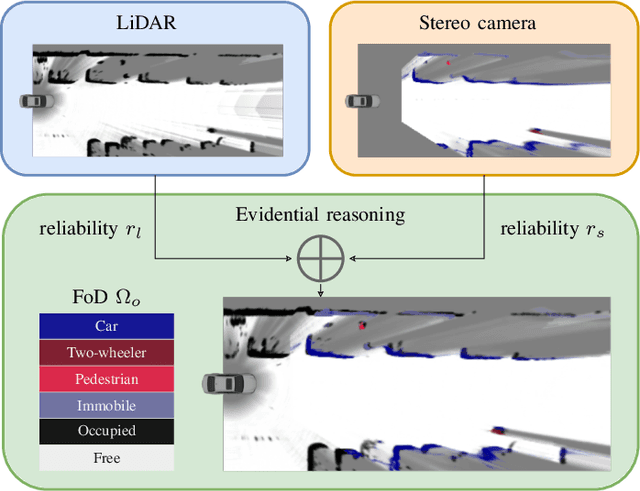
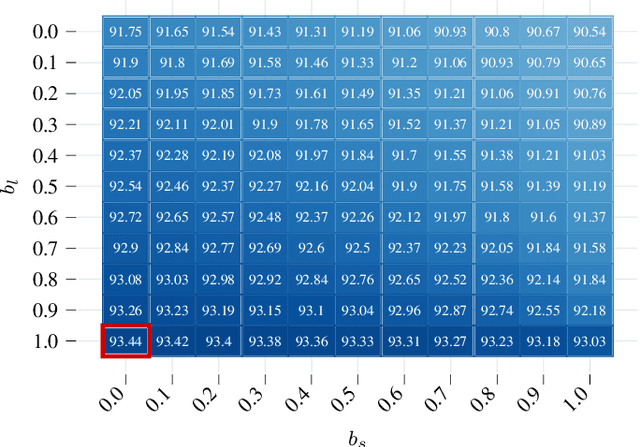

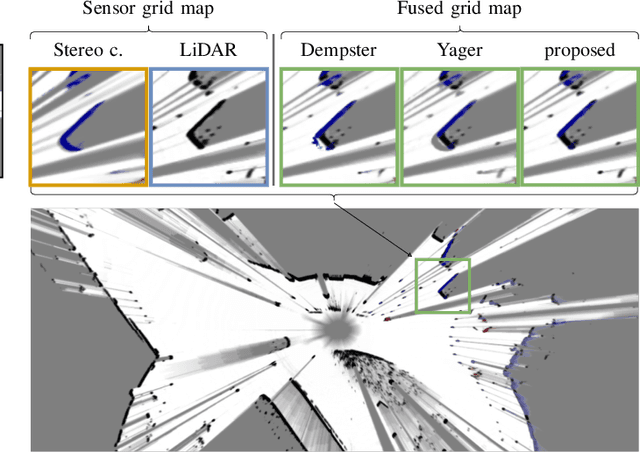
We present a new method to combine evidential top-view grid maps estimated based on heterogeneous sensor sources. Dempster's combination rule that is usually applied in this context provides undesired results with highly conflicting inputs. Therefore, we use more advanced evidential reasoning techniques and improve the conflict resolution by modeling the reliability of the evidence sources. We propose a data-driven reliability estimation to optimize the fusion quality using the Kitti-360 dataset. We apply the proposed method to the fusion of LiDAR and stereo camera data and evaluate the results qualitatively and quantitatively. The results demonstrate that our proposed method robustly combines measurements from heterogeneous sensors and successfully resolves sensor conflicts.
Fast and Robust Ground Surface Estimation from LIDAR Measurements using Uniform B-Splines
Mar 02, 2022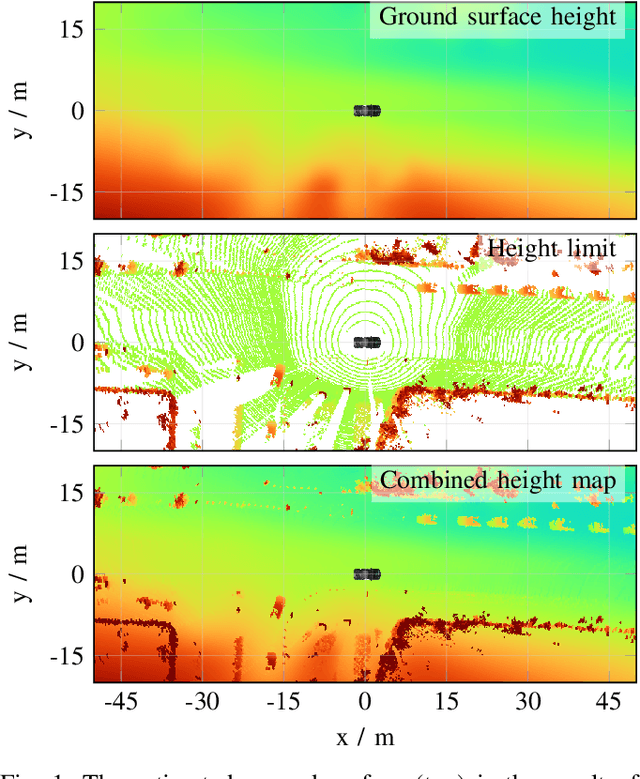

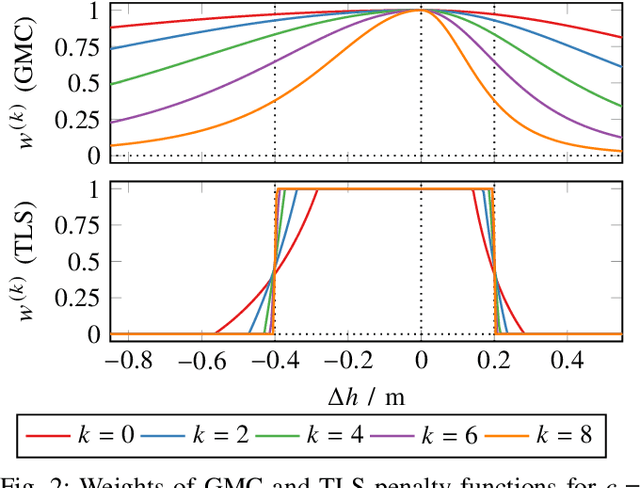
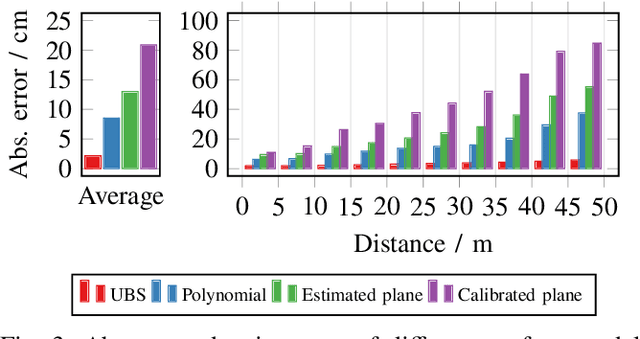
We propose a fast and robust method to estimate the ground surface from LIDAR measurements on an automated vehicle. The ground surface is modeled as a UBS which is robust towards varying measurement densities and with a single parameter controlling the smoothness prior. We model the estimation process as a robust LS optimization problem which can be reformulated as a linear problem and thus solved efficiently. Using the SemanticKITTI data set, we conduct a quantitative evaluation by classifying the point-wise semantic annotations into ground and non-ground points. Finally, we validate the approach on our research vehicle in real-world scenarios.