 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-modal Information Flow in Multimodal Large Language Models
Nov 27, 2024The recent advancements in auto-regressive multimodal large language models (MLLMs) have demonstrated promising progress for vision-language tasks. While there exists a variety of studies investigating the processing of linguistic information within large language models, little is currently known about the inner working mechanism of MLLMs and how linguistic and visual information interact within these models. In this study, we aim to fill this gap by examining the information flow between different modalities -- language and vision -- in MLLMs, focusing on visual question answering. Specifically, given an image-question pair as input, we investigate where in the model and how the visual and linguistic information are combined to generate the final prediction. Conducting experiments with a series of models from the LLaVA series, we find that there are two distinct stages in the process of integration of the two modalities. In the lower layers, the model first transfers the more general visual features of the whole image into the representations of (linguistic) question tokens. In the middle layers, it once again transfers visual information about specific objects relevant to the question to the respective token positions of the question. Finally, in the higher layers, the resulting multimodal representation is propagated to the last position of the input sequence for the final prediction. Overall, our findings provide a new and comprehensive perspective on the spatial and functional aspects of image and language processing in the MLLMs, thereby facilitating future research into multimodal information localization and editing.
MuPT: A Generative Symbolic Music Pretrained Transformer
Apr 10, 2024



In this paper, we explore the application of Large Language Models (LLMs) to the pre-training of music. While the prevalent use of MIDI in music modeling is well-established, our findings suggest that LLMs are inherently more compatible with ABC Notation, which aligns more closely with their design and strengths, thereby enhancing the model's performance in musical composition. To address the challenges associated with misaligned measures from different tracks during generation, we propose the development of a Synchronized Multi-Track ABC Notation (SMT-ABC Notation), which aims to preserve coherence across multiple musical tracks. Our contributions include a series of models capable of handling up to 8192 tokens, covering 90% of the symbolic music data in our training set. Furthermore, we explore the implications of the Symbolic Music Scaling Law (SMS Law) on model performance. The results indicate a promising direction for future research in music generation, offering extensive resources for community-led research through our open-source contributions.
FocDepthFormer: Transformer with LSTM for Depth Estimation from Focus
Oct 17, 2023



Depth estimation from focal stacks is a fundamental computer vision problem that aims to infer depth from focus/defocus cues in the image stacks. Most existing methods tackle this problem by applying convolutional neural networks (CNNs) with 2D or 3D convolutions over a set of fixed stack images to learn features across images and stacks. Their performance is restricted due to the local properties of the CNNs, and they are constrained to process a fixed number of stacks consistent in train and inference, limiting the generalization to the arbitrary length of stacks. To handle the above limitations, we develop a novel Transformer-based network, FocDepthFormer, composed mainly of a Transformer with an LSTM module and a CNN decoder. The self-attention in Transformer enables learning more informative features via an implicit non-local cross reference. The LSTM module is learned to integrate the representations across the stack with arbitrary images. To directly capture the low-level features of various degrees of focus/defocus, we propose to use multi-scale convolutional kernels in an early-stage encoder. Benefiting from the design with LSTM, our FocDepthFormer can be pre-trained with abundant monocular RGB depth estimation data for visual pattern capturing, alleviating the demand for the hard-to-collect focal stack data. Extensive experiments on various focal stack benchmark datasets show that our model outperforms the state-of-the-art models on multiple metrics.
TEScalib: Targetless Extrinsic Self-Calibration of LiDAR and Stereo Camera for Automated Driving Vehicles with Uncertainty Analysis
Feb 28, 2022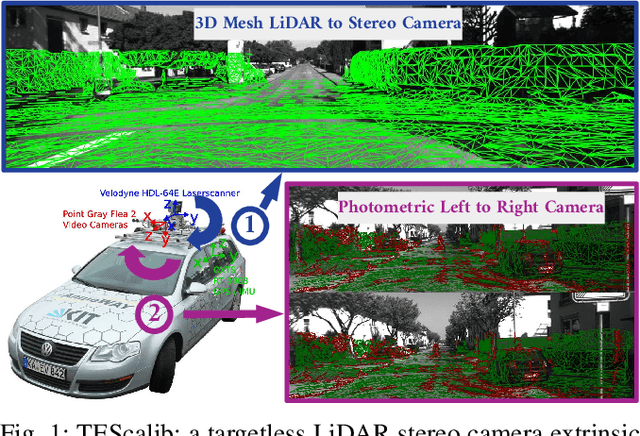
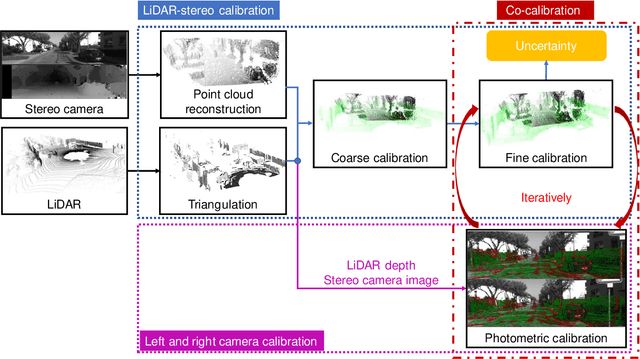
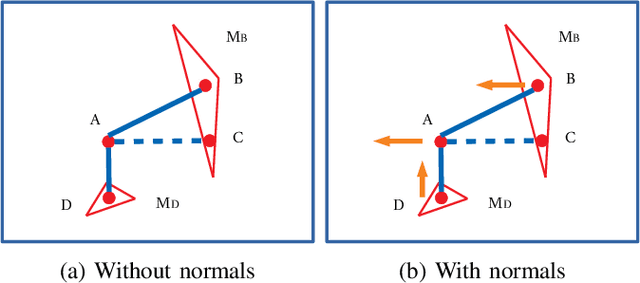
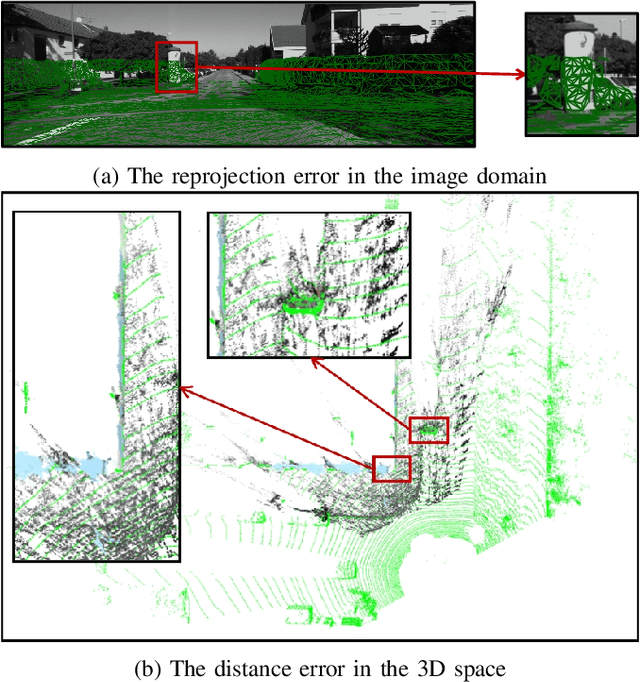
In this paper, we present TEScalib, a novel extrinsic self-calibration approach of LiDAR and stereo camera using the geometric and photometric information of surrounding environments without any calibration targets for automated driving vehicles. Since LiDAR and stereo camera are widely used for sensor data fusion on automated driving vehicles, their extrinsic calibration is highly important. However, most of the LiDAR and stereo camera calibration approaches are mainly target-based and therefore time consuming. Even the newly developed targetless approaches in last years are either inaccurate or unsuitable for driving platforms. To address those problems, we introduce TEScalib. By applying a 3D mesh reconstruction-based point cloud registration, the geometric information is used to estimate the LiDAR to stereo camera extrinsic parameters accurately and robustly. To calibrate the stereo camera, a photometric error function is builded and the LiDAR depth is involved to transform key points from one camera to another. During driving, these two parts are processed iteratively. Besides that, we also propose an uncertainty analysis for reflecting the reliability of the estimated extrinsic parameters. Our TEScalib approach evaluated on the KITTI dataset achieves very promising results.