 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing ESG Intelligence: An Expert-level Agent and Comprehensive Benchmark for Sustainable Finance
Jan 13, 2026Environmental, social, and governance (ESG) criteria are essential for evaluating corporate sustainability and ethical performance. However, professional ESG analysis is hindered by data fragmentation across unstructured sources, and existing large language models (LLMs) often struggle with the complex, multi-step workflows required for rigorous auditing. To address these limitations, we introduce ESGAgent, a hierarchical multi-agent system empowered by a specialized toolset, including retrieval augmentation, web search and domain-specific functions, to generate in-depth ESG analysis. Complementing this agentic system, we present a comprehensive three-level benchmark derived from 310 corporate sustainability reports, designed to evaluate capabilities ranging from atomic common-sense questions to the generation of integrated, in-depth analysis. Empirical evaluations demonstrate that ESGAgent outperforms state-of-the-art closed-source LLMs with an average accuracy of 84.15% on atomic question-answering tasks, and excels in professional report generation by integrating rich charts and verifiable references. These findings confirm the diagnostic value of our benchmark, establishing it as a vital testbed for assessing general and advanced agentic capabilities in high-stakes vertical domains.
Large-Scale 3D Semantic Reconstruction for Automated Driving Vehicles with Adaptive Truncated Signed Distance Function
Feb 28, 2022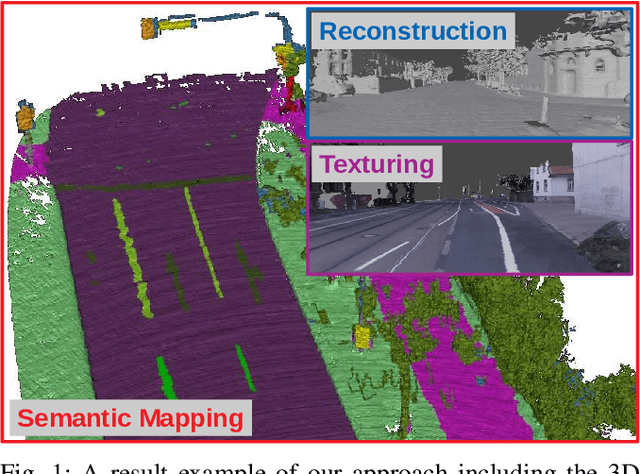
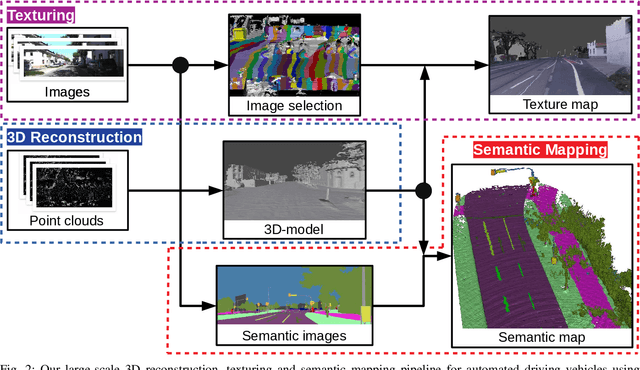
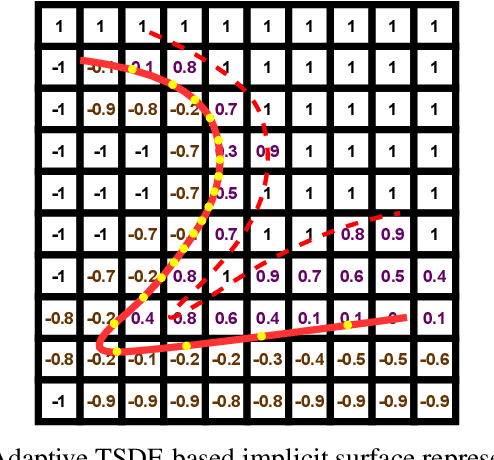

The Large-scale 3D reconstruction, texturing and semantic mapping are nowadays widely used for automated driving vehicles, virtual reality and automatic data generation. However, most approaches are developed for RGB-D cameras with colored dense point clouds and not suitable for large-scale outdoor environments using sparse LiDAR point clouds. Since a 3D surface can be usually observed from multiple camera images with different view poses, an optimal image patch selection for the texturing and an optimal semantic class estimation for the semantic mapping are still challenging. To address these problems, we propose a novel 3D reconstruction, texturing and semantic mapping system using LiDAR and camera sensors. An Adaptive Truncated Signed Distance Function is introduced to describe surfaces implicitly, which can deal with different LiDAR point sparsities and improve model quality. The from this implicit function extracted triangle mesh map is then textured from a series of registered camera images by applying an optimal image patch selection strategy. Besides that, a Markov Random Field-based data fusion approach is proposed to estimate the optimal semantic class for each triangle mesh. Our approach is evaluated on a synthetic dataset, the KITTI dataset and a dataset recorded with our experimental vehicle. The results show that the 3D models generated using our approach are more accurate in comparison to using other state-of-the-art approaches. The texturing and semantic mapping achieve also very promising results.