 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMC-Risk: Multi-Component Risk Fields for Risk Identification and Motion Planning
May 20, 2026We present MC-Risk, a planner-aligned, multi-component risk field on a bird's-eye-view grid that yields early, calibrated, and class-aware risk localization. MC-Risk linearly composes three interpretable modules: (i) a motorized-agent field that fuses a black-box multimodal trajectory predictor with an analytic Gaussian-torus construction whose lateral width grows with speed/curvature and whose height attenuates with look-ahead; (ii) a VRU risk field that replaces isotropic pedestrian blobs with a forward-biased anisotropic kernel aligned to heading and speed; and (iii) a road penalty field that exploits full HD-map topology, imposing an off-road penalty and lane-aware risk exposure for same/opposite directions. We conduct, to our knowledge, the first standardized quantitative evaluation of a risk-field formulation on RiskBench's collision subset. MC-Risk attains the best overall risk localization and the earliest hazard indication. Finally, we demonstrate a plug-and-play planning interface by using the field as an MPC cost density, enabling risk-aware trajectory generation without additional training.
Improving Lidar-Based Semantic Segmentation of Top-View Grid Maps by Learning Features in Complementary Representations
Mar 02, 2022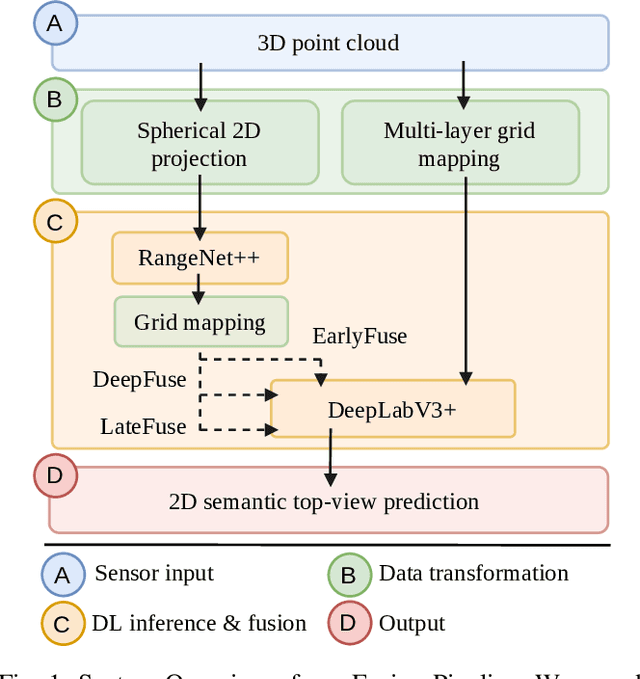
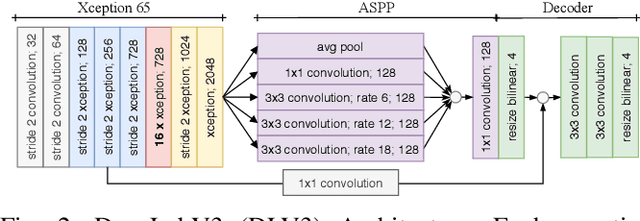
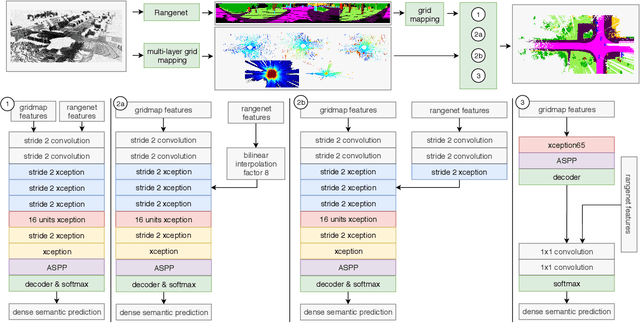

In this paper we introduce a novel way to predict semantic information from sparse, single-shot LiDAR measurements in the context of autonomous driving. In particular, we fuse learned features from complementary representations. The approach is aimed specifically at improving the semantic segmentation of top-view grid maps. Towards this goal the 3D LiDAR point cloud is projected onto two orthogonal 2D representations. For each representation a tailored deep learning architecture is developed to effectively extract semantic information which are fused by a superordinate deep neural network. The contribution of this work is threefold: (1) We examine different stages within the segmentation network for fusion. (2) We quantify the impact of embedding different features. (3) We use the findings of this survey to design a tailored deep neural network architecture leveraging respective advantages of different representations. Our method is evaluated using the SemanticKITTI dataset which provides a point-wise semantic annotation of more than 23.000 LiDAR measurements.