 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoLiMa: Long-Context Evaluation Beyond Literal Matching
Feb 07, 2025Recent large language models (LLMs) support long contexts ranging from 128K to 1M tokens. A popular method for evaluating these capabilities is the needle-in-a-haystack (NIAH) test, which involves retrieving a "needle" (relevant information) from a "haystack" (long irrelevant context). Extensions of this approach include increasing distractors, fact chaining, and in-context reasoning. However, in these benchmarks, models can exploit existing literal matches between the needle and haystack to simplify the task. To address this, we introduce NoLiMa, a benchmark extending NIAH with a carefully designed needle set, where questions and needles have minimal lexical overlap, requiring models to infer latent associations to locate the needle within the haystack. We evaluate 12 popular LLMs that claim to support contexts of at least 128K tokens. While they perform well in short contexts (<1K), performance degrades significantly as context length increases. At 32K, for instance, 10 models drop below 50% of their strong short-length baselines. Even GPT-4o, one of the top-performing exceptions, experiences a reduction from an almost-perfect baseline of 99.3% to 69.7%. Our analysis suggests these declines stem from the increased difficulty the attention mechanism faces in longer contexts when literal matches are absent, making it harder to retrieve relevant information.
ChartCitor: Multi-Agent Framework for Fine-Grained Chart Visual Attribution
Feb 03, 2025

Large Language Models (LLMs) can perform chart question-answering tasks but often generate unverified hallucinated responses. Existing answer attribution methods struggle to ground responses in source charts due to limited visual-semantic context, complex visual-text alignment requirements, and difficulties in bounding box prediction across complex layouts. We present ChartCitor, a multi-agent framework that provides fine-grained bounding box citations by identifying supporting evidence within chart images. The system orchestrates LLM agents to perform chart-to-table extraction, answer reformulation, table augmentation, evidence retrieval through pre-filtering and re-ranking, and table-to-chart mapping. ChartCitor outperforms existing baselines across different chart types. Qualitative user studies show that ChartCitor helps increase user trust in Generative AI by providing enhanced explainability for LLM-assisted chart QA and enables professionals to be more productive.
PlotGen: Multi-Agent LLM-based Scientific Data Visualization via Multimodal Feedback
Feb 03, 2025Scientific data visualization is pivotal for transforming raw data into comprehensible visual representations, enabling pattern recognition, forecasting, and the presentation of data-driven insights. However, novice users often face difficulties due to the complexity of selecting appropriate tools and mastering visualization techniques. Large Language Models (LLMs) have recently demonstrated potential in assisting code generation, though they struggle with accuracy and require iterative debugging. In this paper, we propose PlotGen, a novel multi-agent framework aimed at automating the creation of precise scientific visualizations. PlotGen orchestrates multiple LLM-based agents, including a Query Planning Agent that breaks down complex user requests into executable steps, a Code Generation Agent that converts pseudocode into executable Python code, and three retrieval feedback agents - a Numeric Feedback Agent, a Lexical Feedback Agent, and a Visual Feedback Agent - that leverage multimodal LLMs to iteratively refine the data accuracy, textual labels, and visual correctness of generated plots via self-reflection. Extensive experiments show that PlotGen outperforms strong baselines, achieving a 4-6 percent improvement on the MatPlotBench dataset, leading to enhanced user trust in LLM-generated visualizations and improved novice productivity due to a reduction in debugging time needed for plot errors.
PlotEdit: Natural Language-Driven Accessible Chart Editing in PDFs via Multimodal LLM Agents
Jan 20, 2025

Chart visualizations, while essential for data interpretation and communication, are predominantly accessible only as images in PDFs, lacking source data tables and stylistic information. To enable effective editing of charts in PDFs or digital scans, we present PlotEdit, a novel multi-agent framework for natural language-driven end-to-end chart image editing via self-reflective LLM agents. PlotEdit orchestrates five LLM agents: (1) Chart2Table for data table extraction, (2) Chart2Vision for style attribute identification, (3) Chart2Code for retrieving rendering code, (4) Instruction Decomposition Agent for parsing user requests into executable steps, and (5) Multimodal Editing Agent for implementing nuanced chart component modifications - all coordinated through multimodal feedback to maintain visual fidelity. PlotEdit outperforms existing baselines on the ChartCraft dataset across style, layout, format, and data-centric edits, enhancing accessibility for visually challenged users and improving novice productivity.
Personalized Graph-Based Retrieval for Large Language Models
Jan 04, 2025As large language models (LLMs) evolve, their ability to deliver personalized and context-aware responses offers transformative potential for improving user experiences. Existing personalization approaches, however, often rely solely on user history to augment the prompt, limiting their effectiveness in generating tailored outputs, especially in cold-start scenarios with sparse data. To address these limitations, we propose Personalized Graph-based Retrieval-Augmented Generation (PGraphRAG), a framework that leverages user-centric knowledge graphs to enrich personalization. By directly integrating structured user knowledge into the retrieval process and augmenting prompts with user-relevant context, PGraphRAG enhances contextual understanding and output quality. We also introduce the Personalized Graph-based Benchmark for Text Generation, designed to evaluate personalized text generation tasks in real-world settings where user history is sparse or unavailable. Experimental results show that PGraphRAG significantly outperforms state-of-the-art personalization methods across diverse tasks, demonstrating the unique advantages of graph-based retrieval for personalization.
LUSIFER: Language Universal Space Integration for Enhanced Multilingual Embeddings with Large Language Models
Jan 01, 2025



Recent advancements in large language models (LLMs) based embedding models have established new state-of-the-art benchmarks for text embedding tasks, particularly in dense vector-based retrieval. However, these models predominantly focus on English, leaving multilingual embedding capabilities largely unexplored. To address this limitation, we present LUSIFER, a novel zero-shot approach that adapts LLM-based embedding models for multilingual tasks without requiring multilingual supervision. LUSIFER's architecture combines a multilingual encoder, serving as a language-universal learner, with an LLM-based embedding model optimized for embedding-specific tasks. These components are seamlessly integrated through a minimal set of trainable parameters that act as a connector, effectively transferring the multilingual encoder's language understanding capabilities to the specialized embedding model. Additionally, to comprehensively evaluate multilingual embedding performance, we introduce a new benchmark encompassing 5 primary embedding tasks, 123 diverse datasets, and coverage across 14 languages. Extensive experimental results demonstrate that LUSIFER significantly enhances the multilingual performance across various embedding tasks, particularly for medium and low-resource languages, without requiring explicit multilingual training data.
Multi-LLM Text Summarization
Dec 20, 2024



In this work, we propose a Multi-LLM summarization framework, and investigate two different multi-LLM strategies including centralized and decentralized. Our multi-LLM summarization framework has two fundamentally important steps at each round of conversation: generation and evaluation. These steps are different depending on whether our multi-LLM decentralized summarization is used or centralized. In both our multi-LLM decentralized and centralized strategies, we have k different LLMs that generate diverse summaries of the text. However, during evaluation, our multi-LLM centralized summarization approach leverages a single LLM to evaluate the summaries and select the best one whereas k LLMs are used for decentralized multi-LLM summarization. Overall, we find that our multi-LLM summarization approaches significantly outperform the baselines that leverage only a single LLM by up to 3x. These results indicate the effectiveness of multi-LLM approaches for summarization.
GUI Agents: A Survey
Dec 18, 2024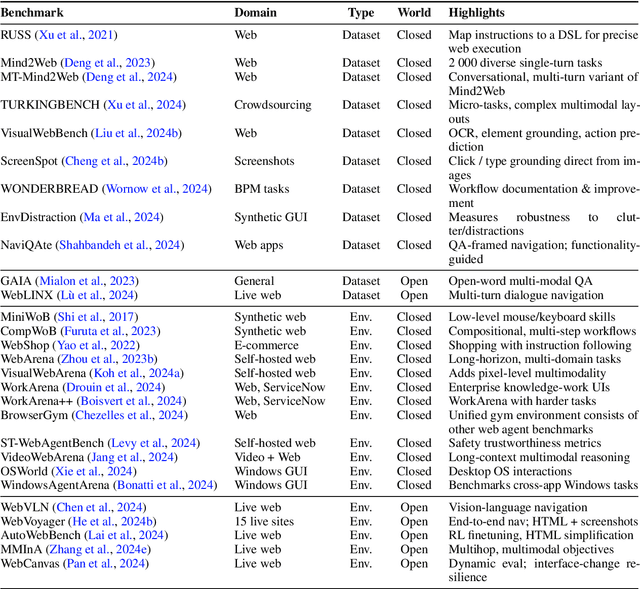
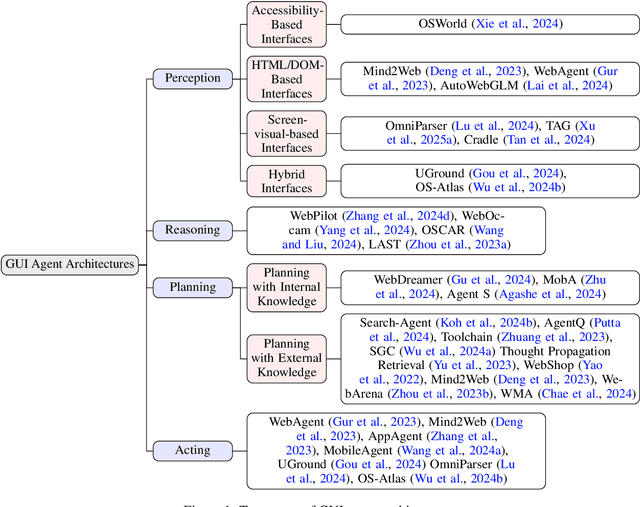

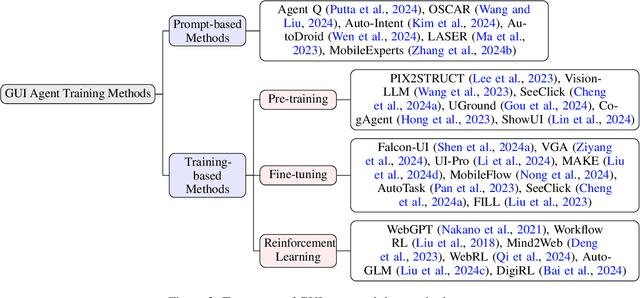
Graphical User Interface (GUI) agents, powered by Large Foundation Models, have emerged as a transformative approach to automating human-computer interaction. These agents autonomously interact with digital systems or software applications via GUIs, emulating human actions such as clicking, typing, and navigating visual elements across diverse platforms. Motivated by the growing interest and fundamental importance of GUI agents, we provide a comprehensive survey that categorizes their benchmarks, evaluation metrics, architectures, and training methods. We propose a unified framework that delineates their perception, reasoning, planning, and acting capabilities. Furthermore, we identify important open challenges and discuss key future directions. Finally, this work serves as a basis for practitioners and researchers to gain an intuitive understanding of current progress, techniques, benchmarks, and critical open problems that remain to be addressed.
VisDoM: Multi-Document QA with Visually Rich Elements Using Multimodal Retrieval-Augmented Generation
Dec 14, 2024



Understanding information from a collection of multiple documents, particularly those with visually rich elements, is important for document-grounded question answering. This paper introduces VisDoMBench, the first comprehensive benchmark designed to evaluate QA systems in multi-document settings with rich multimodal content, including tables, charts, and presentation slides. We propose VisDoMRAG, a novel multimodal Retrieval Augmented Generation (RAG) approach that simultaneously utilizes visual and textual RAG, combining robust visual retrieval capabilities with sophisticated linguistic reasoning. VisDoMRAG employs a multi-step reasoning process encompassing evidence curation and chain-of-thought reasoning for concurrent textual and visual RAG pipelines. A key novelty of VisDoMRAG is its consistency-constrained modality fusion mechanism, which aligns the reasoning processes across modalities at inference time to produce a coherent final answer. This leads to enhanced accuracy in scenarios where critical information is distributed across modalities and improved answer verifiability through implicit context attribution. Through extensive experiments involving open-source and proprietary large language models, we benchmark state-of-the-art document QA methods on VisDoMBench. Extensive results show that VisDoMRAG outperforms unimodal and long-context LLM baselines for end-to-end multimodal document QA by 12-20%.
Domain-specific Question Answering with Hybrid Search
Dec 04, 2024



Domain specific question answering is an evolving field that requires specialized solutions to address unique challenges. In this paper, we show that a hybrid approach combining a fine-tuned dense retriever with keyword based sparse search methods significantly enhances performance. Our system leverages a linear combination of relevance signals, including cosine similarity from dense retrieval, BM25 scores, and URL host matching, each with tunable boost parameters. Experimental results indicate that this hybrid method outperforms our single-retriever system, achieving improved accuracy while maintaining robust contextual grounding. These findings suggest that integrating multiple retrieval methodologies with weighted scoring effectively addresses the complexities of domain specific question answering in enterprise settings.