 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouteNator: A Router-Based Multi-Modal Architecture for Generating Synthetic Training Data for Function Calling LLMs
May 15, 2025



This paper addresses fine-tuning Large Language Models (LLMs) for function calling tasks when real user interaction data is unavailable. In digital content creation tools, where users express their needs through natural language queries that must be mapped to API calls, the lack of real-world task-specific data and privacy constraints for training on it necessitate synthetic data generation. Existing approaches to synthetic data generation fall short in diversity and complexity, failing to replicate real-world data distributions and leading to suboptimal performance after LLM fine-tuning. We present a novel router-based architecture that leverages domain resources like content metadata and structured knowledge graphs, along with text-to-text and vision-to-text language models to generate high-quality synthetic training data. Our architecture's flexible routing mechanism enables synthetic data generation that matches observed real-world distributions, addressing a fundamental limitation of traditional approaches. Evaluation on a comprehensive set of real user queries demonstrates significant improvements in both function classification accuracy and API parameter selection. Models fine-tuned with our synthetic data consistently outperform traditional approaches, establishing new benchmarks for function calling tasks.
* Proceedings of the 4th International Workshop on Knowledge-Augmented Methods for Natural Language Processing
Domain-specific Question Answering with Hybrid Search
Dec 04, 2024



Domain specific question answering is an evolving field that requires specialized solutions to address unique challenges. In this paper, we show that a hybrid approach combining a fine-tuned dense retriever with keyword based sparse search methods significantly enhances performance. Our system leverages a linear combination of relevance signals, including cosine similarity from dense retrieval, BM25 scores, and URL host matching, each with tunable boost parameters. Experimental results indicate that this hybrid method outperforms our single-retriever system, achieving improved accuracy while maintaining robust contextual grounding. These findings suggest that integrating multiple retrieval methodologies with weighted scoring effectively addresses the complexities of domain specific question answering in enterprise settings.
Probabilistic Semantic Inpainting with Pixel Constrained CNNs
Oct 08, 2018
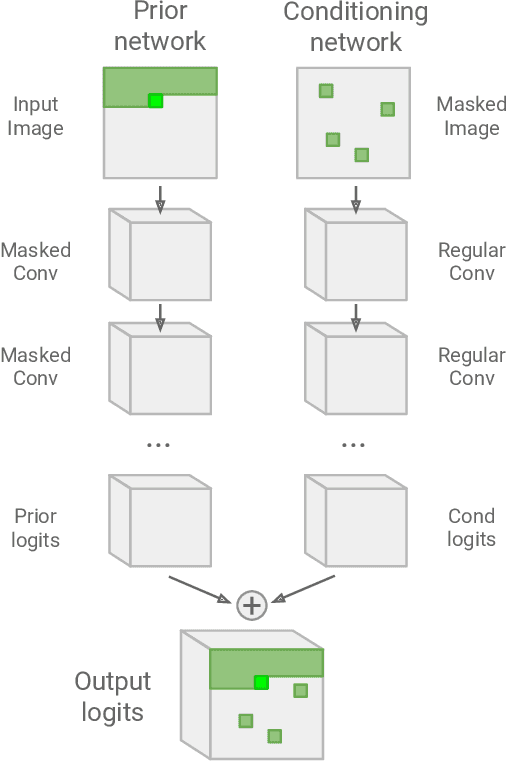


Semantic inpainting is the task of inferring missing pixels in an image given surrounding pixels and high level image semantics. Most semantic inpainting algorithms are deterministic: given an image with missing regions, a single inpainted image is generated. However, there are often several plausible inpaintings for a given missing region. In this paper, we propose a method to perform probabilistic semantic inpainting by building a model, based on PixelCNNs, that learns a distribution of images conditioned on a subset of visible pixels. Experiments on the MNIST and CelebA datasets show that our method produces diverse and realistic inpaintings. Further, our model also estimates the likelihood of each sample which we show correlates well with the realism of the generated inpaintings.