 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnosing Failure Modes of Shared-State Collaboration in Resource-Constrained Visual Agents
May 29, 2026Modular visual reasoning systems increasingly rely on shared working memory for multi-step collaboration, yet the failure dynamics of intermediate state evolution in low-capacity regimes remain underexplored. We study failure modes of collaborative reasoning with weak learners (4B--8B models) through the lens of noise accumulation. We introduce CoSee, an auditing framework that formalizes the read-write-verify loop to trace information flow in document visual question answering. Across multi-page, chart, and web-based benchmarks, we find a counter-intuitive degradation: naive shared workspaces often amplify hallucinations rather than resolve them. We identify two dominant failure modes: Noise Reinforcement, where ungrounded notes are reused as evidence, and Policy Collapse, where added context shifts the model toward under-specified, short-form answers. Using cost-accuracy Pareto frontiers, we show that increased compute can correlate negatively with performance without explicit verification. Our findings suggest that for resource-constrained agents, the bottleneck lies not in reasoning depth but in communication fidelity, providing trace-level diagnostics and a mechanistic baseline for reliable modular design.
Pixelis: Reasoning in Pixels, from Seeing to Acting
Mar 26, 2026Most vision-language systems are static observers: they describe pixels, do not act, and cannot safely improve under shift. This passivity limits generalizable, physically grounded visual intelligence. Learning through action, not static description, is essential beyond curated data. We present Pixelis, a pixel-space agent that operates directly on images and videos via a compact set of executable operations (zoom/crop, segment, track, OCR, temporal localization) and learns from its consequences. Pixelis trains in three phases: (1) Supervised Fine-Tuning learns a pixel-tool grammar from Chain-of-Thought-Action traces with a masked imitation loss that upweights operation/argument tokens and auxiliary heads to stabilize pixel-grounded arguments; (2) Curiosity-Coherence Reward Fine-Tuning optimizes a dual-drive objective marrying prediction-error curiosity with adjacent-step coherence and a mild efficiency prior under a KL anchor, yielding short, valid, structured toolchains; (3) Pixel Test-Time RL performs label-free adaptation by retrieving neighbors, voting over complete trajectories rather than answers, and updating toward short, high-fidelity exemplars while constraining drift with a KL-to-EMA safety control. Across six public image and video benchmarks, Pixelis yields consistent improvements: the average relative gain is +4.08% over the same 8B baseline (peaking at +6.03% on VSI-Bench), computed as (ours-baseline)/baseline, while producing shorter, auditable toolchains and maintaining in-corridor KL during test-time learning. Acting within pixels, rather than abstract tokens, grounds multimodal perception in the physical world, linking visual reasoning with actionable outcomes, and enables embodied adaptation without external feedback.
Sparse Visual Thought Circuits in Vision-Language Models
Mar 26, 2026Sparse autoencoders (SAEs) improve interpretability in multimodal models, but it remains unclear whether SAE features form modular, composable units for reasoning-an assumption underlying many intervention-based steering methods. We test this modularity hypothesis and find it often fails: intervening on a task-selective feature set can modestly improve reasoning accuracy, while intervening on the union of two such sets reliably induces output drift (large unintended changes in predictions) and degrades accuracy, even under norm-matched perturbations. This non modular circuit interference is consistent with shared internal pathways where feature unions amplify activation shifts. We develop a reproducible causal pipeline to localize and test these sparse visual thought circuits in Qwen3-VL-8B. On a controlled synthetic benchmark with seven task types and three difficulty levels, linear probes identify a mid decoder locus for task type information. We train SAEs at this layer, construct task-selective sets via an explicit rule, and perform inference time scaling and ablation while quantifying accuracy and drift. Our findings-validated with bootstrapped subsamples and permutation controls, and replicated across multiple VLM families and five diverse datasets clarify the boundaries of SAE feature composability and provide a rigorous diagnostic framework for more reliable VLM control.
Fairness-Aware Deepfake Detection: Leveraging Dual-Mechanism Optimization
Nov 19, 2025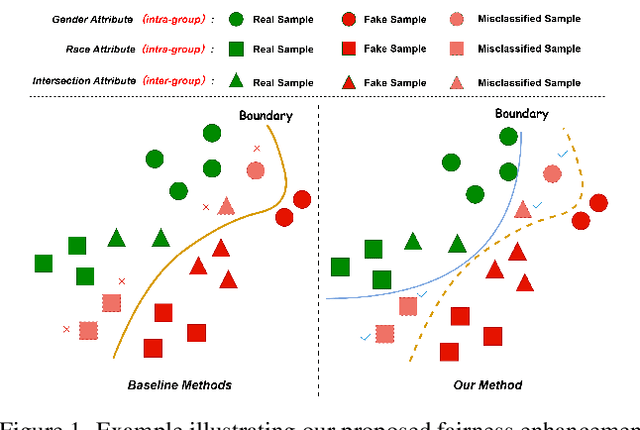
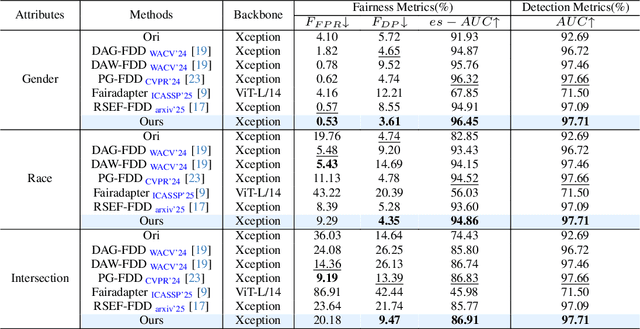
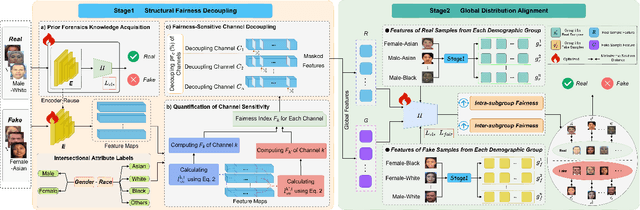
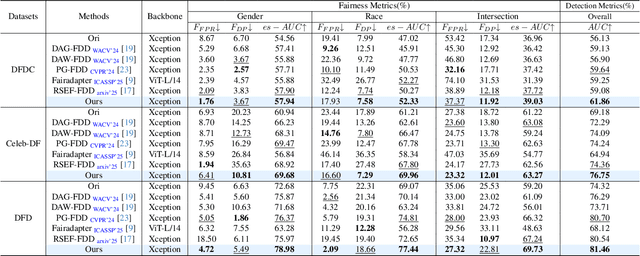
Fairness is a core element in the trustworthy deployment of deepfake detection models, especially in the field of digital identity security. Biases in detection models toward different demographic groups, such as gender and race, may lead to systemic misjudgments, exacerbating the digital divide and social inequities. However, current fairness-enhanced detectors often improve fairness at the cost of detection accuracy. To address this challenge, we propose a dual-mechanism collaborative optimization framework. Our proposed method innovatively integrates structural fairness decoupling and global distribution alignment: decoupling channels sensitive to demographic groups at the model architectural level, and subsequently reducing the distance between the overall sample distribution and the distributions corresponding to each demographic group at the feature level. Experimental results demonstrate that, compared with other methods, our framework improves both inter-group and intra-group fairness while maintaining overall detection accuracy across domains.