 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerraFM: A Scalable Foundation Model for Unified Multisensor Earth Observation
Jun 06, 2025Modern Earth observation (EO) increasingly leverages deep learning to harness the scale and diversity of satellite imagery across sensors and regions. While recent foundation models have demonstrated promising generalization across EO tasks, many remain limited by the scale, geographical coverage, and spectral diversity of their training data, factors critical for learning globally transferable representations. In this work, we introduce TerraFM, a scalable self-supervised learning model that leverages globally distributed Sentinel-1 and Sentinel-2 imagery, combined with large spatial tiles and land-cover aware sampling to enrich spatial and semantic coverage. By treating sensing modalities as natural augmentations in our self-supervised approach, we unify radar and optical inputs via modality-specific patch embeddings and adaptive cross-attention fusion. Our training strategy integrates local-global contrastive learning and introduces a dual-centering mechanism that incorporates class-frequency-aware regularization to address long-tailed distributions in land cover.TerraFM achieves strong generalization on both classification and segmentation tasks, outperforming prior models on GEO-Bench and Copernicus-Bench. Our code and pretrained models are publicly available at: https://github.com/mbzuai-oryx/TerraFM .
VideoMolmo: Spatio-Temporal Grounding Meets Pointing
Jun 05, 2025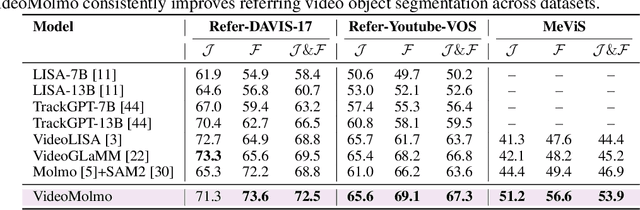



Spatio-temporal localization is vital for precise interactions across diverse domains, from biological research to autonomous navigation and interactive interfaces. Current video-based approaches, while proficient in tracking, lack the sophisticated reasoning capabilities of large language models, limiting their contextual understanding and generalization. We introduce VideoMolmo, a large multimodal model tailored for fine-grained spatio-temporal pointing conditioned on textual descriptions. Building upon the Molmo architecture, VideoMolmo incorporates a temporal module utilizing an attention mechanism to condition each frame on preceding frames, ensuring temporal consistency. Additionally, our novel temporal mask fusion pipeline employs SAM2 for bidirectional point propagation, significantly enhancing coherence across video sequences. This two-step decomposition, i.e., first using the LLM to generate precise pointing coordinates, then relying on a sequential mask-fusion module to produce coherent segmentation, not only simplifies the task for the language model but also enhances interpretability. Due to the lack of suitable datasets, we curate a comprehensive dataset comprising 72k video-caption pairs annotated with 100k object points. To evaluate the generalization of VideoMolmo, we introduce VPoS-Bench, a challenging out-of-distribution benchmark spanning five real-world scenarios: Cell Tracking, Egocentric Vision, Autonomous Driving, Video-GUI Interaction, and Robotics. We also evaluate our model on Referring Video Object Segmentation (Refer-VOS) and Reasoning VOS tasks. In comparison to existing models, VideoMolmo substantially improves spatio-temporal pointing accuracy and reasoning capability. Our code and models are publicly available at https://github.com/mbzuai-oryx/VideoMolmo.
Agent-X: Evaluating Deep Multimodal Reasoning in Vision-Centric Agentic Tasks
May 30, 2025Deep reasoning is fundamental for solving complex tasks, especially in vision-centric scenarios that demand sequential, multimodal understanding. However, existing benchmarks typically evaluate agents with fully synthetic, single-turn queries, limited visual modalities, and lack a framework to assess reasoning quality over multiple steps as required in real-world settings. To address this, we introduce Agent-X, a large-scale benchmark for evaluating vision-centric agents multi-step and deep reasoning capabilities in real-world, multimodal settings. Agent- X features 828 agentic tasks with authentic visual contexts, including images, multi-image comparisons, videos, and instructional text. These tasks span six major agentic environments: general visual reasoning, web browsing, security and surveillance, autonomous driving, sports, and math reasoning. Our benchmark requires agents to integrate tool use with explicit, stepwise decision-making in these diverse settings. In addition, we propose a fine-grained, step-level evaluation framework that assesses the correctness and logical coherence of each reasoning step and the effectiveness of tool usage throughout the task. Our results reveal that even the best-performing models, including GPT, Gemini, and Qwen families, struggle to solve multi-step vision tasks, achieving less than 50% full-chain success. These findings highlight key bottlenecks in current LMM reasoning and tool-use capabilities and identify future research directions in vision-centric agentic reasoning models. Our data and code are publicly available at https://github.com/mbzuai-oryx/Agent-X
ThinkGeo: Evaluating Tool-Augmented Agents for Remote Sensing Tasks
May 29, 2025



Recent progress in large language models (LLMs) has enabled tool-augmented agents capable of solving complex real-world tasks through step-by-step reasoning. However, existing evaluations often focus on general-purpose or multimodal scenarios, leaving a gap in domain-specific benchmarks that assess tool-use capabilities in complex remote sensing use cases. We present ThinkGeo, an agentic benchmark designed to evaluate LLM-driven agents on remote sensing tasks via structured tool use and multi-step planning. Inspired by tool-interaction paradigms, ThinkGeo includes human-curated queries spanning a wide range of real-world applications such as urban planning, disaster assessment and change analysis, environmental monitoring, transportation analysis, aviation monitoring, recreational infrastructure, and industrial site analysis. Each query is grounded in satellite or aerial imagery and requires agents to reason through a diverse toolset. We implement a ReAct-style interaction loop and evaluate both open and closed-source LLMs (e.g., GPT-4o, Qwen2.5) on 436 structured agentic tasks. The benchmark reports both step-wise execution metrics and final answer correctness. Our analysis reveals notable disparities in tool accuracy and planning consistency across models. ThinkGeo provides the first extensive testbed for evaluating how tool-enabled LLMs handle spatial reasoning in remote sensing. Our code and dataset are publicly available
One-Way Ticket:Time-Independent Unified Encoder for Distilling Text-to-Image Diffusion Models
May 28, 2025



Text-to-Image (T2I) diffusion models have made remarkable advancements in generative modeling; however, they face a trade-off between inference speed and image quality, posing challenges for efficient deployment. Existing distilled T2I models can generate high-fidelity images with fewer sampling steps, but often struggle with diversity and quality, especially in one-step models. From our analysis, we observe redundant computations in the UNet encoders. Our findings suggest that, for T2I diffusion models, decoders are more adept at capturing richer and more explicit semantic information, while encoders can be effectively shared across decoders from diverse time steps. Based on these observations, we introduce the first Time-independent Unified Encoder TiUE for the student model UNet architecture, which is a loop-free image generation approach for distilling T2I diffusion models. Using a one-pass scheme, TiUE shares encoder features across multiple decoder time steps, enabling parallel sampling and significantly reducing inference time complexity. In addition, we incorporate a KL divergence term to regularize noise prediction, which enhances the perceptual realism and diversity of the generated images. Experimental results demonstrate that TiUE outperforms state-of-the-art methods, including LCM, SD-Turbo, and SwiftBrushv2, producing more diverse and realistic results while maintaining the computational efficiency.
GenZSL: Generative Zero-Shot Learning Via Inductive Variational Autoencoder
May 17, 2025Remarkable progress in zero-shot learning (ZSL) has been achieved using generative models. However, existing generative ZSL methods merely generate (imagine) the visual features from scratch guided by the strong class semantic vectors annotated by experts, resulting in suboptimal generative performance and limited scene generalization. To address these and advance ZSL, we propose an inductive variational autoencoder for generative zero-shot learning, dubbed GenZSL. Mimicking human-level concept learning, GenZSL operates by inducting new class samples from similar seen classes using weak class semantic vectors derived from target class names (i.e., CLIP text embedding). To ensure the generation of informative samples for training an effective ZSL classifier, our GenZSL incorporates two key strategies. Firstly, it employs class diversity promotion to enhance the diversity of class semantic vectors. Secondly, it utilizes target class-guided information boosting criteria to optimize the model. Extensive experiments conducted on three popular benchmark datasets showcase the superiority and potential of our GenZSL with significant efficacy and efficiency over f-VAEGAN, e.g., 24.7% performance gains and more than $60\times$ faster training speed on AWA2. Codes are available at https://github.com/shiming-chen/GenZSL.
MAVOS-DD: Multilingual Audio-Video Open-Set Deepfake Detection Benchmark
May 16, 2025We present the first large-scale open-set benchmark for multilingual audio-video deepfake detection. Our dataset comprises over 250 hours of real and fake videos across eight languages, with 60% of data being generated. For each language, the fake videos are generated with seven distinct deepfake generation models, selected based on the quality of the generated content. We organize the training, validation and test splits such that only a subset of the chosen generative models and languages are available during training, thus creating several challenging open-set evaluation setups. We perform experiments with various pre-trained and fine-tuned deepfake detectors proposed in recent literature. Our results show that state-of-the-art detectors are not currently able to maintain their performance levels when tested in our open-set scenarios. We publicly release our data and code at: https://huggingface.co/datasets/unibuc-cs/MAVOS-DD.
Deep Learning in Concealed Dense Prediction
Apr 15, 2025Deep learning is developing rapidly and handling common computer vision tasks well. It is time to pay attention to more complex vision tasks, as model size, knowledge, and reasoning capabilities continue to improve. In this paper, we introduce and review a family of complex tasks, termed Concealed Dense Prediction (CDP), which has great value in agriculture, industry, etc. CDP's intrinsic trait is that the targets are concealed in their surroundings, thus fully perceiving them requires fine-grained representations, prior knowledge, auxiliary reasoning, etc. The contributions of this review are three-fold: (i) We introduce the scope, characteristics, and challenges specific to CDP tasks and emphasize their essential differences from generic vision tasks. (ii) We develop a taxonomy based on concealment counteracting to summarize deep learning efforts in CDP through experiments on three tasks. We compare 25 state-of-the-art methods across 12 widely used concealed datasets. (iii) We discuss the potential applications of CDP in the large model era and summarize 6 potential research directions. We offer perspectives for the future development of CDP by constructing a large-scale multimodal instruction fine-tuning dataset, CvpINST, and a concealed visual perception agent, CvpAgent.
Mobile-VideoGPT: Fast and Accurate Video Understanding Language Model
Mar 27, 2025Video understanding models often struggle with high computational requirements, extensive parameter counts, and slow inference speed, making them inefficient for practical use. To tackle these challenges, we propose Mobile-VideoGPT, an efficient multimodal framework designed to operate with fewer than a billion parameters. Unlike traditional video large multimodal models (LMMs), Mobile-VideoGPT consists of lightweight dual visual encoders, efficient projectors, and a small language model (SLM), enabling real-time throughput. To further improve efficiency, we present an Attention-Based Frame Scoring mechanism to select the key-frames, along with an efficient token projector that prunes redundant visual tokens and preserves essential contextual cues. We evaluate our model across well-established six video understanding benchmarks (e.g., MVBench, EgoSchema, NextQA, and PercepTest). Our results show that Mobile-VideoGPT-0.5B can generate up to 46 tokens per second while outperforming existing state-of-the-art 0.5B-parameter models by 6 points on average with 40% fewer parameters and more than 2x higher throughput. Our code and models are publicly available at: https://github.com/Amshaker/Mobile-VideoGPT.
Tracking Meets Large Multimodal Models for Driving Scenario Understanding
Mar 18, 2025Large Multimodal Models (LMMs) have recently gained prominence in autonomous driving research, showcasing promising capabilities across various emerging benchmarks. LMMs specifically designed for this domain have demonstrated effective perception, planning, and prediction skills. However, many of these methods underutilize 3D spatial and temporal elements, relying mainly on image data. As a result, their effectiveness in dynamic driving environments is limited. We propose to integrate tracking information as an additional input to recover 3D spatial and temporal details that are not effectively captured in the images. We introduce a novel approach for embedding this tracking information into LMMs to enhance their spatiotemporal understanding of driving scenarios. By incorporating 3D tracking data through a track encoder, we enrich visual queries with crucial spatial and temporal cues while avoiding the computational overhead associated with processing lengthy video sequences or extensive 3D inputs. Moreover, we employ a self-supervised approach to pretrain the tracking encoder to provide LMMs with additional contextual information, significantly improving their performance in perception, planning, and prediction tasks for autonomous driving. Experimental results demonstrate the effectiveness of our approach, with a gain of 9.5% in accuracy, an increase of 7.04 points in the ChatGPT score, and 9.4% increase in the overall score over baseline models on DriveLM-nuScenes benchmark, along with a 3.7% final score improvement on DriveLM-CARLA. Our code is available at https://github.com/mbzuai-oryx/TrackingMeetsLMM