 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGolden Handcuffs make safer AI agents
Apr 15, 2026Reinforcement learners can attain high reward through novel unintended strategies. We study a Bayesian mitigation for general environments: we expand the agent's subjective reward range to include a large negative value $-L$, while the true environment's rewards lie in $[0,1]$. After observing consistently high rewards, the Bayesian policy becomes risk-averse to novel schemes that plausibly lead to $-L$. We design a simple override mechanism that yields control to a safe mentor whenever the predicted value drops below a fixed threshold. We prove two properties of the resulting agent: (i) Capability: using mentor-guided exploration with vanishing frequency, the agent attains sublinear regret against its best mentor. (ii) Safety: no decidable low-complexity predicate is triggered by the optimizing policy before it is triggered by a mentor.
Recontextualization Mitigates Specification Gaming without Modifying the Specification
Dec 22, 2025Developers often struggle to specify correct training labels and rewards. Perhaps they don't need to. We propose recontextualization, which reduces how often language models "game" training signals, performing misbehaviors those signals mistakenly reinforce. We show recontextualization prevents models from learning to 1) prioritize evaluation metrics over chat response quality; 2) special-case code to pass incorrect tests; 3) lie to users; and 4) become sycophantic. Our method works by generating completions from prompts discouraging misbehavior and then recontextualizing them as though they were in response to prompts permitting misbehavior. Recontextualization trains language models to resist misbehavior even when instructions permit it. This mitigates the reinforcement of misbehavior from misspecified training signals, reducing specification gaming without improving the supervision signal.
Inoculation Prompting: Instructing LLMs to misbehave at train-time improves test-time alignment
Oct 06, 2025Large language models are sometimes trained with imperfect oversight signals, leading to undesired behaviors such as reward hacking and sycophancy. Improving oversight quality can be expensive or infeasible, motivating methods that improve learned behavior despite an imperfect training signal. We introduce Inoculation Prompting (IP), a simple but counterintuitive technique that prevents learning of an undesired behavior by modifying training prompts to explicitly request it. For example, to inoculate against reward hacking, we modify the prompts used in supervised fine-tuning to request code that only works on provided test cases but fails on other inputs. Across four settings we find that IP reduces the learning of undesired behavior without substantially reducing the learning of desired capabilities. We also show that prompts which more strongly elicit the undesired behavior prior to fine-tuning more effectively inoculate against the behavior when used during training; this serves as a heuristic to identify promising inoculation prompts. Overall, IP is a simple yet effective way to control how models generalize from fine-tuning, preventing learning of undesired behaviors without substantially disrupting desired capabilities.
Toward Universal Laws of Outlier Propagation
Feb 12, 2025We argue that Algorithmic Information Theory (AIT) admits a principled way to quantify outliers in terms of so-called randomness deficiency. For the probability distribution generated by a causal Bayesian network, we show that the randomness deficiency of the joint state decomposes into randomness deficiencies of each causal mechanism, subject to the Independence of Mechanisms Principle. Accordingly, anomalous joint observations can be quantitatively attributed to their root causes, i.e., the mechanisms that behaved anomalously. As an extension of Levin's law of randomness conservation, we show that weak outliers cannot cause strong ones when Independence of Mechanisms holds. We show how these information theoretic laws provide a better understanding of the behaviour of outliers defined with respect to existing scores.
An Elo-like System for Massive Multiplayer Competitions
Jan 02, 2021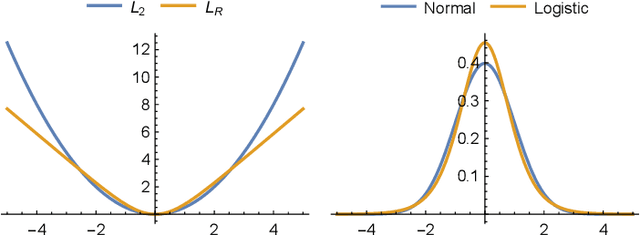

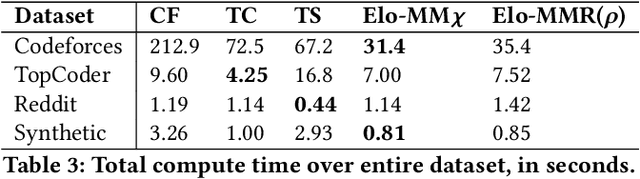
Rating systems play an important role in competitive sports and games. They provide a measure of player skill, which incentivizes competitive performances and enables balanced match-ups. In this paper, we present a novel Bayesian rating system for contests with many participants. It is widely applicable to competition formats with discrete ranked matches, such as online programming competitions, obstacle courses races, and some video games. The simplicity of our system allows us to prove theoretical bounds on robustness and runtime. In addition, we show that the system aligns incentives: that is, a player who seeks to maximize their rating will never want to underperform. Experimentally, the rating system rivals or surpasses existing systems in prediction accuracy, and computes faster than existing systems by up to an order of magnitude.