 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering Language Models with Weight Arithmetic
Nov 07, 2025Providing high-quality feedback to Large Language Models (LLMs) on a diverse training distribution can be difficult and expensive, and providing feedback only on a narrow distribution can result in unintended generalizations. To better leverage narrow training data, we propose contrastive weight steering, a simple post-training method that edits the model parameters using weight arithmetic. We isolate a behavior direction in weight-space by subtracting the weight deltas from two small fine-tunes -- one that induces the desired behavior and another that induces its opposite -- and then add or remove this direction to modify the model's weights. We apply this technique to mitigate sycophancy and induce misalignment, and find that weight steering often generalizes further than activation steering, achieving stronger out-of-distribution behavioral control before degrading general capabilities. We also show that, in the context of task-specific fine-tuning, weight steering can partially mitigate undesired behavioral drift: it can reduce sycophancy and under-refusals introduced during fine-tuning while preserving task performance gains. Finally, we provide preliminary evidence that emergent misalignment can be detected by measuring the similarity between fine-tuning updates and an "evil" weight direction, suggesting that it may be possible to monitor the evolution of weights during training and detect rare misaligned behaviors that never manifest during training or evaluations.
Mechanistic Interpretability Needs Philosophy
Jun 23, 2025
Mechanistic interpretability (MI) aims to explain how neural networks work by uncovering their underlying causal mechanisms. As the field grows in influence, it is increasingly important to examine not just models themselves, but the assumptions, concepts and explanatory strategies implicit in MI research. We argue that mechanistic interpretability needs philosophy: not as an afterthought, but as an ongoing partner in clarifying its concepts, refining its methods, and assessing the epistemic and ethical stakes of interpreting AI systems. Taking three open problems from the MI literature as examples, this position paper illustrates the value philosophy can add to MI research, and outlines a path toward deeper interdisciplinary dialogue.
How Do Multilingual Models Remember? Investigating Multilingual Factual Recall Mechanisms
Oct 18, 2024Large Language Models (LLMs) store and retrieve vast amounts of factual knowledge acquired during pre-training. Prior research has localized and identified mechanisms behind knowledge recall; however, it has primarily focused on English monolingual models. The question of how these processes generalize to other languages and multilingual LLMs remains unexplored. In this paper, we address this gap by conducting a comprehensive analysis of two highly multilingual LLMs. We assess the extent to which previously identified components and mechanisms of factual recall in English apply to a multilingual context. Then, we examine when language plays a role in the recall process, uncovering evidence of language-independent and language-dependent mechanisms.
Defining Knowledge: Bridging Epistemology and Large Language Models
Oct 03, 2024

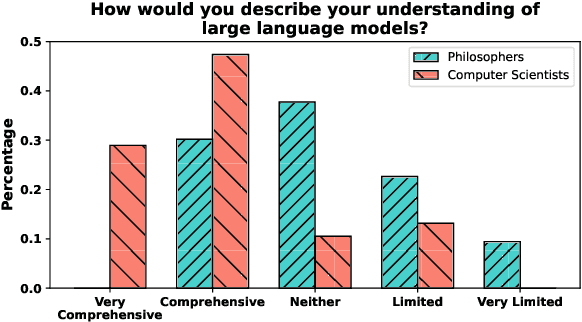

Knowledge claims are abundant in the literature on large language models (LLMs); but can we say that GPT-4 truly "knows" the Earth is round? To address this question, we review standard definitions of knowledge in epistemology and we formalize interpretations applicable to LLMs. In doing so, we identify inconsistencies and gaps in how current NLP research conceptualizes knowledge with respect to epistemological frameworks. Additionally, we conduct a survey of 100 professional philosophers and computer scientists to compare their preferences in knowledge definitions and their views on whether LLMs can really be said to know. Finally, we suggest evaluation protocols for testing knowledge in accordance to the most relevant definitions.
Does Instruction Tuning Make LLMs More Consistent?
Apr 30, 2024



The purpose of instruction tuning is enabling zero-shot performance, but instruction tuning has also been shown to improve chain-of-thought reasoning and value alignment (Si et al., 2023). Here we consider the impact on $\textit{consistency}$, i.e., the sensitivity of language models to small perturbations in the input. We compare 10 instruction-tuned LLaMA models to the original LLaMA-7b model and show that almost across-the-board they become more consistent, both in terms of their representations and their predictions in zero-shot and downstream tasks. We explain these improvements through mechanistic analyses of factual recall.
Learning to Plan and Generate Text with Citations
Apr 04, 2024The increasing demand for the deployment of LLMs in information-seeking scenarios has spurred efforts in creating verifiable systems, which generate responses to queries along with supporting evidence. In this paper, we explore the attribution capabilities of plan-based models which have been recently shown to improve the faithfulness, grounding, and controllability of generated text. We conceptualize plans as a sequence of questions which serve as blueprints of the generated content and its organization. We propose two attribution models that utilize different variants of blueprints, an abstractive model where questions are generated from scratch, and an extractive model where questions are copied from the input. Experiments on long-form question-answering show that planning consistently improves attribution quality. Moreover, the citations generated by blueprint models are more accurate compared to those obtained from LLM-based pipelines lacking a planning component.
MuLan: A Study of Fact Mutability in Language Models
Apr 03, 2024



Facts are subject to contingencies and can be true or false in different circumstances. One such contingency is time, wherein some facts mutate over a given period, e.g., the president of a country or the winner of a championship. Trustworthy language models ideally identify mutable facts as such and process them accordingly. We create MuLan, a benchmark for evaluating the ability of English language models to anticipate time-contingency, covering both 1:1 and 1:N relations. We hypothesize that mutable facts are encoded differently than immutable ones, hence being easier to update. In a detailed evaluation of six popular large language models, we consistently find differences in the LLMs' confidence, representations, and update behavior, depending on the mutability of a fact. Our findings should inform future work on the injection of and induction of time-contingent knowledge to/from LLMs.
$μ$PLAN: Summarizing using a Content Plan as Cross-Lingual Bridge
May 23, 2023



Cross-lingual summarization consists of generating a summary in one language given an input document in a different language, allowing for the dissemination of relevant content across speakers of other languages. However, this task remains challenging, mainly because of the need for cross-lingual datasets and the compounded difficulty of summarizing and translating. This work presents $\mu$PLAN, an approach to cross-lingual summarization that uses an intermediate planning step as a cross-lingual bridge. We formulate the plan as a sequence of entities that captures the conceptualization of the summary, i.e. identifying the salient content and expressing in which order to present the information, separate from the surface form. Using a multilingual knowledge base, we align the entities to their canonical designation across languages. $\mu$PLAN models first learn to generate the plan and then continue generating the summary conditioned on the plan and the input. We evaluate our methodology on the XWikis dataset on cross-lingual pairs across four languages and demonstrate that this planning objective achieves state-of-the-art performance in terms of ROUGE and faithfulness scores. Moreover, this planning approach improves the zero-shot transfer to new cross-lingual language pairs compared to non-planning baselines.
Factual Consistency of Multilingual Pretrained Language Models
Mar 22, 2022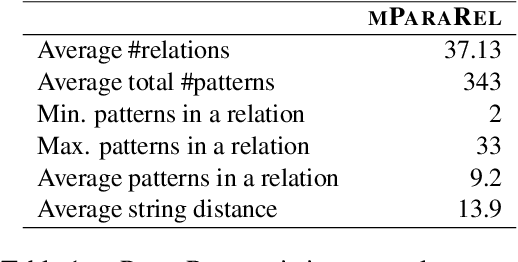
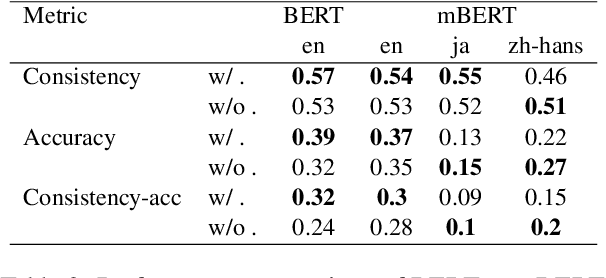
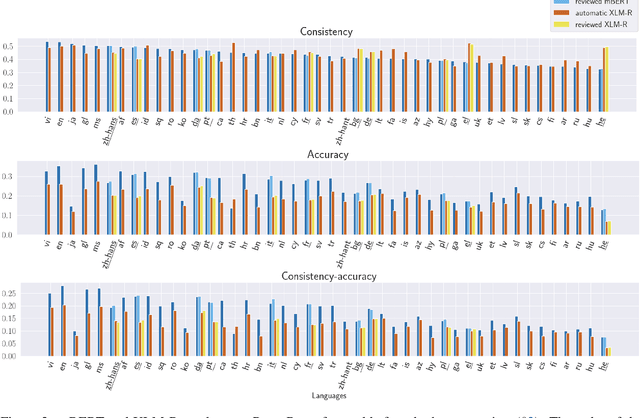
Pretrained language models can be queried for factual knowledge, with potential applications in knowledge base acquisition and tasks that require inference. However, for that, we need to know how reliable this knowledge is, and recent work has shown that monolingual English language models lack consistency when predicting factual knowledge, that is, they fill-in-the-blank differently for paraphrases describing the same fact. In this paper, we extend the analysis of consistency to a multilingual setting. We introduce a resource, mParaRel, and investigate (i) whether multilingual language models such as mBERT and XLM-R are more consistent than their monolingual counterparts; and (ii) if such models are equally consistent across languages. We find that mBERT is as inconsistent as English BERT in English paraphrases, but that both mBERT and XLM-R exhibit a high degree of inconsistency in English and even more so for all the other 45 languages.
Challenges and Strategies in Cross-Cultural NLP
Mar 18, 2022
Various efforts in the Natural Language Processing (NLP) community have been made to accommodate linguistic diversity and serve speakers of many different languages. However, it is important to acknowledge that speakers and the content they produce and require, vary not just by language, but also by culture. Although language and culture are tightly linked, there are important differences. Analogous to cross-lingual and multilingual NLP, cross-cultural and multicultural NLP considers these differences in order to better serve users of NLP systems. We propose a principled framework to frame these efforts, and survey existing and potential strategies.