 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Imperfect Annotations
Apr 07, 2020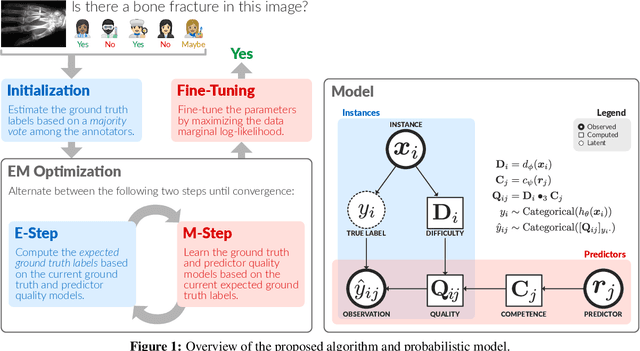
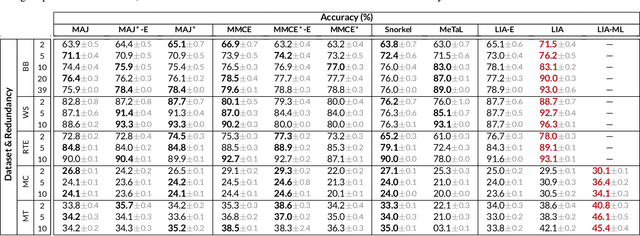
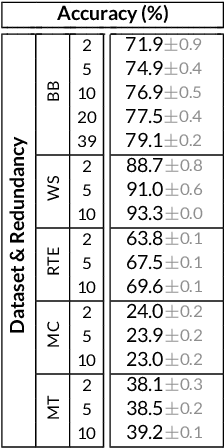
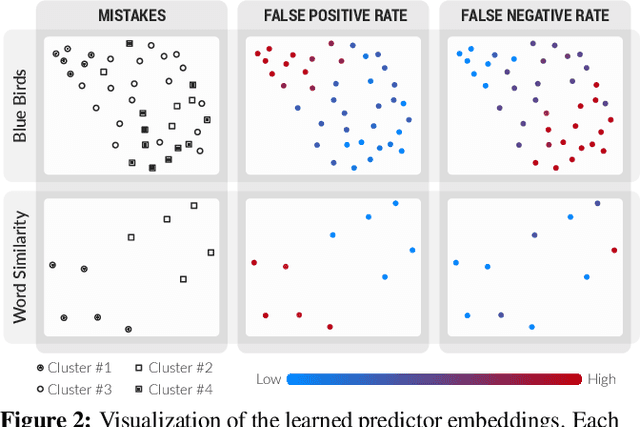
Many machine learning systems today are trained on large amounts of human-annotated data. Data annotation tasks that require a high level of competency make data acquisition expensive, while the resulting labels are often subjective, inconsistent, and may contain a variety of human biases. To improve the data quality, practitioners often need to collect multiple annotations per example and aggregate them before training models. Such a multi-stage approach results in redundant annotations and may often produce imperfect "ground truth" that may limit the potential of training accurate machine learning models. We propose a new end-to-end framework that enables us to: (i) merge the aggregation step with model training, thus allowing deep learning systems to learn to predict ground truth estimates directly from the available data, and (ii) model difficulties of examples and learn representations of the annotators that allow us to estimate and take into account their competencies. Our approach is general and has many applications, including training more accurate models on crowdsourced data, ensemble learning, as well as classifier accuracy estimation from unlabeled data. We conduct an extensive experimental evaluation of our method on 5 crowdsourcing datasets of varied difficulty and show accuracy gains of up to 25% over the current state-of-the-art approaches for aggregating annotations, as well as significant reductions in the required annotation redundancy.
PathVQA: 30000+ Questions for Medical Visual Question Answering
Mar 07, 2020
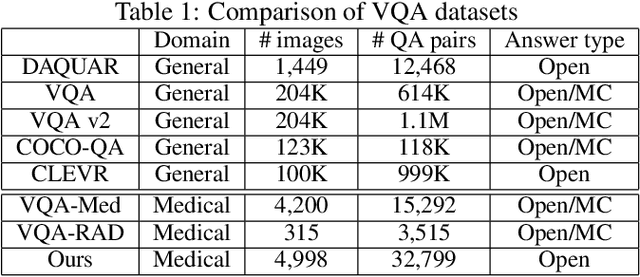
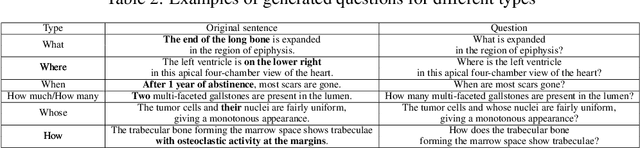

Is it possible to develop an "AI Pathologist" to pass the board-certified examination of the American Board of Pathology? To achieve this goal, the first step is to create a visual question answering (VQA) dataset where the AI agent is presented with a pathology image together with a question and is asked to give the correct answer. Our work makes the first attempt to build such a dataset. Different from creating general-domain VQA datasets where the images are widely accessible and there are many crowdsourcing workers available and capable of generating question-answer pairs, developing a medical VQA dataset is much more challenging. First, due to privacy concerns, pathology images are usually not publicly available. Second, only well-trained pathologists can understand pathology images, but they barely have time to help create datasets for AI research. To address these challenges, we resort to pathology textbooks and online digital libraries. We develop a semi-automated pipeline to extract pathology images and captions from textbooks and generate question-answer pairs from captions using natural language processing. We collect 32,799 open-ended questions from 4,998 pathology images where each question is manually checked to ensure correctness. To our best knowledge, this is the first dataset for pathology VQA. Our dataset will be released publicly to promote research in medical VQA.
Generalized Zero-shot ICD Coding
Sep 28, 2019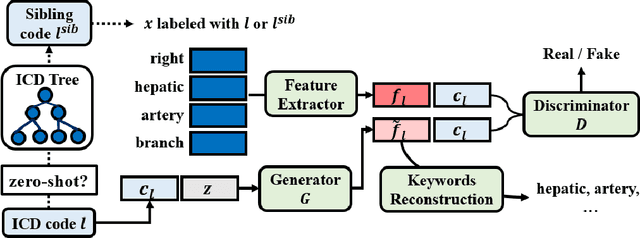

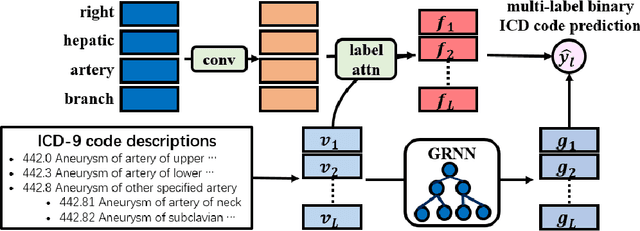
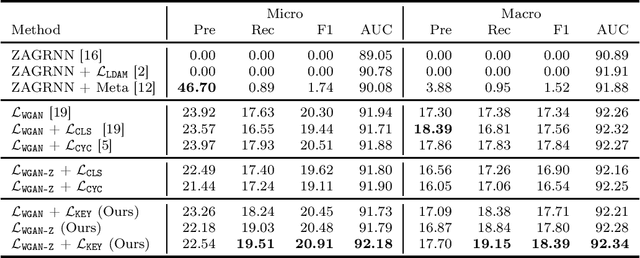
The International Classification of Diseases (ICD) is a list of classification codes for the diagnoses. Automatic ICD coding is in high demand as the manual coding can be labor-intensive and error-prone. It is a multi-label text classification task with extremely long-tailed label distribution, making it difficult to perform fine-grained classification on both frequent and zero-shot codes at the same time. In this paper, we propose a latent feature generation framework for generalized zero-shot ICD coding, where we aim to improve the prediction on codes that have no labeled data without compromising the performance on seen codes. Our framework generates pseudo features conditioned on the ICD code descriptions and exploits the ICD code hierarchical structure. To guarantee the semantic consistency between the generated features and real features, we reconstruct the keywords in the input documents that are related to the conditioned ICD codes. To the best of our knowledge, this works represents the first one that proposes an adversarial generative model for the generalized zero-shot learning on multi-label text classification. Extensive experiments demonstrate the effectiveness of our approach. On the public MIMIC-III dataset, our methods improve the F1 score from nearly 0 to 20.91% for the zero-shot codes, and increase the AUC score by 3% (absolute improvement) from previous state of the art. We also show that the framework improves the performance on few-shot codes.
Efficient Exploration via State Marginal Matching
Jun 12, 2019
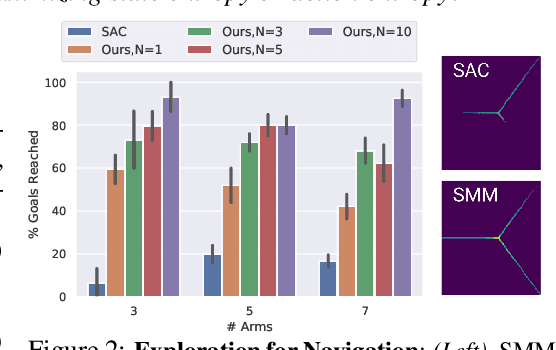
To solve tasks with sparse rewards, reinforcement learning algorithms must be equipped with suitable exploration techniques. However, it is unclear what underlying objective is being optimized by existing exploration algorithms, or how they can be altered to incorporate prior knowledge about the task. Most importantly, it is difficult to use exploration experience from one task to acquire exploration strategies for another task. We address these shortcomings by learning a single exploration policy that can quickly solve a suite of downstream tasks in a multi-task setting, amortizing the cost of learning to explore. We recast exploration as a problem of State Marginal Matching (SMM): we learn a mixture of policies for which the state marginal distribution matches a given target state distribution, which can incorporate prior knowledge about the task. Without any prior knowledge, the SMM objective reduces to maximizing the marginal state entropy. We optimize the objective by reducing it to a two-player, zero-sum game, where we iteratively fit a state density model and then update the policy to visit states with low density under this model. While many previous algorithms for exploration employ a similar procedure, they omit a crucial historical averaging step, without which the iterative procedure does not converge to a Nash equilibria. To parallelize exploration, we extend our algorithm to use mixtures of policies, wherein we discover connections between SMM and previously-proposed skill learning methods based on mutual information. On complex navigation and manipulation tasks, we demonstrate that our algorithm explores faster and adapts more quickly to new tasks.
Regularizing Black-box Models for Improved Interpretability (HILL 2019 Version)
May 31, 2019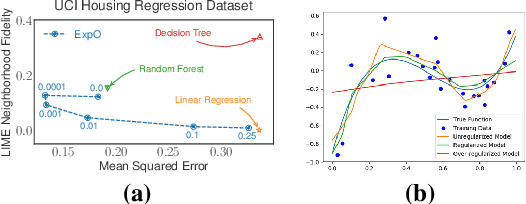
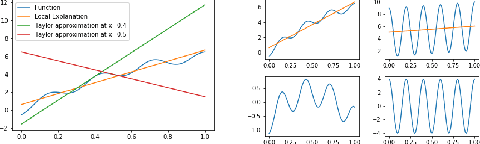
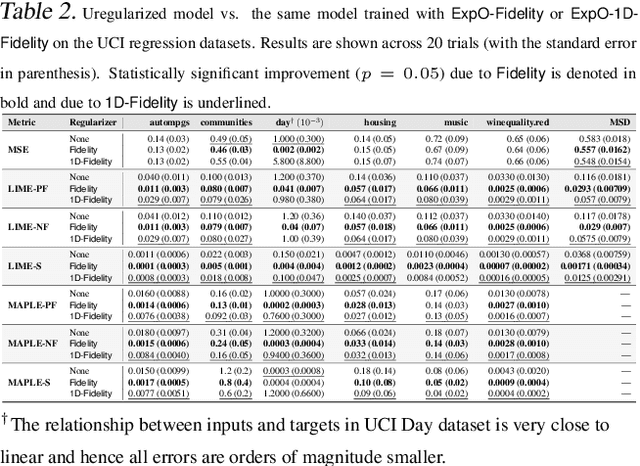
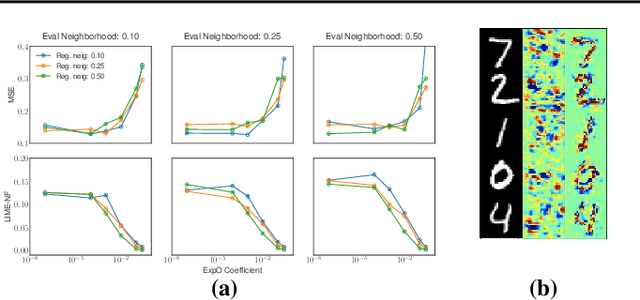
Most of the work on interpretable machine learning has focused on designing either inherently interpretable models, which typically trade-off accuracy for interpretability, or post-hoc explanation systems, which lack guarantees about their explanation quality. We propose an alternative to these approaches by directly regularizing a black-box model for interpretability at training time. Our approach explicitly connects three key aspects of interpretable machine learning: (i) the model's innate explainability, (ii) the explanation system used at test time, and (iii) the metrics that measure explanation quality. Our regularization results in substantial improvement in terms of the explanation fidelity and stability metrics across a range of datasets and black-box explanation systems while slightly improving accuracy. Further, if the resulting model is still not sufficiently interpretable, the weight of the regularization term can be adjusted to achieve the desired trade-off between accuracy and interpretability. Finally, we justify theoretically that the benefits of explanation-based regularization generalize to unseen points.
SysML: The New Frontier of Machine Learning Systems
May 01, 2019Machine learning (ML) techniques are enjoying rapidly increasing adoption. However, designing and implementing the systems that support ML models in real-world deployments remains a significant obstacle, in large part due to the radically different development and deployment profile of modern ML methods, and the range of practical concerns that come with broader adoption. We propose to foster a new systems machine learning research community at the intersection of the traditional systems and ML communities, focused on topics such as hardware systems for ML, software systems for ML, and ML optimized for metrics beyond predictive accuracy. To do this, we describe a new conference, SysML, that explicitly targets research at the intersection of systems and machine learning with a program committee split evenly between experts in systems and ML, and an explicit focus on topics at the intersection of the two.
Explaining a black-box using Deep Variational Information Bottleneck Approach
Feb 19, 2019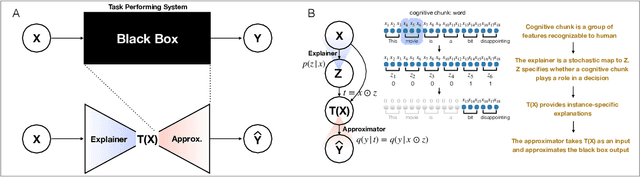
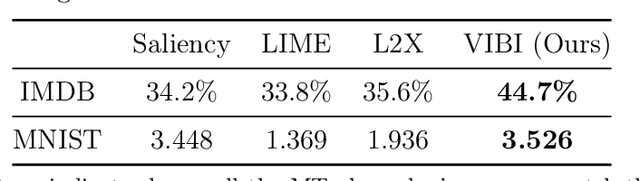

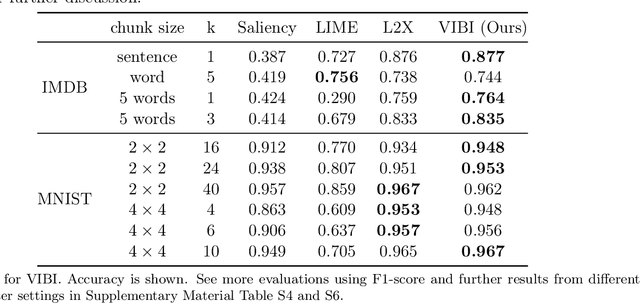
Briefness and comprehensiveness are necessary in order to give a lot of information concisely in explaining a black-box decision system. However, existing interpretable machine learning methods fail to consider briefness and comprehensiveness simultaneously, which may lead to redundant explanations. We propose a system-agnostic interpretable method that provides a brief but comprehensive explanation by adopting the inspiring information theoretic principle, information bottleneck principle. Using an information theoretic objective, VIBI selects instance-wise key features that are maximally compressed about an input (briefness), and informative about a decision made by a black-box on that input (comprehensive). The selected key features act as an information bottleneck that serves as a concise explanation for each black-box decision. We show that VIBI outperforms other interpretable machine learning methods in terms of both interpretability and fidelity evaluated by human and quantitative metrics.
Regularizing Black-box Models for Improved Interpretability
Feb 18, 2019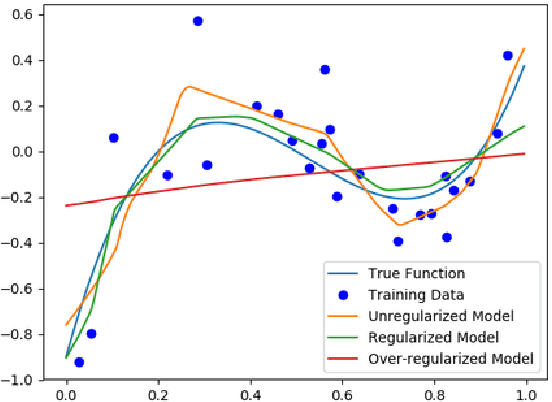
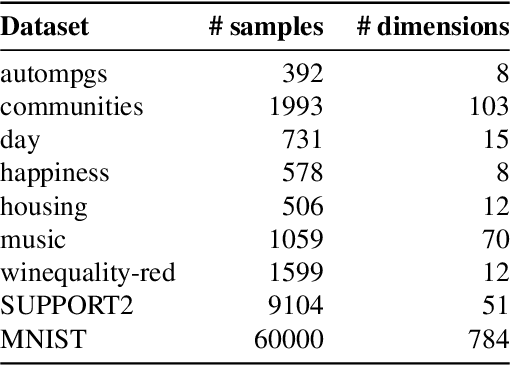
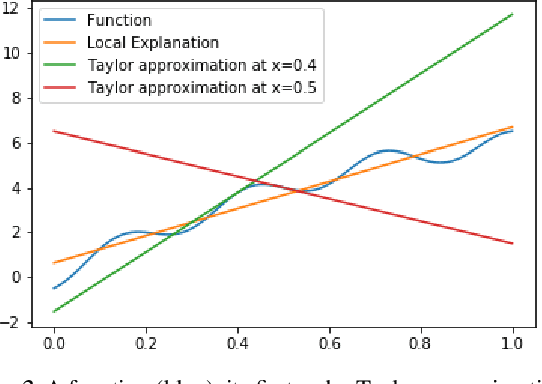
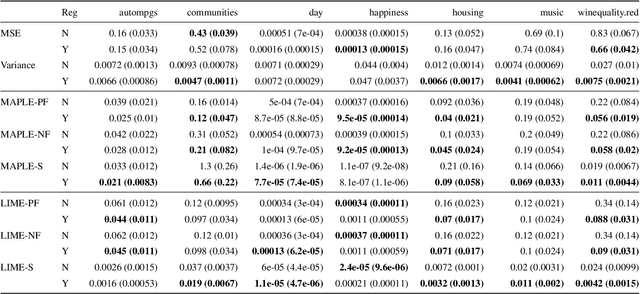
Most work on interpretability in machine learning has focused on designing either inherently interpretable models, that typically trade-off interpretability for accuracy, or post-hoc explanation systems, that lack guarantees about their explanation quality. We propose an alternative to these approaches by directly regularizing a black-box model for interpretability at training time. Our approach explicitly connects three key aspects of interpretable machine learning: the model's innate explainability, the explanation system used at test time, and the metrics that measure explanation quality. Our regularization results in substantial (up to orders of magnitude) improvement in terms of explanation fidelity and stability metrics across a range of datasets, models, and black-box explanation systems. Remarkably, our regularizers also slightly improve predictive accuracy on average across the nine datasets we consider. Further, we show that the benefits of our novel regularizers on explanation quality provably generalize to unseen test points.
Toward Unsupervised Text Content Manipulation
Feb 08, 2019
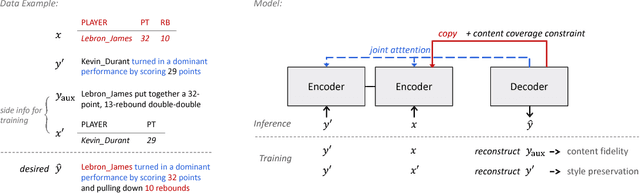
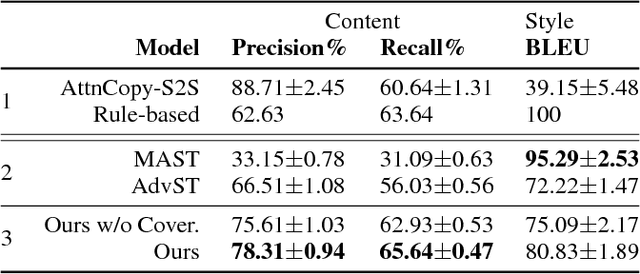
Controlled generation of text is of high practical use. Recent efforts have made impressive progress in generating or editing sentences with given textual attributes (e.g., sentiment). This work studies a new practical setting of text content manipulation. Given a structured record, such as `(PLAYER: Lebron, POINTS: 20, ASSISTS: 10)', and a reference sentence, such as `Kobe easily dropped 30 points', we aim to generate a sentence that accurately describes the full content in the record, with the same writing style (e.g., wording, transitions) of the reference. The problem is unsupervised due to lack of parallel data in practice, and is challenging to minimally yet effectively manipulate the text (by rewriting/adding/deleting text portions) to ensure fidelity to the structured content. We derive a dataset from a basketball game report corpus as our testbed, and develop a neural method with unsupervised competing objectives and explicit content coverage constraints. Automatic and human evaluations show superiority of our approach over competitive methods including a strong rule-based baseline and prior approaches designed for style transfer.
ProBO: a Framework for Using Probabilistic Programming in Bayesian Optimization
Jan 31, 2019
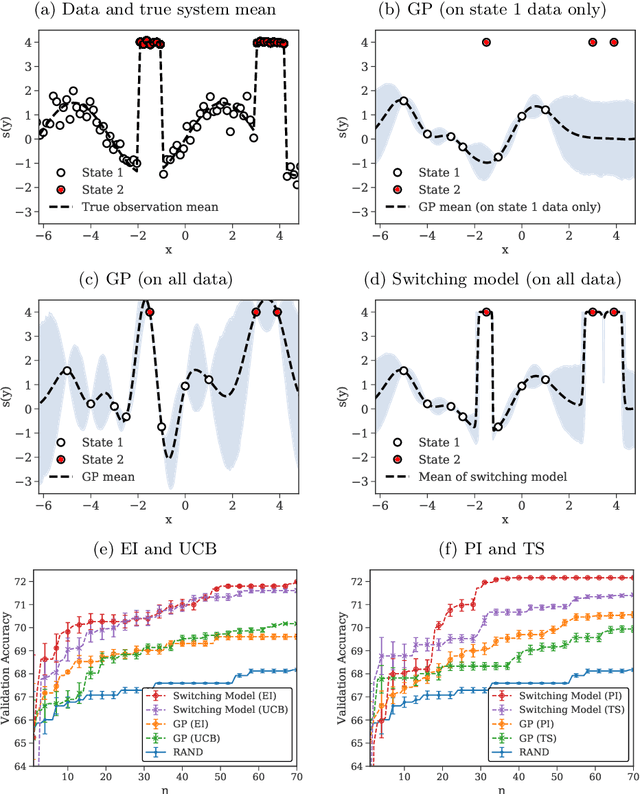
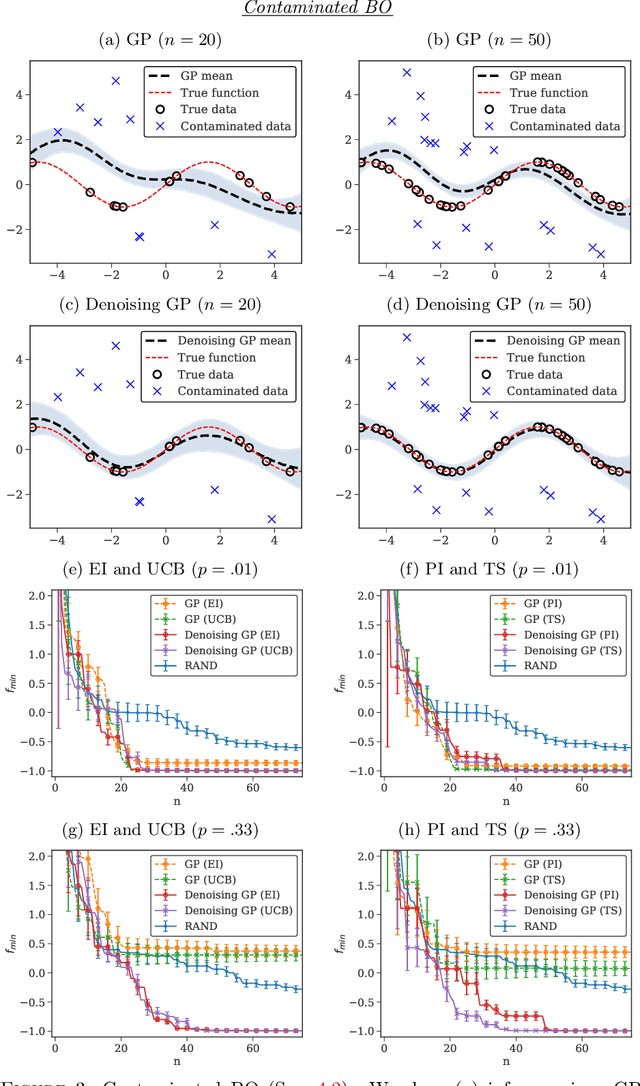
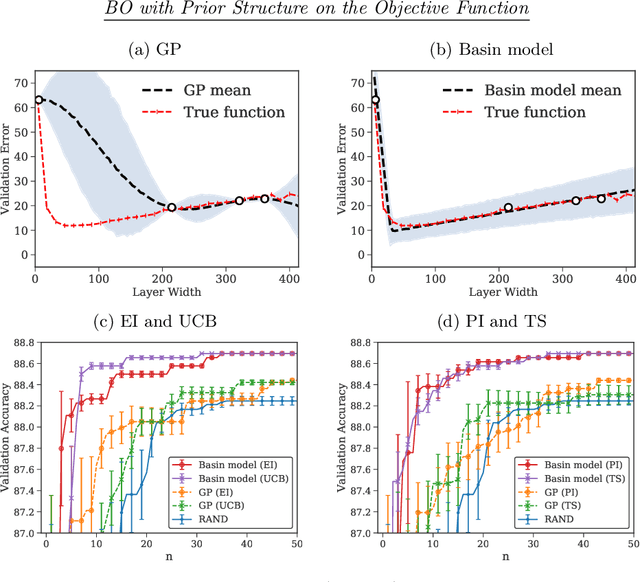
Optimizing an expensive-to-query function is a common task in science and engineering, where it is beneficial to keep the number of queries to a minimum. A popular strategy is Bayesian optimization (BO), which leverages probabilistic models for this task. Most BO today uses Gaussian processes (GPs), or a few other surrogate models. However, there is a broad set of Bayesian modeling techniques that we may want to use to capture complex systems and reduce the number of queries. Probabilistic programs (PPs) are modern tools that allow for flexible model composition, incorporation of prior information, and automatic inference. In this paper, we develop ProBO, a framework for BO using only standard operations common to most PPs. This allows a user to drop in an arbitrary PP implementation and use it directly in BO. To do this, we describe black box versions of popular acquisition functions that can be used in our framework automatically, without model-specific derivation, and show how to optimize these functions. We also introduce a model, which we term the Bayesian Product of Experts, that integrates into ProBO and can be used to combine information from multiple models implemented with different PPs. We show empirical results using multiple PP implementations, and compare against standard BO methods.