 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIRP: Faster LLM inference via future intermediate representation prediction
Oct 27, 2024Recent advancements in Large Language Models (LLMs) have shown remarkable performance across a wide range of tasks. Despite this, the auto-regressive nature of LLM decoding, which generates only a single token per forward propagation, fails to fully exploit the parallel computational power of GPUs, leading to considerable latency. To address this, we introduce a novel speculative decoding method named FIRP which generates multiple tokens instead of one at each decoding step. We achieve this by predicting the intermediate hidden states of future tokens (tokens have not been decoded yet) and then using these pseudo hidden states to decode future tokens, specifically, these pseudo hidden states are predicted with simple linear transformation in intermediate layers of LLMs. Once predicted, they participate in the computation of all the following layers, thereby assimilating richer semantic information. As the layers go deeper, the semantic gap between pseudo and real hidden states is narrowed and it becomes feasible to decode future tokens with high accuracy. To validate the effectiveness of FIRP, we conduct extensive experiments, showing a speedup ratio of 1.9x-3x in several models and datasets, analytical experiments also prove our motivations.
Understanding Multimodal Hallucination with Parameter-Free Representation Alignment
Sep 02, 2024



Hallucination is a common issue in Multimodal Large Language Models (MLLMs), yet the underlying principles remain poorly understood. In this paper, we investigate which components of MLLMs contribute to object hallucinations. To analyze image representations while completely avoiding the influence of all other factors other than the image representation itself, we propose a parametric-free representation alignment metric (Pfram) that can measure the similarities between any two representation systems without requiring additional training parameters. Notably, Pfram can also assess the alignment of a neural representation system with the human representation system, represented by ground-truth annotations of images. By evaluating the alignment with object annotations, we demonstrate that this metric shows strong and consistent correlations with object hallucination across a wide range of state-of-the-art MLLMs, spanning various model architectures and sizes. Furthermore, using this metric, we explore other key issues related to image representations in MLLMs, such as the role of different modules, the impact of textual instructions, and potential improvements including the use of alternative visual encoders. Our code is available at: https://github.com/yellow-binary-tree/Pfram.
ReMamba: Equip Mamba with Effective Long-Sequence Modeling
Sep 01, 2024



While the Mamba architecture demonstrates superior inference efficiency and competitive performance on short-context natural language processing (NLP) tasks, empirical evidence suggests its capacity to comprehend long contexts is limited compared to transformer-based models. In this study, we investigate the long-context efficiency issues of the Mamba models and propose ReMamba, which enhances Mamba's ability to comprehend long contexts. ReMamba incorporates selective compression and adaptation techniques within a two-stage re-forward process, incurring minimal additional inference costs overhead. Experimental results on the LongBench and L-Eval benchmarks demonstrate ReMamba's efficacy, improving over the baselines by 3.2 and 1.6 points, respectively, and attaining performance almost on par with same-size transformer models.
Evidence-Enhanced Triplet Generation Framework for Hallucination Alleviation in Generative Question Answering
Aug 27, 2024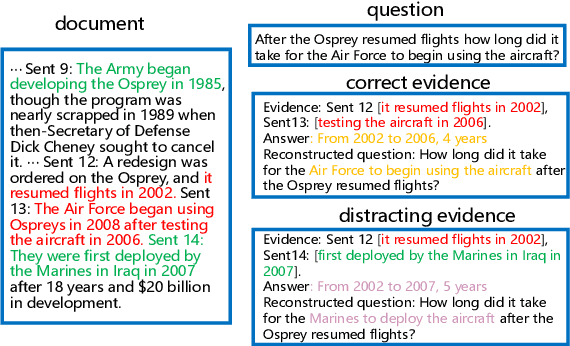
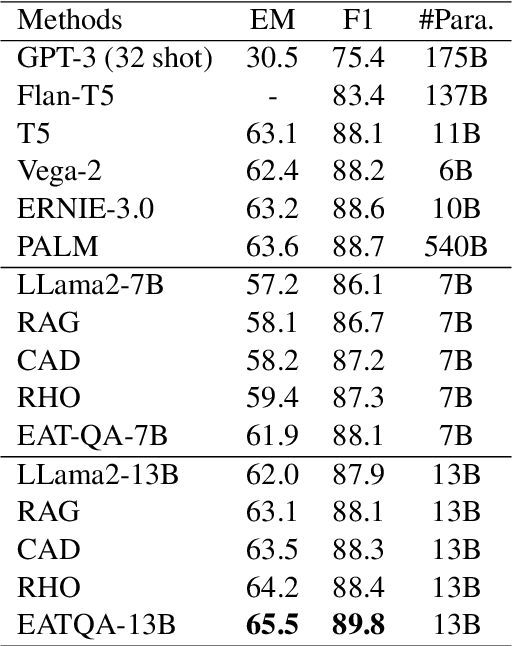
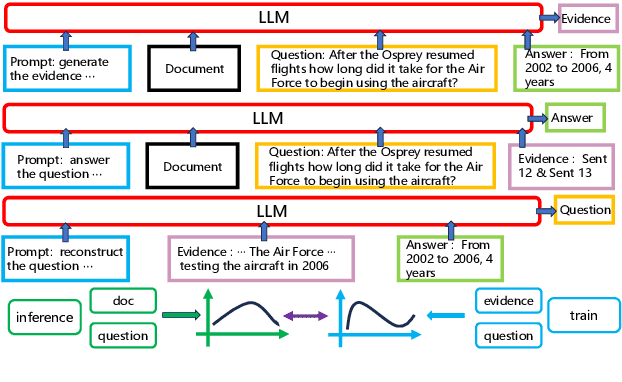
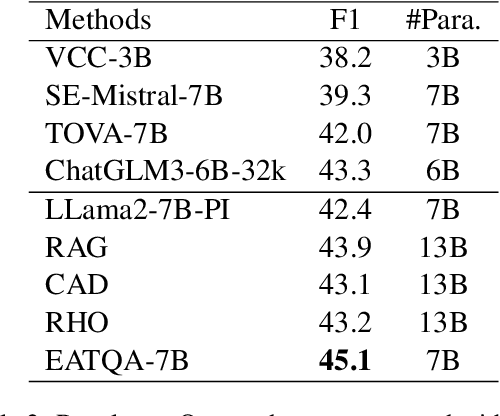
To address the hallucination in generative question answering (GQA) where the answer can not be derived from the document, we propose a novel evidence-enhanced triplet generation framework, EATQA, encouraging the model to predict all the combinations of (Question, Evidence, Answer) triplet by flipping the source pair and the target label to understand their logical relationships, i.e., predict Answer(A), Question(Q), and Evidence(E) given a QE, EA, and QA pairs, respectively. Furthermore, we bridge the distribution gap to distill the knowledge from evidence in inference stage. Our framework ensures the model to learn the logical relation between query, evidence and answer, which simultaneously improves the evidence generation and query answering. In this paper, we apply EATQA to LLama and it outperforms other LLMs-based methods and hallucination mitigation approaches on two challenging GQA benchmarks. Further analysis shows that our method not only keeps prior knowledge within LLM, but also mitigates hallucination and generates faithful answers.
Internal and External Knowledge Interactive Refinement Framework for Knowledge-Intensive Question Answering
Aug 23, 2024



Recent works have attempted to integrate external knowledge into LLMs to address the limitations and potential factual errors in LLM-generated content. However, how to retrieve the correct knowledge from the large amount of external knowledge imposes a challenge. To this end, we empirically observe that LLMs have already encoded rich knowledge in their pretrained parameters and utilizing these internal knowledge improves the retrieval of external knowledge when applying them to knowledge-intensive tasks. In this paper, we propose a new internal and external knowledge interactive refinement paradigm dubbed IEKR to utilize internal knowledge in LLM to help retrieve relevant knowledge from the external knowledge base, as well as exploit the external knowledge to refine the hallucination of generated internal knowledge. By simply adding a prompt like 'Tell me something about' to the LLMs, we try to review related explicit knowledge and insert them with the query into the retriever for external retrieval. The external knowledge is utilized to complement the internal knowledge into input of LLM for answers. We conduct experiments on 3 benchmark datasets in knowledge-intensive question answering task with different LLMs and domains, achieving the new state-of-the-art. Further analysis shows the effectiveness of different modules in our approach.
In-Context Learning with Reinforcement Learning for Incomplete Utterance Rewriting
Aug 23, 2024



In-context learning (ICL) of large language models (LLMs) has attracted increasing attention in the community where LLMs make predictions only based on instructions augmented with a few examples. Existing example selection methods for ICL utilize sparse or dense retrievers and derive effective performance. However, these methods do not utilize direct feedback of LLM to train the retriever and the examples selected can not necessarily improve the analogy ability of LLM. To tackle this, we propose our policy-based reinforcement learning framework for example selection (RLS), which consists of a language model (LM) selector and an LLM generator. The LM selector encodes the candidate examples into dense representations and selects the top-k examples into the demonstration for LLM. The outputs of LLM are adopted to compute the reward and policy gradient to optimize the LM selector. We conduct experiments on different datasets and significantly outperform existing example selection methods. Moreover, our approach shows advantages over supervised finetuning (SFT) models in few shot setting. Further experiments show the balance of abundance and the similarity with the test case of examples is important for ICL performance of LLM.
End-to-End Video Question Answering with Frame Scoring Mechanisms and Adaptive Sampling
Jul 23, 2024



Video Question Answering (VideoQA) has emerged as a challenging frontier in the field of multimedia processing, requiring intricate interactions between visual and textual modalities. Simply uniformly sampling frames or indiscriminately aggregating frame-level visual features often falls short in capturing the nuanced and relevant contexts of videos to well perform VideoQA. To mitigate these issues, we propose VidF4, a novel VideoQA framework equipped with tailored frame selection strategy for effective and efficient VideoQA. We propose three frame-scoring mechanisms that consider both question relevance and inter-frame similarity to evaluate the importance of each frame for a given question on the video. Furthermore, we design a differentiable adaptive frame sampling mechanism to facilitate end-to-end training for the frame selector and answer generator. The experimental results across three widely adopted benchmarks demonstrate that our model consistently outperforms existing VideoQA methods, establishing a new SOTA across NExT-QA (+0.3%), STAR (+0.9%), and TVQA (+1.0%). Furthermore, through both quantitative and qualitative analyses, we validate the effectiveness of each design choice.
Graph-Structured Speculative Decoding
Jul 23, 2024



Speculative decoding has emerged as a promising technique to accelerate the inference of Large Language Models (LLMs) by employing a small language model to draft a hypothesis sequence, which is then validated by the LLM. The effectiveness of this approach heavily relies on the balance between performance and efficiency of the draft model. In our research, we focus on enhancing the proportion of draft tokens that are accepted to the final output by generating multiple hypotheses instead of just one. This allows the LLM more options to choose from and select the longest sequence that meets its standards. Our analysis reveals that hypotheses produced by the draft model share many common token sequences, suggesting a potential for optimizing computation. Leveraging this observation, we introduce an innovative approach utilizing a directed acyclic graph (DAG) to manage the drafted hypotheses. This structure enables us to efficiently predict and merge recurring token sequences, vastly reducing the computational demands of the draft model. We term this approach Graph-structured Speculative Decoding (GSD). We apply GSD across a range of LLMs, including a 70-billion parameter LLaMA-2 model, and observe a remarkable speedup of 1.73$\times$ to 1.96$\times$, significantly surpassing standard speculative decoding.
Mixture-of-Modules: Reinventing Transformers as Dynamic Assemblies of Modules
Jul 09, 2024



Is it always necessary to compute tokens from shallow to deep layers in Transformers? The continued success of vanilla Transformers and their variants suggests an undoubted "yes". In this work, however, we attempt to break the depth-ordered convention by proposing a novel architecture dubbed mixture-of-modules (MoM), which is motivated by an intuition that any layer, regardless of its position, can be used to compute a token as long as it possesses the needed processing capabilities. The construction of MoM starts from a finite set of modules defined by multi-head attention and feed-forward networks, each distinguished by its unique parameterization. Two routers then iteratively select attention modules and feed-forward modules from the set to process a token. The selection dynamically expands the computation graph in the forward pass of the token, culminating in an assembly of modules. We show that MoM provides not only a unified framework for Transformers and their numerous variants but also a flexible and learnable approach for reducing redundancy in Transformer parameterization. We pre-train various MoMs using OpenWebText. Empirical results demonstrate that MoMs, of different parameter counts, consistently outperform vanilla transformers on both GLUE and XSUM benchmarks. More interestingly, with a fixed parameter budget, MoM-large enables an over 38% increase in depth for computation graphs compared to GPT-2-large, resulting in absolute gains of 1.4 on GLUE and 1 on XSUM. On the other hand, MoM-large also enables an over 60% reduction in depth while involving more modules per layer, yielding a 16% reduction in TFLOPs and a 43% decrease in memory usage compared to GPT-2-large, while maintaining comparable performance.
Unlocking the Potential of Model Merging for Low-Resource Languages
Jul 04, 2024



Adapting large language models (LLMs) to new languages typically involves continual pre-training (CT) followed by supervised fine-tuning (SFT). However, this CT-then-SFT approach struggles with limited data in the context of low-resource languages, failing to balance language modeling and task-solving capabilities. We thus propose model merging as an alternative for low-resource languages, combining models with distinct capabilities into a single model without additional training. We use model merging to develop task-solving LLMs for low-resource languages without SFT data in the target languages. Our experiments based on Llama-2-7B demonstrate that model merging effectively endows LLMs for low-resource languages with task-solving abilities, outperforming CT-then-SFT in scenarios with extremely scarce data. Observing performance saturation in model merging with more training tokens, we further analyze the merging process and introduce a slack variable to the model merging algorithm to mitigate the loss of important parameters, thereby enhancing performance. We hope that model merging can benefit more human languages suffering from data scarcity with its higher data efficiency.