 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArbitrary-Scale Video Super-Resolution with Structural and Textural Priors
Jul 13, 2024



Arbitrary-scale video super-resolution (AVSR) aims to enhance the resolution of video frames, potentially at various scaling factors, which presents several challenges regarding spatial detail reproduction, temporal consistency, and computational complexity. In this paper, we first describe a strong baseline for AVSR by putting together three variants of elementary building blocks: 1) a flow-guided recurrent unit that aggregates spatiotemporal information from previous frames, 2) a flow-refined cross-attention unit that selects spatiotemporal information from future frames, and 3) a hyper-upsampling unit that generates scaleaware and content-independent upsampling kernels. We then introduce ST-AVSR by equipping our baseline with a multi-scale structural and textural prior computed from the pre-trained VGG network. This prior has proven effective in discriminating structure and texture across different locations and scales, which is beneficial for AVSR. Comprehensive experiments show that ST-AVSR significantly improves super-resolution quality, generalization ability, and inference speed over the state-of-theart. The code is available at https://github.com/shangwei5/ST-AVSR.
Improving Image Restoration through Removing Degradations in Textual Representations
Dec 28, 2023



In this paper, we introduce a new perspective for improving image restoration by removing degradation in the textual representations of a given degraded image. Intuitively, restoration is much easier on text modality than image one. For example, it can be easily conducted by removing degradation-related words while keeping the content-aware words. Hence, we combine the advantages of images in detail description and ones of text in degradation removal to perform restoration. To address the cross-modal assistance, we propose to map the degraded images into textual representations for removing the degradations, and then convert the restored textual representations into a guidance image for assisting image restoration. In particular, We ingeniously embed an image-to-text mapper and text restoration module into CLIP-equipped text-to-image models to generate the guidance. Then, we adopt a simple coarse-to-fine approach to dynamically inject multi-scale information from guidance to image restoration networks. Extensive experiments are conducted on various image restoration tasks, including deblurring, dehazing, deraining, and denoising, and all-in-one image restoration. The results showcase that our method outperforms state-of-the-art ones across all these tasks. The codes and models are available at \url{https://github.com/mrluin/TextualDegRemoval}.
Aggregating Long-term Sharp Features via Hybrid Transformers for Video Deblurring
Sep 13, 2023



Video deblurring methods, aiming at recovering consecutive sharp frames from a given blurry video, usually assume that the input video suffers from consecutively blurry frames. However, in real-world blurry videos taken by modern imaging devices, sharp frames usually appear in the given video, thus making temporal long-term sharp features available for facilitating the restoration of a blurry frame. In this work, we propose a video deblurring method that leverages both neighboring frames and present sharp frames using hybrid Transformers for feature aggregation. Specifically, we first train a blur-aware detector to distinguish between sharp and blurry frames. Then, a window-based local Transformer is employed for exploiting features from neighboring frames, where cross attention is beneficial for aggregating features from neighboring frames without explicit spatial alignment. To aggregate long-term sharp features from detected sharp frames, we utilize a global Transformer with multi-scale matching capability. Moreover, our method can easily be extended to event-driven video deblurring by incorporating an event fusion module into the global Transformer. Extensive experiments on benchmark datasets demonstrate that our proposed method outperforms state-of-the-art video deblurring methods as well as event-driven video deblurring methods in terms of quantitative metrics and visual quality. The source code and trained models are available at https://github.com/shangwei5/STGTN.
Self-supervised Learning to Bring Dual Reversed Rolling Shutter Images Alive
May 31, 2023



Modern consumer cameras usually employ the rolling shutter (RS) mechanism, where images are captured by scanning scenes row-by-row, yielding RS distortions for dynamic scenes. To correct RS distortions, existing methods adopt a fully supervised learning manner, where high framerate global shutter (GS) images should be collected as ground-truth supervision. In this paper, we propose a Self-supervised learning framework for Dual reversed RS distortions Correction (SelfDRSC), where a DRSC network can be learned to generate a high framerate GS video only based on dual RS images with reversed distortions. In particular, a bidirectional distortion warping module is proposed for reconstructing dual reversed RS images, and then a self-supervised loss can be deployed to train DRSC network by enhancing the cycle consistency between input and reconstructed dual reversed RS images. Besides start and end RS scanning time, GS images at arbitrary intermediate scanning time can also be supervised in SelfDRSC, thus enabling the learned DRSC network to generate a high framerate GS video. Moreover, a simple yet effective self-distillation strategy is introduced in self-supervised loss for mitigating boundary artifacts in generated GS images. On synthetic dataset, SelfDRSC achieves better or comparable quantitative metrics in comparison to state-of-the-art methods trained in the full supervision manner. On real-world RS cases, our SelfDRSC can produce high framerate GS videos with finer correction textures and better temporary consistency. The source code and trained models are made publicly available at https://github.com/shangwei5/SelfDRSC.
Joint Video Multi-Frame Interpolation and Deblurring under Unknown Exposure Time
Mar 27, 2023



Natural videos captured by consumer cameras often suffer from low framerate and motion blur due to the combination of dynamic scene complexity, lens and sensor imperfection, and less than ideal exposure setting. As a result, computational methods that jointly perform video frame interpolation and deblurring begin to emerge with the unrealistic assumption that the exposure time is known and fixed. In this work, we aim ambitiously for a more realistic and challenging task - joint video multi-frame interpolation and deblurring under unknown exposure time. Toward this goal, we first adopt a variant of supervised contrastive learning to construct an exposure-aware representation from input blurred frames. We then train two U-Nets for intra-motion and inter-motion analysis, respectively, adapting to the learned exposure representation via gain tuning. We finally build our video reconstruction network upon the exposure and motion representation by progressive exposure-adaptive convolution and motion refinement. Extensive experiments on both simulated and real-world datasets show that our optimized method achieves notable performance gains over the state-of-the-art on the joint video x8 interpolation and deblurring task. Moreover, on the seemingly implausible x16 interpolation task, our method outperforms existing methods by more than 1.5 dB in terms of PSNR.
Learning Single Image Defocus Deblurring with Misaligned Training Pairs
Nov 29, 2022



By adopting popular pixel-wise loss, existing methods for defocus deblurring heavily rely on well aligned training image pairs. Although training pairs of ground-truth and blurry images are carefully collected, e.g., DPDD dataset, misalignment is inevitable between training pairs, making existing methods possibly suffer from deformation artifacts. In this paper, we propose a joint deblurring and reblurring learning (JDRL) framework for single image defocus deblurring with misaligned training pairs. Generally, JDRL consists of a deblurring module and a spatially invariant reblurring module, by which deblurred result can be adaptively supervised by ground-truth image to recover sharp textures while maintaining spatial consistency with the blurry image. First, in the deblurring module, a bi-directional optical flow-based deformation is introduced to tolerate spatial misalignment between deblurred and ground-truth images. Second, in the reblurring module, deblurred result is reblurred to be spatially aligned with blurry image, by predicting a set of isotropic blur kernels and weighting maps. Moreover, we establish a new single image defocus deblurring (SDD) dataset, further validating our JDRL and also benefiting future research. Our JDRL can be applied to boost defocus deblurring networks in terms of both quantitative metrics and visual quality on DPDD, RealDOF and our SDD datasets.
Robust Deep Ensemble Method for Real-world Image Denoising
Jun 08, 2022

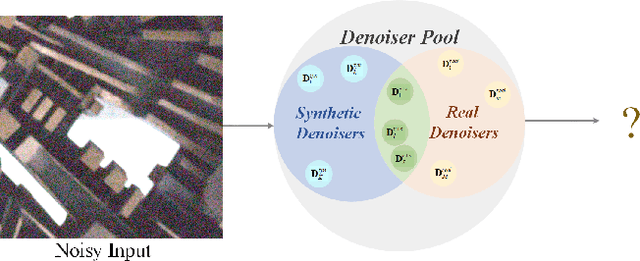
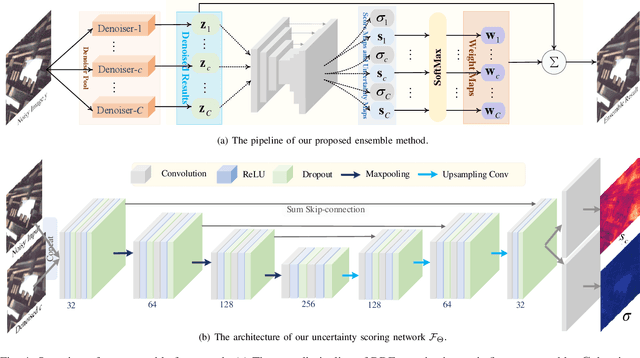
Recently, deep learning-based image denoising methods have achieved promising performance on test data with the same distribution as training set, where various denoising models based on synthetic or collected real-world training data have been learned. However, when handling real-world noisy images, the denoising performance is still limited. In this paper, we propose a simple yet effective Bayesian deep ensemble (BDE) method for real-world image denoising, where several representative deep denoisers pre-trained with various training data settings can be fused to improve robustness. The foundation of BDE is that real-world image noises are highly signal-dependent, and heterogeneous noises in a real-world noisy image can be separately handled by different denoisers. In particular, we take well-trained CBDNet, NBNet, HINet, Uformer and GMSNet into denoiser pool, and a U-Net is adopted to predict pixel-wise weighting maps to fuse these denoisers. Instead of solely learning pixel-wise weighting maps, Bayesian deep learning strategy is introduced to predict weighting uncertainty as well as weighting map, by which prediction variance can be modeled for improving robustness on real-world noisy images. Extensive experiments have shown that real-world noises can be better removed by fusing existing denoisers instead of training a big denoiser with expensive cost. On DND dataset, our BDE achieves +0.28~dB PSNR gain over the state-of-the-art denoising method. Moreover, we note that our BDE denoiser based on different Gaussian noise levels outperforms state-of-the-art CBDNet when applying to real-world noisy images. Furthermore, our BDE can be extended to other image restoration tasks, and achieves +0.30dB, +0.18dB and +0.12dB PSNR gains on benchmark datasets for image deblurring, image deraining and single image super-resolution, respectively.
Learning Dual-Pixel Alignment for Defocus Deblurring
Apr 26, 2022



It is a challenging task to recover all-in-focus image from a single defocus blurry image in real-world applications. On many modern cameras, dual-pixel (DP) sensors create two-image views, based on which stereo information can be exploited to benefit defocus deblurring. Despite existing DP defocus deblurring methods achieving impressive results, they directly take naive concatenation of DP views as input, while neglecting the disparity between left and right views in the regions out of camera's depth of field (DoF). In this work, we propose a Dual-Pixel Alignment Network (DPANet) for defocus deblurring. Generally, DPANet is an encoder-decoder with skip-connections, where two branches with shared parameters in the encoder are employed to extract and align deep features from left and right views, and one decoder is adopted to fuse aligned features for predicting the all-in-focus image. Due to that DP views suffer from different blur amounts, it is not trivial to align left and right views. To this end, we propose novel encoder alignment module (EAM) and decoder alignment module (DAM). In particular, a correlation layer is suggested in EAM to measure the disparity between DP views, whose deep features can then be accordingly aligned using deformable convolutions. And DAM can further enhance the alignment of skip-connected features from encoder and deep features in decoder. By introducing several EAMs and DAMs, DP views in DPANet can be well aligned for better predicting latent all-in-focus image. Experimental results on real-world datasets show that our DPANet is notably superior to state-of-the-art deblurring methods in reducing defocus blur while recovering visually plausible sharp structures and textures.
NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022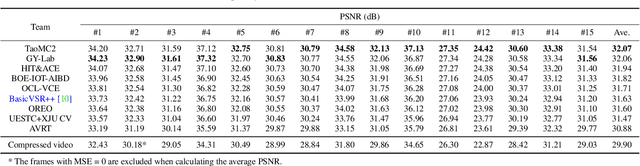
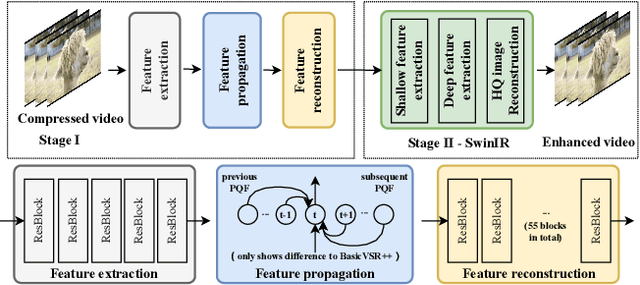
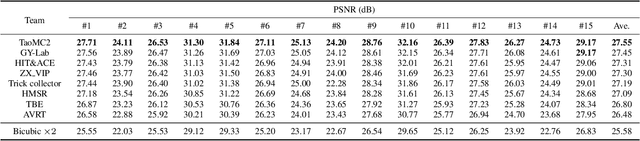

This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.
Incorporating Semi-Supervised and Positive-Unlabeled Learning for Boosting Full Reference Image Quality Assessment
Apr 19, 2022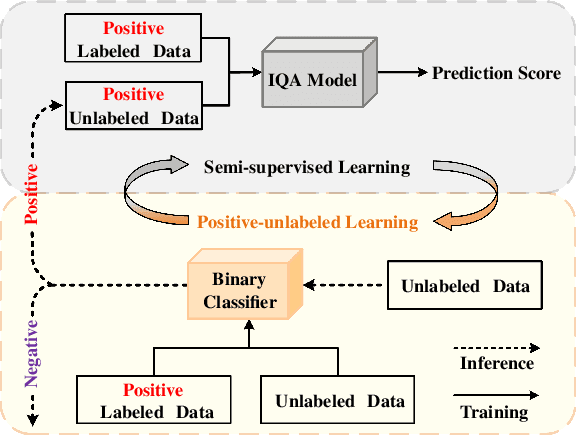
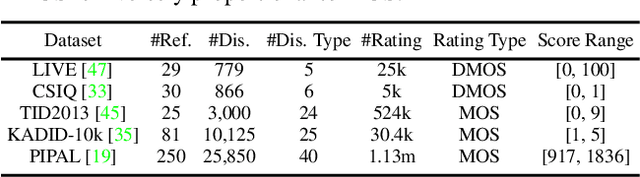
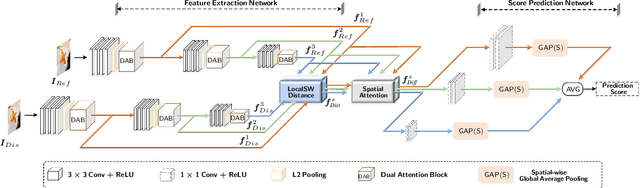
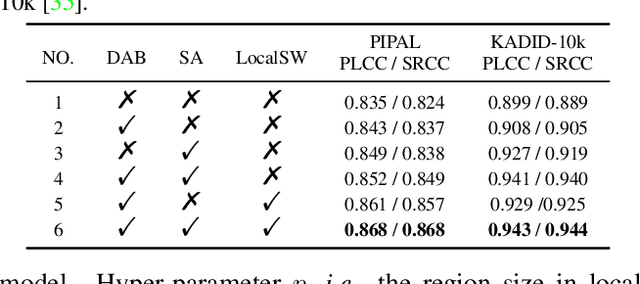
Full-reference (FR) image quality assessment (IQA) evaluates the visual quality of a distorted image by measuring its perceptual difference with pristine-quality reference, and has been widely used in low-level vision tasks. Pairwise labeled data with mean opinion score (MOS) are required in training FR-IQA model, but is time-consuming and cumbersome to collect. In contrast, unlabeled data can be easily collected from an image degradation or restoration process, making it encouraging to exploit unlabeled training data to boost FR-IQA performance. Moreover, due to the distribution inconsistency between labeled and unlabeled data, outliers may occur in unlabeled data, further increasing the training difficulty. In this paper, we suggest to incorporate semi-supervised and positive-unlabeled (PU) learning for exploiting unlabeled data while mitigating the adverse effect of outliers. Particularly, by treating all labeled data as positive samples, PU learning is leveraged to identify negative samples (i.e., outliers) from unlabeled data. Semi-supervised learning (SSL) is further deployed to exploit positive unlabeled data by dynamically generating pseudo-MOS. We adopt a dual-branch network including reference and distortion branches. Furthermore, spatial attention is introduced in the reference branch to concentrate more on the informative regions, and sliced Wasserstein distance is used for robust difference map computation to address the misalignment issues caused by images recovered by GAN models. Extensive experiments show that our method performs favorably against state-of-the-arts on the benchmark datasets PIPAL, KADID-10k, TID2013, LIVE and CSIQ.