 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupplement Generation Training for Enhancing Agentic Task Performance
Apr 22, 2026Training large foundation models for agentic tasks is increasingly impractical due to the high computational costs, long iteration cycles, and rapid obsolescence as new models are continuously released. Instead of post-training massive models for every new task or domain, we propose Supplement Generation Training (SGT), a more efficient and sustainable strategy. SGT trains a smaller LLM to generate useful supplemental text that, when appended to the original input, helps the larger LLM solve the task more effectively. These lightweight models can dynamically adapt supplements to task requirements, improving performance without modifying the underlying large models. This approach decouples task-specific optimization from large foundation models and enables more flexible, cost-effective deployment of LLM-powered agents in real-world applications.
Feedback Friction: LLMs Struggle to Fully Incorporate External Feedback
Jun 13, 2025Recent studies have shown LLMs possess some ability to improve their responses when given external feedback. However, it remains unclear how effectively and thoroughly these models can incorporate extrinsic feedback. In an ideal scenario, if LLMs receive near-perfect and complete feedback, we would expect them to fully integrate the feedback and change their incorrect answers to correct ones. In this paper, we systematically investigate LLMs' ability to incorporate feedback by designing a controlled experimental environment. For each problem, a solver model attempts a solution, then a feedback generator with access to near-complete ground-truth answers produces targeted feedback, after which the solver tries again. We evaluate this pipeline across a diverse range of tasks, including math reasoning, knowledge reasoning, scientific reasoning, and general multi-domain evaluations with state-of-the-art language models including Claude 3.7 (with and without extended thinking). Surprisingly, even under these near-ideal conditions, solver models consistently show resistance to feedback, a limitation that we term FEEDBACK FRICTION. To mitigate this limitation, we experiment with sampling-based strategies like progressive temperature increases and explicit rejection of previously attempted incorrect answers, which yield improvements but still fail to help models achieve target performance. We also perform a rigorous exploration of potential causes of FEEDBACK FRICTION, ruling out factors such as model overconfidence and data familiarity. We hope that highlighting this issue in LLMs and ruling out several apparent causes will help future research in self-improvement.
Upsample or Upweight? Balanced Training on Heavily Imbalanced Datasets
Oct 06, 2024



Data availability across domains often follows a long-tail distribution: a few domains have abundant data, while most face data scarcity. This imbalance poses challenges in training language models uniformly across all domains. In our study, we focus on multilingual settings, where data sizes vary significantly between high- and low-resource languages. Common strategies to address this include upsampling low-resource languages (Temperature Sampling) or upweighting their loss (Scalarization). Although often considered equivalent, this assumption has not been proven, which motivates our study. Through both theoretical and empirical analysis, we identify the conditions under which these approaches are equivalent and when they diverge. Specifically, we demonstrate that these two methods are equivalent under full gradient descent, but this equivalence breaks down with stochastic gradient descent. Empirically, we observe that Temperature Sampling converges more quickly but is prone to overfitting. We argue that this faster convergence is likely due to the lower variance in gradient estimations, as shown theoretically. Based on these insights, we propose Cooldown, a strategy that reduces sampling temperature during training, accelerating convergence without overfitting to low-resource languages. Our method is competitive with existing data re-weighting and offers computational efficiency.
RATIONALYST: Pre-training Process-Supervision for Improving Reasoning
Oct 01, 2024



The reasoning steps generated by LLMs might be incomplete, as they mimic logical leaps common in everyday communication found in their pre-training data: underlying rationales are frequently left implicit (unstated). To address this challenge, we introduce RATIONALYST, a model for process-supervision of reasoning based on pre-training on a vast collection of rationale annotations extracted from unlabeled data. We extract 79k rationales from web-scale unlabelled dataset (the Pile) and a combination of reasoning datasets with minimal human intervention. This web-scale pre-training for reasoning allows RATIONALYST to consistently generalize across diverse reasoning tasks, including mathematical, commonsense, scientific, and logical reasoning. Fine-tuned from LLaMa-3-8B, RATIONALYST improves the accuracy of reasoning by an average of 3.9% on 7 representative reasoning benchmarks. It also demonstrates superior performance compared to significantly larger verifiers like GPT-4 and similarly sized models fine-tuned on matching training sets.
To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning
Sep 18, 2024



Chain-of-thought (CoT) via prompting is the de facto method for eliciting reasoning capabilities from large language models (LLMs). But for what kinds of tasks is this extra ``thinking'' really helpful? To analyze this, we conducted a quantitative meta-analysis covering over 100 papers using CoT and ran our own evaluations of 20 datasets across 14 models. Our results show that CoT gives strong performance benefits primarily on tasks involving math or logic, with much smaller gains on other types of tasks. On MMLU, directly generating the answer without CoT leads to almost identical accuracy as CoT unless the question or model's response contains an equals sign, indicating symbolic operations and reasoning. Following this finding, we analyze the behavior of CoT on these problems by separating planning and execution and comparing against tool-augmented LLMs. Much of CoT's gain comes from improving symbolic execution, but it underperforms relative to using a symbolic solver. Our results indicate that CoT can be applied selectively, maintaining performance while saving inference costs. Furthermore, they suggest a need to move beyond prompt-based CoT to new paradigms that better leverage intermediate computation across the whole range of LLM applications.
Benchmarking Language Model Creativity: A Case Study on Code Generation
Jul 12, 2024



As LLMs become increasingly prevalent, it is interesting to consider how ``creative'' these models can be. From cognitive science, creativity consists of at least two key characteristics: \emph{convergent} thinking (purposefulness to achieve a given goal) and \emph{divergent} thinking (adaptability to new environments or constraints) \citep{runco2003critical}. In this work, we introduce a framework for quantifying LLM creativity that incorporates the two characteristics. This is achieved by (1) Denial Prompting pushes LLMs to come up with more creative solutions to a given problem by incrementally imposing new constraints on the previous solution, compelling LLMs to adopt new strategies, and (2) defining and computing the NeoGauge metric which examines both convergent and divergent thinking in the generated creative responses by LLMs. We apply the proposed framework on Codeforces problems, a natural data source for collecting human coding solutions. We quantify NeoGauge for various proprietary and open-source models and find that even the most creative model, GPT-4, still falls short of demonstrating human-like creativity. We also experiment with advanced reasoning strategies (MCTS, self-correction, etc.) and observe no significant improvement in creativity. As a by-product of our analysis, we release NeoCoder dataset for reproducing our results on future models.
SELF-CORRECT: LLMs Struggle with Refining Self-Generated Responses
Apr 04, 2024



Can LLMs continually improve their previous outputs for better results? An affirmative answer would require LLMs to be better at discriminating among previously-generated alternatives, than generating initial responses. We explore the validity of this hypothesis in practice. We first introduce a unified framework that allows us to compare the generative and discriminative capability of any model on any task. Then, in our resulting experimental analysis of several LLMs, we do not observe the performance of those models on discrimination to be reliably better than generation. We hope these findings inform the growing literature on self-improvement AI systems.
LeanReasoner: Boosting Complex Logical Reasoning with Lean
Mar 20, 2024Large language models (LLMs) often struggle with complex logical reasoning due to logical inconsistencies and the inherent difficulty of such reasoning. We use Lean, a theorem proving framework, to address these challenges. By formalizing logical reasoning problems into theorems within Lean, we can solve them by proving or disproving the corresponding theorems. This method reduces the risk of logical inconsistencies with the help of Lean's symbolic solver. It also enhances our ability to treat complex reasoning tasks by using Lean's extensive library of theorem proofs. Our method achieves state-of-the-art performance on the FOLIO dataset and achieves performance near this level on ProofWriter. Notably, these results were accomplished by fine-tuning on fewer than 100 in-domain samples for each dataset.
Enhancing Systematic Decompositional Natural Language Inference Using Informal Logic
Feb 27, 2024Contemporary language models enable new opportunities for structured reasoning with text, such as the construction and evaluation of intuitive, proof-like textual entailment trees without relying on brittle formal logic. However, progress in this direction has been hampered by a long-standing lack of a clear protocol for determining what valid compositional entailment is. This absence causes noisy datasets and limited performance gains by modern neuro-symbolic engines. To address these problems, we formulate a consistent and theoretically grounded approach to annotating decompositional entailment datasets, and evaluate its impact on LLM-based textual inference. We find that our resulting dataset, RDTE (Recognizing Decompositional Textual Entailment), has a substantially higher internal consistency (+9%) than prior decompositional entailment datasets, suggesting that RDTE is a significant step forward in the long-standing problem of forming a clear protocol for discerning entailment. We also find that training an RDTE-oriented entailment classifier via knowledge distillation and employing it in a modern neuro-symbolic reasoning engine significantly improves results (both accuracy and proof quality) over other entailment classifier baselines, illustrating the practical benefit of this advance for textual inference.
Speech SIMCLR: Combining Contrastive and Reconstruction Objective for Self-supervised Speech Representation Learning
Oct 27, 2020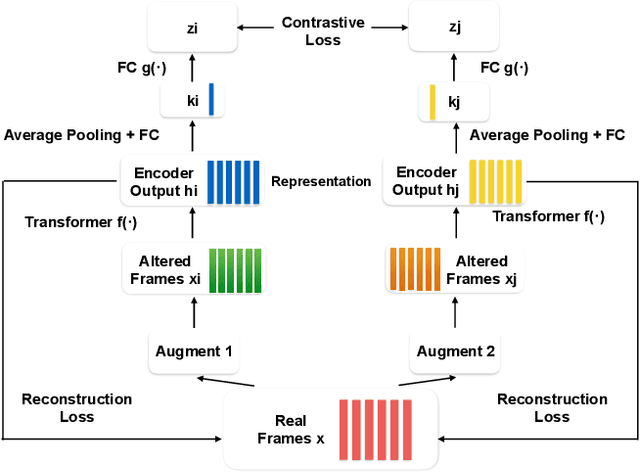

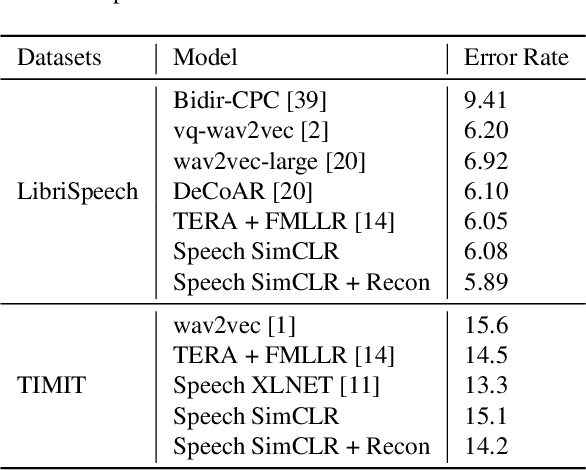

Self-supervised visual pretraining has shown significant progress recently. Among those methods, SimCLR greatly advanced the state of the art in self-supervised and semi-supervised learning on ImageNet. The input feature representations for speech and visual tasks are both continuous, so it is natural to consider applying similar objective on speech representation learning. In this paper, we propose Speech SimCLR, a new self-supervised objective for speech representation learning. During training, Speech SimCLR applies augmentation on raw speech and its spectrogram. Its objective is the combination of contrastive loss that maximizes agreement between differently augmented samples in the latent space and reconstruction loss of input representation. The proposed method achieved competitive results on speech emotion recognition and speech recognition. When used as feature extractor, our best model achieved 5.89% word error rate on LibriSpeech test-clean set using LibriSpeech 960 hours as pretraining data and LibriSpeech train-clean-100 set as fine-tuning data, which is the lowest error rate obtained in this setup to the best of our knowledge.