 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Signal and Variance: Adaptive Offline RL Post-Training for VLA Flow Models
Sep 04, 2025



Vision-Language-Action (VLA) models based on flow matching have shown excellent performance in general-purpose robotic manipulation tasks. However, the action accuracy of these models on complex downstream tasks is unsatisfactory. One important reason is that these models rely solely on the post-training paradigm of imitation learning, which makes it difficult to have a deeper understanding of the distribution properties of data quality, which is exactly what Reinforcement Learning (RL) excels at. In this paper, we theoretically propose an offline RL post-training objective for VLA flow models and induce an efficient and feasible offline RL fine-tuning algorithm -- Adaptive Reinforced Flow Matching (ARFM). By introducing an adaptively adjusted scaling factor in the VLA flow model loss, we construct a principled bias-variance trade-off objective function to optimally control the impact of RL signal on flow loss. ARFM adaptively balances RL advantage preservation and flow loss gradient variance control, resulting in a more stable and efficient fine-tuning process. Extensive simulation and real-world experimental results show that ARFM exhibits excellent generalization, robustness, few-shot learning, and continuous learning performance.
Long-VLA: Unleashing Long-Horizon Capability of Vision Language Action Model for Robot Manipulation
Aug 28, 2025Vision-Language-Action (VLA) models have become a cornerstone in robotic policy learning, leveraging large-scale multimodal data for robust and scalable control. However, existing VLA frameworks primarily address short-horizon tasks, and their effectiveness on long-horizon, multi-step robotic manipulation remains limited due to challenges in skill chaining and subtask dependencies. In this work, we introduce Long-VLA, the first end-to-end VLA model specifically designed for long-horizon robotic tasks. Our approach features a novel phase-aware input masking strategy that adaptively segments each subtask into moving and interaction phases, enabling the model to focus on phase-relevant sensory cues and enhancing subtask compatibility. This unified strategy preserves the scalability and data efficiency of VLA training, and our architecture-agnostic module can be seamlessly integrated into existing VLA models. We further propose the L-CALVIN benchmark to systematically evaluate long-horizon manipulation. Extensive experiments on both simulated and real-world tasks demonstrate that Long-VLA significantly outperforms prior state-of-the-art methods, establishing a new baseline for long-horizon robotic control.
ReconVLA: Reconstructive Vision-Language-Action Model as Effective Robot Perceiver
Aug 14, 2025Recent advances in Vision-Language-Action (VLA) models have enabled robotic agents to integrate multimodal understanding with action execution. However, our empirical analysis reveals that current VLAs struggle to allocate visual attention to target regions. Instead, visual attention is always dispersed. To guide the visual attention grounding on the correct target, we propose ReconVLA, a reconstructive VLA model with an implicit grounding paradigm. Conditioned on the model's visual outputs, a diffusion transformer aims to reconstruct the gaze region of the image, which corresponds to the target manipulated objects. This process prompts the VLA model to learn fine-grained representations and accurately allocate visual attention, thus effectively leveraging task-specific visual information and conducting precise manipulation. Moreover, we curate a large-scale pretraining dataset comprising over 100k trajectories and 2 million data samples from open-source robotic datasets, further boosting the model's generalization in visual reconstruction. Extensive experiments in simulation and the real world demonstrate the superiority of our implicit grounding method, showcasing its capabilities of precise manipulation and generalization. Our project page is https://zionchow.github.io/ReconVLA/.
GCHR : Goal-Conditioned Hindsight Regularization for Sample-Efficient Reinforcement Learning
Aug 08, 2025Goal-conditioned reinforcement learning (GCRL) with sparse rewards remains a fundamental challenge in reinforcement learning. While hindsight experience replay (HER) has shown promise by relabeling collected trajectories with achieved goals, we argue that trajectory relabeling alone does not fully exploit the available experiences in off-policy GCRL methods, resulting in limited sample efficiency. In this paper, we propose Hindsight Goal-conditioned Regularization (HGR), a technique that generates action regularization priors based on hindsight goals. When combined with hindsight self-imitation regularization (HSR), our approach enables off-policy RL algorithms to maximize experience utilization. Compared to existing GCRL methods that employ HER and self-imitation techniques, our hindsight regularizations achieve substantially more efficient sample reuse and the best performances, which we empirically demonstrate on a suite of navigation and manipulation tasks.
Multi-Task Multi-Agent Reinforcement Learning via Skill Graphs
Jul 09, 2025Multi-task multi-agent reinforcement learning (MT-MARL) has recently gained attention for its potential to enhance MARL's adaptability across multiple tasks. However, it is challenging for existing multi-task learning methods to handle complex problems, as they are unable to handle unrelated tasks and possess limited knowledge transfer capabilities. In this paper, we propose a hierarchical approach that efficiently addresses these challenges. The high-level module utilizes a skill graph, while the low-level module employs a standard MARL algorithm. Our approach offers two contributions. First, we consider the MT-MARL problem in the context of unrelated tasks, expanding the scope of MTRL. Second, the skill graph is used as the upper layer of the standard hierarchical approach, with training independent of the lower layer, effectively handling unrelated tasks and enhancing knowledge transfer capabilities. Extensive experiments are conducted to validate these advantages and demonstrate that the proposed method outperforms the latest hierarchical MAPPO algorithms. Videos and code are available at https://github.com/WindyLab/MT-MARL-SG
CEED-VLA: Consistency Vision-Language-Action Model with Early-Exit Decoding
Jun 16, 2025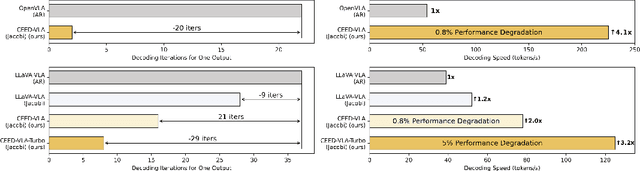

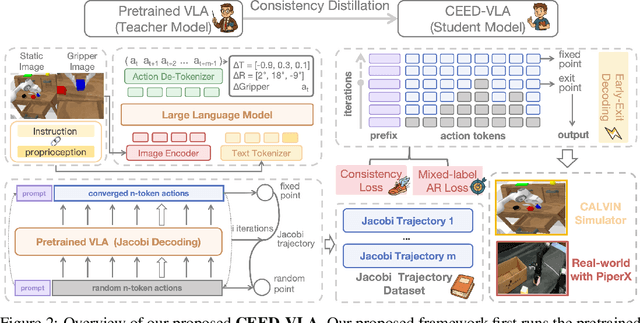
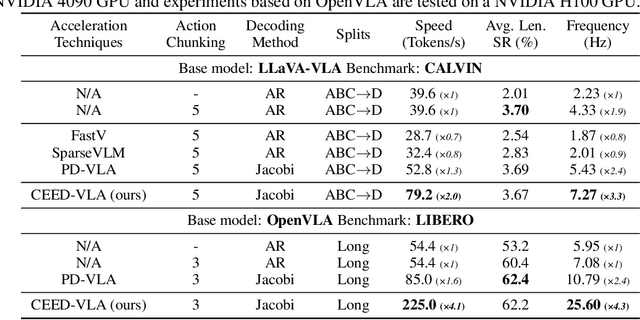
In recent years, Vision-Language-Action (VLA) models have become a vital research direction in robotics due to their impressive multimodal understanding and generalization capabilities. Despite the progress, their practical deployment is severely constrained by inference speed bottlenecks, particularly in high-frequency and dexterous manipulation tasks. While recent studies have explored Jacobi decoding as a more efficient alternative to traditional autoregressive decoding, its practical benefits are marginal due to the lengthy iterations. To address it, we introduce consistency distillation training to predict multiple correct action tokens in each iteration, thereby achieving acceleration. Besides, we design mixed-label supervision to mitigate the error accumulation during distillation. Although distillation brings acceptable speedup, we identify that certain inefficient iterations remain a critical bottleneck. To tackle this, we propose an early-exit decoding strategy that moderately relaxes convergence conditions, which further improves average inference efficiency. Experimental results show that the proposed method achieves more than 4 times inference acceleration across different baselines while maintaining high task success rates in both simulated and real-world robot tasks. These experiments validate that our approach provides an efficient and general paradigm for accelerating multimodal decision-making in robotics. Our project page is available at https://irpn-eai.github.io/CEED-VLA/.
RationalVLA: A Rational Vision-Language-Action Model with Dual System
Jun 12, 2025A fundamental requirement for real-world robotic deployment is the ability to understand and respond to natural language instructions. Existing language-conditioned manipulation tasks typically assume that instructions are perfectly aligned with the environment. This assumption limits robustness and generalization in realistic scenarios where instructions may be ambiguous, irrelevant, or infeasible. To address this problem, we introduce RAtional MAnipulation (RAMA), a new benchmark that challenges models with both unseen executable instructions and defective ones that should be rejected. In RAMA, we construct a dataset with over 14,000 samples, including diverse defective instructions spanning six dimensions: visual, physical, semantic, motion, safety, and out-of-context. We further propose the Rational Vision-Language-Action model (RationalVLA). It is a dual system for robotic arms that integrates the high-level vision-language model with the low-level manipulation policy by introducing learnable latent space embeddings. This design enables RationalVLA to reason over instructions, reject infeasible commands, and execute manipulation effectively. Experiments demonstrate that RationalVLA outperforms state-of-the-art baselines on RAMA by a 14.5% higher success rate and 0.94 average task length, while maintaining competitive performance on standard manipulation tasks. Real-world trials further validate its effectiveness and robustness in practical applications. Our project page is https://irpn-eai.github.io/rationalvla.
Efficient Online RL Fine Tuning with Offline Pre-trained Policy Only
May 22, 2025Improving the performance of pre-trained policies through online reinforcement learning (RL) is a critical yet challenging topic. Existing online RL fine-tuning methods require continued training with offline pretrained Q-functions for stability and performance. However, these offline pretrained Q-functions commonly underestimate state-action pairs beyond the offline dataset due to the conservatism in most offline RL methods, which hinders further exploration when transitioning from the offline to the online setting. Additionally, this requirement limits their applicability in scenarios where only pre-trained policies are available but pre-trained Q-functions are absent, such as in imitation learning (IL) pre-training. To address these challenges, we propose a method for efficient online RL fine-tuning using solely the offline pre-trained policy, eliminating reliance on pre-trained Q-functions. We introduce PORL (Policy-Only Reinforcement Learning Fine-Tuning), which rapidly initializes the Q-function from scratch during the online phase to avoid detrimental pessimism. Our method not only achieves competitive performance with advanced offline-to-online RL algorithms and online RL approaches that leverage data or policies prior, but also pioneers a new path for directly fine-tuning behavior cloning (BC) policies.
VARD: Efficient and Dense Fine-Tuning for Diffusion Models with Value-based RL
May 21, 2025



Diffusion models have emerged as powerful generative tools across various domains, yet tailoring pre-trained models to exhibit specific desirable properties remains challenging. While reinforcement learning (RL) offers a promising solution,current methods struggle to simultaneously achieve stable, efficient fine-tuning and support non-differentiable rewards. Furthermore, their reliance on sparse rewards provides inadequate supervision during intermediate steps, often resulting in suboptimal generation quality. To address these limitations, dense and differentiable signals are required throughout the diffusion process. Hence, we propose VAlue-based Reinforced Diffusion (VARD): a novel approach that first learns a value function predicting expection of rewards from intermediate states, and subsequently uses this value function with KL regularization to provide dense supervision throughout the generation process. Our method maintains proximity to the pretrained model while enabling effective and stable training via backpropagation. Experimental results demonstrate that our approach facilitates better trajectory guidance, improves training efficiency and extends the applicability of RL to diffusion models optimized for complex, non-differentiable reward functions.
SSR: Enhancing Depth Perception in Vision-Language Models via Rationale-Guided Spatial Reasoning
May 18, 2025Despite impressive advancements in Visual-Language Models (VLMs) for multi-modal tasks, their reliance on RGB inputs limits precise spatial understanding. Existing methods for integrating spatial cues, such as point clouds or depth, either require specialized sensors or fail to effectively exploit depth information for higher-order reasoning. To this end, we propose a novel Spatial Sense and Reasoning method, dubbed SSR, a novel framework that transforms raw depth data into structured, interpretable textual rationales. These textual rationales serve as meaningful intermediate representations to significantly enhance spatial reasoning capabilities. Additionally, we leverage knowledge distillation to compress the generated rationales into compact latent embeddings, which facilitate resource-efficient and plug-and-play integration into existing VLMs without retraining. To enable comprehensive evaluation, we introduce a new dataset named SSR-CoT, a million-scale visual-language reasoning dataset enriched with intermediate spatial reasoning annotations, and present SSRBench, a comprehensive multi-task benchmark. Extensive experiments on multiple benchmarks demonstrate SSR substantially improves depth utilization and enhances spatial reasoning, thereby advancing VLMs toward more human-like multi-modal understanding. Our project page is at https://yliu-cs.github.io/SSR.