 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Should World Models Be Evaluated? A Decision-Making-Centric Position
Jun 13, 2026World models have rapidly become one of the central abstractions in modern AI. Yet the term now refers to several different objects: action-conditioned environment models, latent imagination models, future-video predictors, interactive neural simulators, latent predictive representations, and synthetic-data engines. Evaluation has broadened with the term. Recent papers measure video realism, perceptual similarity, instruction following, physical plausibility, policy ranking, executability, planning success, and downstream policy improvement. The result is not only metric diversity but also a recurring problem of claim/evidence mismatch: papers frequently make a stronger claim about what their model is useful for than their evaluation can actually establish. This paper surveys the recent literature and argues that the central question is use-dependent. When a model is presented as a world model for embodied decision-making, a more decisive issue is not whether it generates visually compelling videos, but whether it supports reliable counterfactual reasoning, policy evaluation, planning, and policy optimization under intervention, policy-induced distribution shift, and long-horizon rollout. We organize the literature using an L0--L7 ladder that ranges from visual plausibility to policy optimization utility. In our interpretation, L0--L3 are most naturally read as diagnostics of generated artifacts, L4 is often the first genuinely interventional test, and L5--L7 provide the most direct evidence of decision usefulness. Based on this diagnosis, we propose a decision-making-centric evaluation framework and a benchmark protocol that foreground counterfactual action fidelity, closed-loop rollout validity, reward/value prediction, policy-ranking agreement, optimization lift, model exploitability, and uncertainty calibration.
Self-Distilled Policy Gradient
Jun 02, 2026On-policy self-distillation, where a language model conditions on privileged context to supervise its own generations, is a promising source of dense supervision for sparse-reward reinforcement learning. Actually, it can be instantiated as an auxiliary full-vocabulary student-to-teacher reverse Kullback-Leibler divergence loss. We therefore propose SDPG, a self-distilled policy-gradient framework that combines group-relative verifier advantages with normalized standard deviation, exact full-vocabulary on-policy self-distillation, as well as reference-policy KL regularization. Empirically, SDPG improves stability and performance over RLVR and self-distillation baselines. The code is available at https://github.com/lauyikfung/SDPG.
Dimension-Independent Convergence of Underdamped Langevin Monte Carlo in KL Divergence
Mar 02, 2026Underdamped Langevin dynamics (ULD) is a widely-used sampler for Gibbs distributions $π\propto e^{-V}$, and is often empirically effective in high dimensions. However, existing non-asymptotic convergence guarantees for discretized ULD typically scale polynomially with the ambient dimension $d$, leading to vacuous bounds when $d$ is large. The main known dimension-free result concerns the randomized midpoint discretization in Wasserstein-2 distance (Liu et al.,2023), while dimension-independent guarantees for ULD discretizations in KL divergence have remained open. We close this gap by proving the first dimension-free KL divergence bounds for discretized ULD. Our analysis refines the KL local error framework (Altschuler et al., 2025) to a dimension-free setting and yields bounds that depend on $\mathrm{tr}(\mathbf{H})$, where $\mathbf{H}$ upper bounds the Hessian of $V$, rather than on $d$. As a consequence, we obtain improved iteration complexity for underdamped Langevin Monte Carlo relative to overdamped Langevin methods in regimes where $\mathrm{tr}(\mathbf{H})\ll d$.
U-MASK: User-adaptive Spatio-Temporal Masking for Personalized Mobile AI Applications
Jan 11, 2026Personalized mobile artificial intelligence applications are widely deployed, yet they are expected to infer user behavior from sparse and irregular histories under a continuously evolving spatio-temporal context. This setting induces a fundamental tension among three requirements, i.e., immediacy to adapt to recent behavior, stability to resist transient noise, and generalization to support long-horizon prediction and cold-start users. Most existing approaches satisfy at most two of these requirements, resulting in an inherent impossibility triangle in data-scarce, non-stationary personalization. To address this challenge, we model mobile behavior as a partially observed spatio-temporal tensor and unify short-term adaptation, long-horizon forecasting, and cold-start recommendation as a conditional completion problem, where a user- and task-specific mask specifies which coordinates are treated as evidence. We propose U-MASK, a user-adaptive spatio-temporal masking method that allocates evidence budgets based on user reliability and task sensitivity. To enable mask generation under sparse observations, U-MASK learns a compact, task-agnostic user representation from app and location histories via U-SCOPE, which serves as the sole semantic conditioning signal. A shared diffusion transformer then performs mask-guided generative completion while preserving observed evidence, so personalization and task differentiation are governed entirely by the mask and the user representation. Experiments on real-world mobile datasets demonstrate consistent improvements over state-of-the-art methods across short-term prediction, long-horizon forecasting, and cold-start settings, with the largest gains under severe data sparsity. The code and dataset will be available at https://github.com/NICE-HKU/U-MASK.
Exploring Training Data Attribution under Limited Access Constraints
Sep 16, 2025



Training data attribution (TDA) plays a critical role in understanding the influence of individual training data points on model predictions. Gradient-based TDA methods, popularized by \textit{influence function} for their superior performance, have been widely applied in data selection, data cleaning, data economics, and fact tracing. However, in real-world scenarios where commercial models are not publicly accessible and computational resources are limited, existing TDA methods are often constrained by their reliance on full model access and high computational costs. This poses significant challenges to the broader adoption of TDA in practical applications. In this work, we present a systematic study of TDA methods under various access and resource constraints. We investigate the feasibility of performing TDA under varying levels of access constraints by leveraging appropriately designed solutions such as proxy models. Besides, we demonstrate that attribution scores obtained from models without prior training on the target dataset remain informative across a range of tasks, which is useful for scenarios where computational resources are limited. Our findings provide practical guidance for deploying TDA in real-world environments, aiming to improve feasibility and efficiency under limited access.
Balancing Signal and Variance: Adaptive Offline RL Post-Training for VLA Flow Models
Sep 04, 2025



Vision-Language-Action (VLA) models based on flow matching have shown excellent performance in general-purpose robotic manipulation tasks. However, the action accuracy of these models on complex downstream tasks is unsatisfactory. One important reason is that these models rely solely on the post-training paradigm of imitation learning, which makes it difficult to have a deeper understanding of the distribution properties of data quality, which is exactly what Reinforcement Learning (RL) excels at. In this paper, we theoretically propose an offline RL post-training objective for VLA flow models and induce an efficient and feasible offline RL fine-tuning algorithm -- Adaptive Reinforced Flow Matching (ARFM). By introducing an adaptively adjusted scaling factor in the VLA flow model loss, we construct a principled bias-variance trade-off objective function to optimally control the impact of RL signal on flow loss. ARFM adaptively balances RL advantage preservation and flow loss gradient variance control, resulting in a more stable and efficient fine-tuning process. Extensive simulation and real-world experimental results show that ARFM exhibits excellent generalization, robustness, few-shot learning, and continuous learning performance.
LSDM: LLM-Enhanced Spatio-temporal Diffusion Model for Service-Level Mobile Traffic Prediction
Jul 23, 2025



Service-level mobile traffic prediction for individual users is essential for network efficiency and quality of service enhancement. However, current prediction methods are limited in their adaptability across different urban environments and produce inaccurate results due to the high uncertainty in personal traffic patterns, the lack of detailed environmental context, and the complex dependencies among different network services. These challenges demand advanced modeling techniques that can capture dynamic traffic distributions and rich environmental features. Inspired by the recent success of diffusion models in distribution modeling and Large Language Models (LLMs) in contextual understanding, we propose an LLM-Enhanced Spatio-temporal Diffusion Model (LSDM). LSDM integrates the generative power of diffusion models with the adaptive learning capabilities of transformers, augmented by the ability to capture multimodal environmental information for modeling service-level patterns and dynamics. Extensive evaluations on real-world service-level datasets demonstrate that the model excels in traffic usage predictions, showing outstanding generalization and adaptability. After incorporating contextual information via LLM, the performance improves by at least 2.83% in terms of the coefficient of determination. Compared to models of a similar type, such as CSDI, the root mean squared error can be reduced by at least 8.29%. The code and dataset will be available at: https://github.com/SoftYuaneR/LSDM.
Taming Hyperparameter Sensitivity in Data Attribution: Practical Selection Without Costly Retraining
May 30, 2025Data attribution methods, which quantify the influence of individual training data points on a machine learning model, have gained increasing popularity in data-centric applications in modern AI. Despite a recent surge of new methods developed in this space, the impact of hyperparameter tuning in these methods remains under-explored. In this work, we present the first large-scale empirical study to understand the hyperparameter sensitivity of common data attribution methods. Our results show that most methods are indeed sensitive to certain key hyperparameters. However, unlike typical machine learning algorithms -- whose hyperparameters can be tuned using computationally-cheap validation metrics -- evaluating data attribution performance often requires retraining models on subsets of training data, making such metrics prohibitively costly for hyperparameter tuning. This poses a critical open challenge for the practical application of data attribution methods. To address this challenge, we advocate for better theoretical understandings of hyperparameter behavior to inform efficient tuning strategies. As a case study, we provide a theoretical analysis of the regularization term that is critical in many variants of influence function methods. Building on this analysis, we propose a lightweight procedure for selecting the regularization value without model retraining, and validate its effectiveness across a range of standard data attribution benchmarks. Overall, our study identifies a fundamental yet overlooked challenge in the practical application of data attribution, and highlights the importance of careful discussion on hyperparameter selection in future method development.
TimeCausality: Evaluating the Causal Ability in Time Dimension for Vision Language Models
May 21, 2025
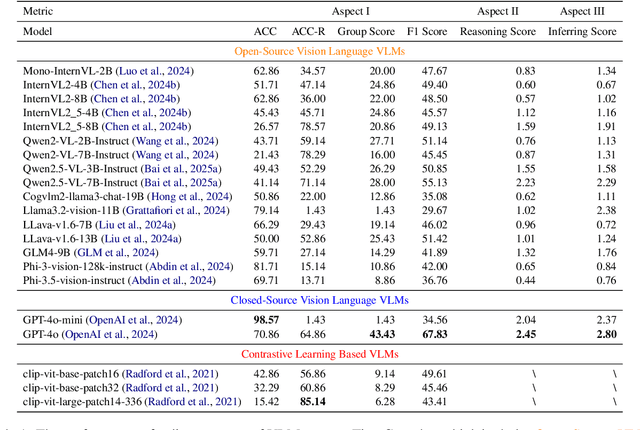


Reasoning about temporal causality, particularly irreversible transformations of objects governed by real-world knowledge (e.g., fruit decay and human aging), is a fundamental aspect of human visual understanding. Unlike temporal perception based on simple event sequences, this form of reasoning requires a deeper comprehension of how object states change over time. Although the current powerful Vision-Language Models (VLMs) have demonstrated impressive performance on a wide range of downstream tasks, their capacity to reason about temporal causality remains underexplored. To address this gap, we introduce \textbf{TimeCausality}, a novel benchmark specifically designed to evaluate the causal reasoning ability of VLMs in the temporal dimension. Based on our TimeCausality, we find that while the current SOTA open-source VLMs have achieved performance levels comparable to closed-source models like GPT-4o on various standard visual question answering tasks, they fall significantly behind on our benchmark compared with their closed-source competitors. Furthermore, even GPT-4o exhibits a marked drop in performance on TimeCausality compared to its results on other tasks. These findings underscore the critical need to incorporate temporal causality into the evaluation and development of VLMs, and they highlight an important challenge for the open-source VLM community moving forward. Code and Data are available at \href{https://github.com/Zeqing-Wang/TimeCausality }{TimeCausality}.
Energy-Weighted Flow Matching for Offline Reinforcement Learning
Mar 06, 2025This paper investigates energy guidance in generative modeling, where the target distribution is defined as $q(\mathbf x) \propto p(\mathbf x)\exp(-\beta \mathcal E(\mathbf x))$, with $p(\mathbf x)$ being the data distribution and $\mathcal E(\mathcal x)$ as the energy function. To comply with energy guidance, existing methods often require auxiliary procedures to learn intermediate guidance during the diffusion process. To overcome this limitation, we explore energy-guided flow matching, a generalized form of the diffusion process. We introduce energy-weighted flow matching (EFM), a method that directly learns the energy-guided flow without the need for auxiliary models. Theoretical analysis shows that energy-weighted flow matching accurately captures the guided flow. Additionally, we extend this methodology to energy-weighted diffusion models and apply it to offline reinforcement learning (RL) by proposing the Q-weighted Iterative Policy Optimization (QIPO). Empirically, we demonstrate that the proposed QIPO algorithm improves performance in offline RL tasks. Notably, our algorithm is the first energy-guided diffusion model that operates independently of auxiliary models and the first exact energy-guided flow matching model in the literature.