 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Coarse-to-Fine Subgoal Refinement for Long-Horizon Offline Goal-Conditioned Reinforcement Learning
May 27, 2026Offline goal-conditioned reinforcement learning (GCRL) is challenging in long-horizon tasks, where distant state--goal pairs provide weak supervision and value estimates become vulnerable to accumulated bootstrapping errors. Hierarchical methods mitigate this difficulty by introducing intermediate subgoals, but fixed temporal abstractions or fixed hierarchy depths can be mismatched to state--goal pairs with different reachability horizons. We propose Coarse-to-Fine Hierarchical Goal Reinforcement Learning (CFHRL), a fully offline GCRL framework that adaptively refines distant goals before execution. Starting from the final goal, CFHRL recursively proposes intermediate targets, trained from replay-supported candidates, and stops refinement once the current target is estimated to be locally executable by a learned reachability cost. The key idea is that a subgoal need not be an exact midpoint or globally optimal waypoint; it only needs to provide reliable progress and reduce the remaining reaching difficulty, enabling subsequent refinement over shorter horizons. A stylized analysis further supports the robustness of approximate recursive contraction. Experiments on OGBench show substantial gains on several long-horizon tasks, with ablations validating the proposed refinement and stopping mechanisms
Context-Picker: Dynamic context selection using multi-stage reinforcement learning
Dec 16, 2025



In long-context question answering (LCQA), determining the optimal amount of context for a given query is a significant challenge. Including too few passages may omit critical information, while including too many can introduce noise and reduce the quality of the answer. Traditional approaches, such as fixed Top-$K$ retrieval and single-stage reranking, face the dilemma of selecting the right number of passages. This problem is particularly pronounced for factoid questions, which often require only a few specific pieces of evidence. To address this issue, we introduce \emph{Context-Picker}, a reasoning-aware framework that shifts the paradigm from similarity-based ranking to minimal sufficient subset selection. Context-Picker treats context selection as a decision-making process optimized via a human-inspired, two-stage reinforcement learning schedule: a \emph{recall-oriented} stage that prioritizes the coverage of reasoning chains, followed by a \emph{precision-oriented} stage that aggressively prunes redundancy to distill a compact evidence set. To resolve reward sparsity, we propose an offline evidence distillation pipeline that mines "minimal sufficient sets" via a Leave-One-Out (LOO) procedure, providing dense, task-aligned supervision. Experiments on five long-context and multi-hop QA benchmarks demonstrate that Context-Picker significantly outperforms strong RAG baselines, achieving superior answer accuracy with comparable or reduced context lengths. Ablation studies indicate that the coarse-to-fine optimization schedule, the redundancy-aware reward shaping, and the rationale-guided format all contribute substantially to these gains.
H$^2$R: Hierarchical Hindsight Reflection for Multi-Task LLM Agents
Sep 16, 2025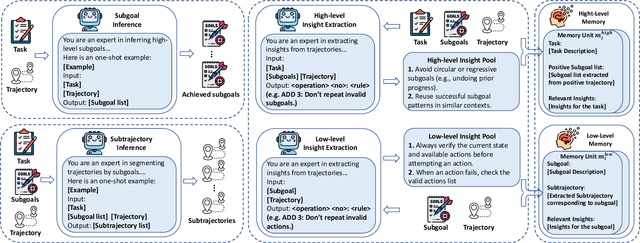
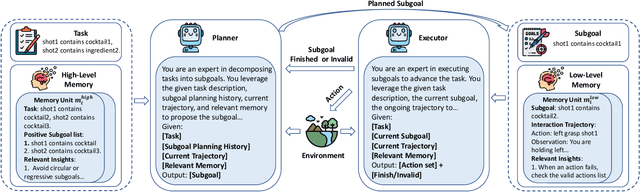
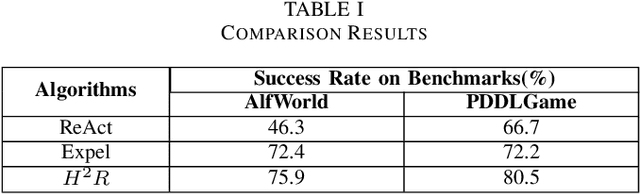

Large language model (LLM)-based agents have shown strong potential in multi-task scenarios, owing to their ability to transfer knowledge across diverse tasks. However, existing approaches often treat prior experiences and knowledge as monolithic units, leading to inefficient and coarse-grained knowledge transfer. In this work, we propose a novel hierarchical memory architecture that enables fine-grained knowledge transfer by decoupling high-level planning memory from low-level execution memory. To construct and refine these hierarchical memories, we introduce Hierarchical Hindsight Reflection (H$^2$R), a mechanism that distills reusable and hierarchical knowledge from past agent-environment interactions. At test time, H$^2$R performs retrievals of high-level and low-level memories separately, allowing LLM-based agents to efficiently access and utilize task-relevant knowledge for new tasks.Experimental results across two benchmarks demonstrate that H$^2$R can improve generalization and decision-making performance, outperforming prior baselines such as Expel.
GCHR : Goal-Conditioned Hindsight Regularization for Sample-Efficient Reinforcement Learning
Aug 08, 2025



Goal-conditioned reinforcement learning (GCRL) with sparse rewards remains a fundamental challenge in reinforcement learning. While hindsight experience replay (HER) has shown promise by relabeling collected trajectories with achieved goals, we argue that trajectory relabeling alone does not fully exploit the available experiences in off-policy GCRL methods, resulting in limited sample efficiency. In this paper, we propose Hindsight Goal-conditioned Regularization (HGR), a technique that generates action regularization priors based on hindsight goals. When combined with hindsight self-imitation regularization (HSR), our approach enables off-policy RL algorithms to maximize experience utilization. Compared to existing GCRL methods that employ HER and self-imitation techniques, our hindsight regularizations achieve substantially more efficient sample reuse and the best performances, which we empirically demonstrate on a suite of navigation and manipulation tasks.