 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniScale: Unified Scale-Aware 3D Reconstruction for Multi-View Understanding via Prior Injection for Robotic Perception
Feb 26, 2026We present UniScale, a unified, scale-aware multi-view 3D reconstruction framework for robotic applications that flexibly integrates geometric priors through a modular, semantically informed design. In vision-based robotic navigation, the accurate extraction of environmental structure from raw image sequences is critical for downstream tasks. UniScale addresses this challenge with a single feed-forward network that jointly estimates camera intrinsics and extrinsics, scale-invariant depth and point maps, and the metric scale of a scene from multi-view images, while optionally incorporating auxiliary geometric priors when available. By combining global contextual reasoning with camera-aware feature representations, UniScale is able to recover the metric-scale of the scene. In robotic settings where camera intrinsics are known, they can be easily incorporated to improve performance, with additional gains obtained when camera poses are also available. This co-design enables robust, metric-aware 3D reconstruction within a single unified model. Importantly, UniScale does not require training from scratch, and leverages world priors exhibited in pre-existing models without geometric encoding strategies, making it particularly suitable for resource-constrained robotic teams. We evaluate UniScale on multiple benchmarks, demonstrating strong generalization and consistent performance across diverse environments. We will release our implementation upon acceptance.
TileTracker: Tracking Based Vector HD Mapping using Top-Down Road Images
Nov 04, 2024



In this paper, we propose a tracking-based HD mapping algorithm for top-down road images, referred to as tile images. While HD maps traditionally rely on perspective camera images, our approach shows that tile images can also be effectively utilized, offering valuable contributions to this research area as it can be start of a new path in HD mapping algorithms. We modified the BEVFormer layers to generate BEV masks from tile images, which are then used by the model to generate divider and boundary lines. Our model was tested with both color and intensity images, and we present quantitative and qualitative results to demonstrate its performance.
Language Supervised Human Action Recognition with Salient Fusion: Construction Worker Action Recognition as a Use Case
Oct 02, 2024



Detecting human actions is a crucial task for autonomous robots and vehicles, often requiring the integration of various data modalities for improved accuracy. In this study, we introduce a novel approach to Human Action Recognition (HAR) based on skeleton and visual cues. Our method leverages a language model to guide the feature extraction process in the skeleton encoder. Specifically, we employ learnable prompts for the language model conditioned on the skeleton modality to optimize feature representation. Furthermore, we propose a fusion mechanism that combines dual-modality features using a salient fusion module, incorporating attention and transformer mechanisms to address the modalities' high dimensionality. This fusion process prioritizes informative video frames and body joints, enhancing the recognition accuracy of human actions. Additionally, we introduce a new dataset tailored for real-world robotic applications in construction sites, featuring visual, skeleton, and depth data modalities, named VolvoConstAct. This dataset serves to facilitate the training and evaluation of machine learning models to instruct autonomous construction machines for performing necessary tasks in the real world construction zones. To evaluate our approach, we conduct experiments on our dataset as well as three widely used public datasets, NTU-RGB+D, NTU-RGB+D120 and NW-UCLA. Results reveal that our proposed method achieves promising performance across all datasets, demonstrating its robustness and potential for various applications. The codes and dataset are available at: https://mmahdavian.github.io/ls_har/
LeTFuser: Light-weight End-to-end Transformer-Based Sensor Fusion for Autonomous Driving with Multi-Task Learning
Oct 19, 2023



In end-to-end autonomous driving, the utilization of existing sensor fusion techniques for imitation learning proves inadequate in challenging situations that involve numerous dynamic agents. To address this issue, we introduce LeTFuser, a transformer-based algorithm for fusing multiple RGB-D camera representations. To perform perception and control tasks simultaneously, we utilize multi-task learning. Our model comprises of two modules, the first being the perception module that is responsible for encoding the observation data obtained from the RGB-D cameras. It carries out tasks such as semantic segmentation, semantic depth cloud mapping (SDC), and traffic light state recognition. Our approach employs the Convolutional vision Transformer (CvT) \cite{wu2021cvt} to better extract and fuse features from multiple RGB cameras due to local and global feature extraction capability of convolution and transformer modules, respectively. Following this, the control module undertakes the decoding of the encoded characteristics together with supplementary data, comprising a rough simulator for static and dynamic environments, as well as various measurements, in order to anticipate the waypoints associated with a latent feature space. We use two methods to process these outputs and generate the vehicular controls (e.g. steering, throttle, and brake) levels. The first method uses a PID algorithm to follow the waypoints on the fly, whereas the second one directly predicts the control policy using the measurement features and environmental state. We evaluate the model and conduct a comparative analysis with recent models on the CARLA simulator using various scenarios, ranging from normal to adversarial conditions, to simulate real-world scenarios. Our code is available at \url{https://github.com/pagand/e2etransfuser/tree/cvpr-w} to facilitate future studies.
STPOTR: Simultaneous Human Trajectory and Pose Prediction Using a Non-Autoregressive Transformer for Robot Following Ahead
Sep 27, 2022
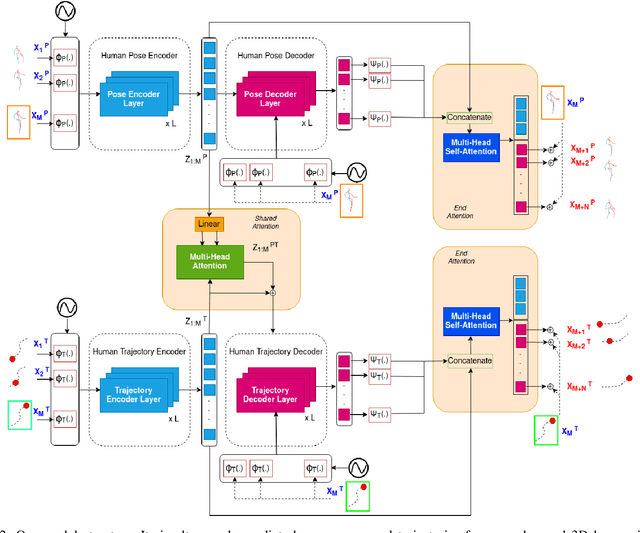


In this paper, we develop a neural network model to predict future human motion from an observed human motion history. We propose a non-autoregressive transformer architecture to leverage its parallel nature for easier training and fast, accurate predictions at test time. The proposed architecture divides human motion prediction into two parts: 1) the human trajectory, which is the hip joint 3D position over time and 2) the human pose which is the all other joints 3D positions over time with respect to a fixed hip joint. We propose to make the two predictions simultaneously, as the shared representation can improve the model performance. Therefore, the model consists of two sets of encoders and decoders. First, a multi-head attention module applied to encoder outputs improves human trajectory. Second, another multi-head self-attention module applied to encoder outputs concatenated with decoder outputs facilitates learning of temporal dependencies. Our model is well-suited for robotic applications in terms of test accuracy and speed, and compares favorably with respect to state-of-the-art methods. We demonstrate the real-world applicability of our work via the Robot Follow-Ahead task, a challenging yet practical case study for our proposed model.
DMMGAN: Diverse Multi Motion Prediction of 3D Human Joints using Attention-Based Generative Adverserial Network
Sep 13, 2022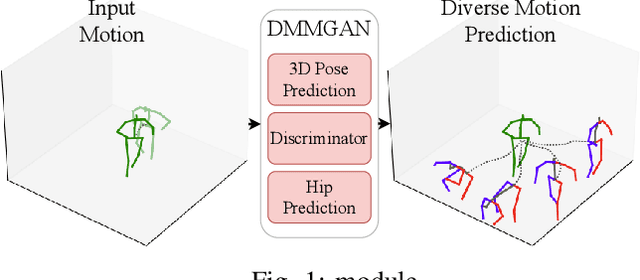
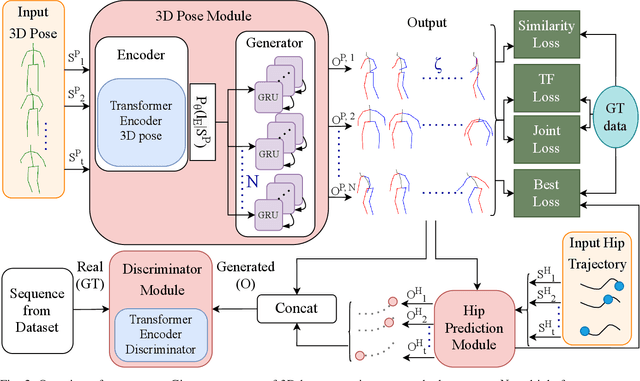
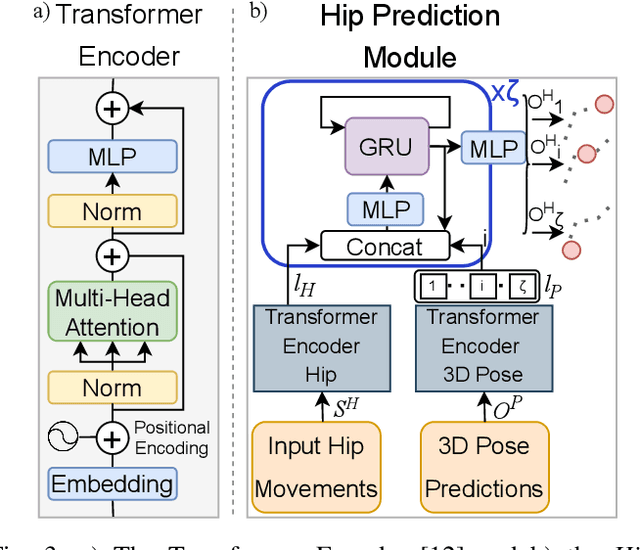
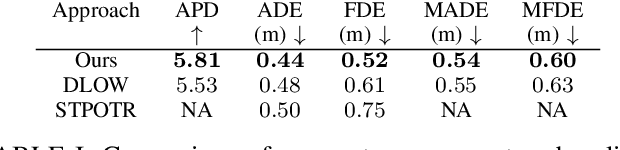
Human motion prediction is a fundamental part of many human-robot applications. Despite the recent progress in human motion prediction, most studies simplify the problem by predicting the human motion relative to a fixed joint and/or only limit their model to predict one possible future motion. While due to the complex nature of human motion, a single output cannot reflect all the possible actions one can do. Also, for any robotics application, we need the full human motion including the user trajectory not a 3d pose relative to the hip joint. In this paper, we try to address these two issues by proposing a transformer-based generative model for forecasting multiple diverse human motions. Our model generates \textit{N} future possible motion by querying a history of human motion. Our model first predicts the pose of the body relative to the hip joint. Then the \textit{Hip Prediction Module} predicts the trajectory of the hip movement for each predicted pose frame. To emphasize on the diverse future motions we introduce a similarity loss that penalizes the pairwise sample distance. We show that our system outperforms the state-of-the-art in human motion prediction while it can predict diverse multi-motion future trajectories with hip movements
Robust Visual Teach and Repeat for UGVs Using 3D Semantic Maps
Sep 21, 2021
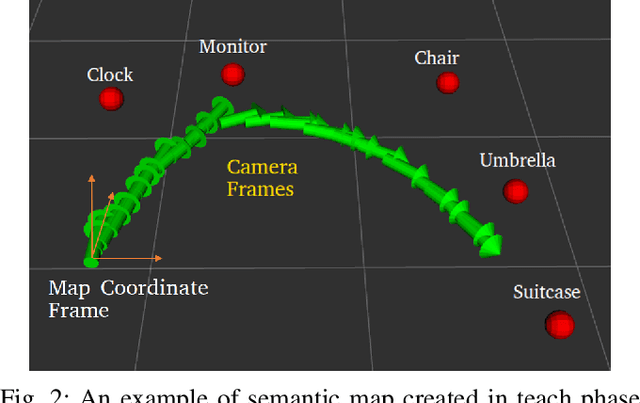

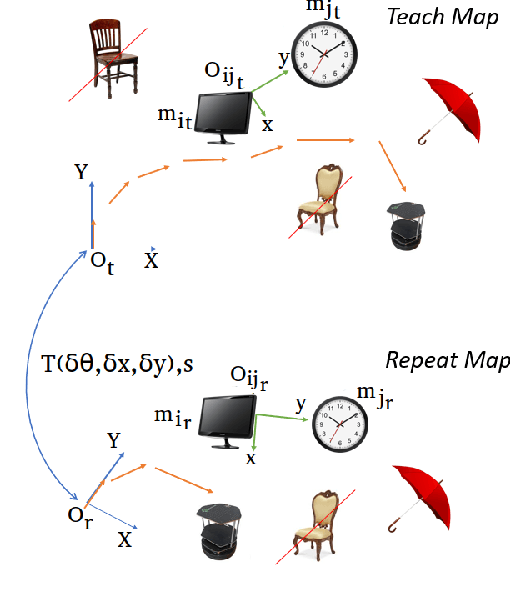
In this paper, we propose a Visual Teach and Repeat (VTR) algorithm using semantic landmarks extracted from environmental objects for ground robots with fixed mount monocular cameras. The proposed algorithm is robust to changes in the starting pose of the camera/robot, where a pose is defined as the planar position plus the orientation around the vertical axis. VTR consists of a teach phase in which a robot moves in a prescribed path, and a repeat phase in which the robot tries to repeat the same path starting from the same or a different pose. Most available VTR algorithms are pose dependent and cannot perform well in the repeat phase when starting from an initial pose far from that of the teach phase. To achieve more robust pose independency, during the teach phase, we collect the camera poses and the 3D point clouds of the environment using ORB-SLAM. We also detect objects in the environment using YOLOv3. We then combine the two outputs to build a 3D semantic map of the environment consisting of the 3D position of the objects and the robot path. In the repeat phase, we relocalize the robot based on the detected objects and the stored semantic map. The robot is then able to move toward the teach path, and repeat it in both forward and backward directions. The results show that our algorithm is highly robust with respect to pose variations as well as environmental alterations. Our code and data are available at the following Github page: https://github.com/mmahdavian/semantic_visual_teach_repeat