 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoVieDrive: Multi-Modal Multi-View Urban Scene Video Generation
Paper and Code
Aug 20, 2025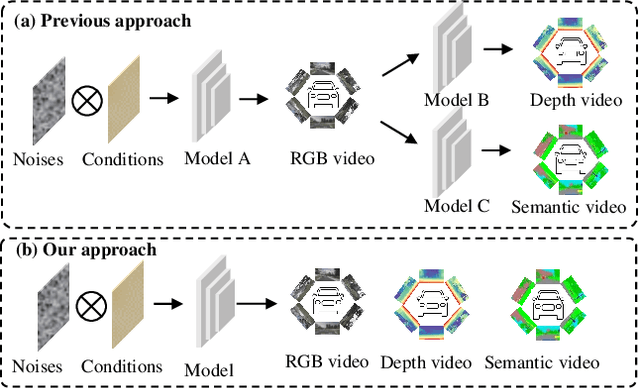
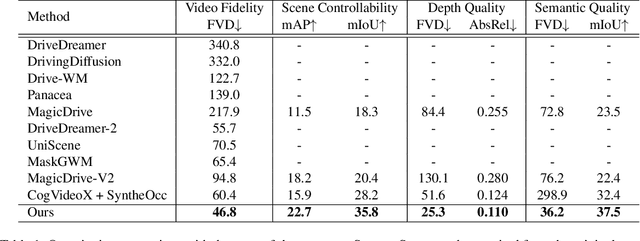
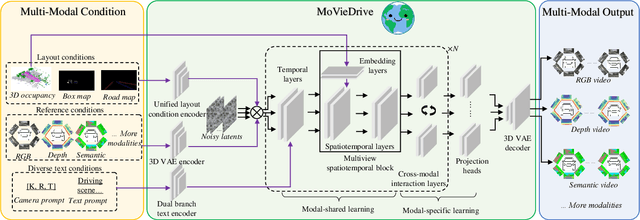
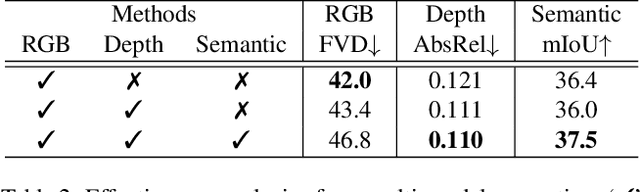
Video generation has recently shown superiority in urban scene synthesis for autonomous driving. Existing video generation approaches to autonomous driving primarily focus on RGB video generation and lack the ability to support multi-modal video generation. However, multi-modal data, such as depth maps and semantic maps, are crucial for holistic urban scene understanding in autonomous driving. Although it is feasible to use multiple models to generate different modalities, this increases the difficulty of model deployment and does not leverage complementary cues for multi-modal data generation. To address this problem, in this work, we propose a novel multi-modal multi-view video generation approach to autonomous driving. Specifically, we construct a unified diffusion transformer model composed of modal-shared components and modal-specific components. Then, we leverage diverse conditioning inputs to encode controllable scene structure and content cues into the unified diffusion model for multi-modal multi-view video generation. In this way, our approach is capable of generating multi-modal multi-view driving scene videos in a unified framework. Our experiments on the challenging real-world autonomous driving dataset, nuScenes, show that our approach can generate multi-modal multi-view urban scene videos with high fidelity and controllability, surpassing the state-of-the-art methods.