 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Multi-Object Tracking with Unsupervised Re-Identification Learning and Occlusion Estimation
Jan 04, 2022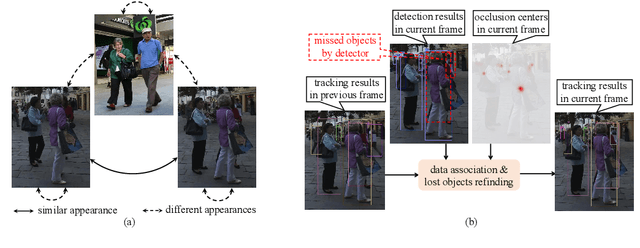

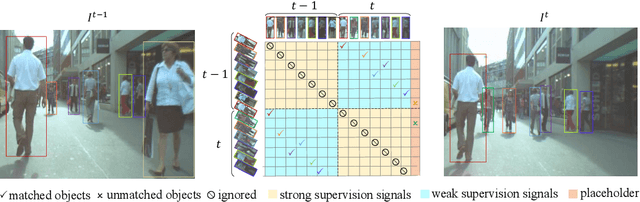

Occlusion between different objects is a typical challenge in Multi-Object Tracking (MOT), which often leads to inferior tracking results due to the missing detected objects. The common practice in multi-object tracking is re-identifying the missed objects after their reappearance. Though tracking performance can be boosted by the re-identification, the annotation of identity is required to train the model. In addition, such practice of re-identification still can not track those highly occluded objects when they are missed by the detector. In this paper, we focus on online multi-object tracking and design two novel modules, the unsupervised re-identification learning module and the occlusion estimation module, to handle these problems. Specifically, the proposed unsupervised re-identification learning module does not require any (pseudo) identity information nor suffer from the scalability issue. The proposed occlusion estimation module tries to predict the locations where occlusions happen, which are used to estimate the positions of missed objects by the detector. Our study shows that, when applied to state-of-the-art MOT methods, the proposed unsupervised re-identification learning is comparable to supervised re-identification learning, and the tracking performance is further improved by the proposed occlusion estimation module.
Vector Quantized Diffusion Model for Text-to-Image Synthesis
Dec 20, 2021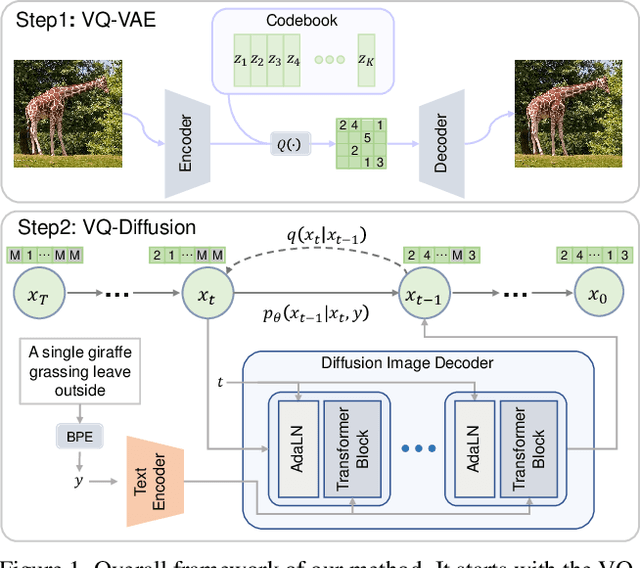
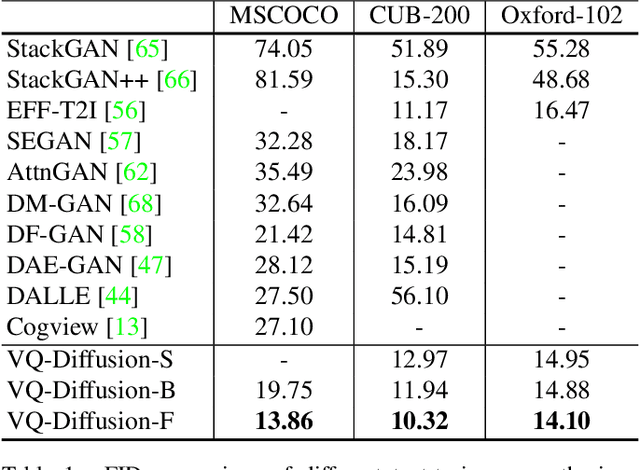

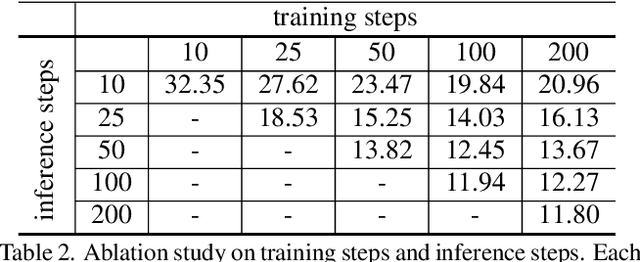
We present the vector quantized diffusion (VQ-Diffusion) model for text-to-image generation. This method is based on a vector quantized variational autoencoder (VQ-VAE) whose latent space is modeled by a conditional variant of the recently developed Denoising Diffusion Probabilistic Model (DDPM). We find that this latent-space method is well-suited for text-to-image generation tasks because it not only eliminates the unidirectional bias with existing methods but also allows us to incorporate a mask-and-replace diffusion strategy to avoid the accumulation of errors, which is a serious problem with existing methods. Our experiments show that the VQ-Diffusion produces significantly better text-to-image generation results when compared with conventional autoregressive (AR) models with similar numbers of parameters. Compared with previous GAN-based text-to-image methods, our VQ-Diffusion can handle more complex scenes and improve the synthesized image quality by a large margin. Finally, we show that the image generation computation in our method can be made highly efficient by reparameterization. With traditional AR methods, the text-to-image generation time increases linearly with the output image resolution and hence is quite time consuming even for normal size images. The VQ-Diffusion allows us to achieve a better trade-off between quality and speed. Our experiments indicate that the VQ-Diffusion model with the reparameterization is fifteen times faster than traditional AR methods while achieving a better image quality.
3D Question Answering
Dec 15, 2021

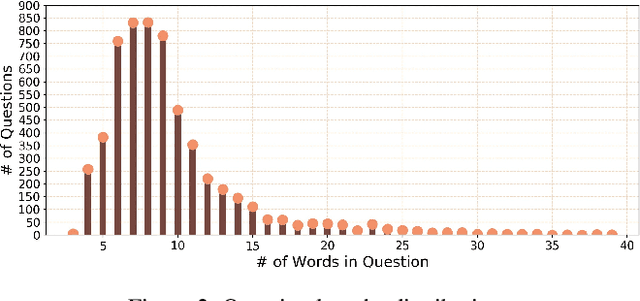

Visual Question Answering (VQA) has witnessed tremendous progress in recent years. However, most efforts only focus on the 2D image question answering tasks. In this paper, we present the first attempt at extending VQA to the 3D domain, which can facilitate artificial intelligence's perception of 3D real-world scenarios. Different from image based VQA, 3D Question Answering (3DQA) takes the color point cloud as input and requires both appearance and 3D geometry comprehension ability to answer the 3D-related questions. To this end, we propose a novel transformer-based 3DQA framework \textbf{``3DQA-TR"}, which consists of two encoders for exploiting the appearance and geometry information, respectively. The multi-modal information of appearance, geometry, and the linguistic question can finally attend to each other via a 3D-Linguistic Bert to predict the target answers. To verify the effectiveness of our proposed 3DQA framework, we further develop the first 3DQA dataset \textbf{``ScanQA"}, which builds on the ScanNet dataset and contains $\sim$6K questions, $\sim$30K answers for $806$ scenes. Extensive experiments on this dataset demonstrate the obvious superiority of our proposed 3DQA framework over existing VQA frameworks, and the effectiveness of our major designs. Our code and dataset will be made publicly available to facilitate the research in this direction.
HairCLIP: Design Your Hair by Text and Reference Image
Dec 09, 2021
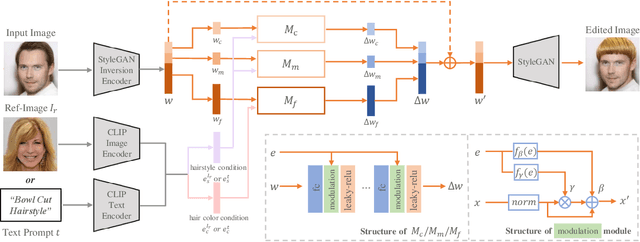
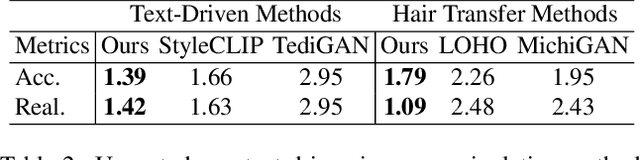

Hair editing is an interesting and challenging problem in computer vision and graphics. Many existing methods require well-drawn sketches or masks as conditional inputs for editing, however these interactions are neither straightforward nor efficient. In order to free users from the tedious interaction process, this paper proposes a new hair editing interaction mode, which enables manipulating hair attributes individually or jointly based on the texts or reference images provided by users. For this purpose, we encode the image and text conditions in a shared embedding space and propose a unified hair editing framework by leveraging the powerful image text representation capability of the Contrastive Language-Image Pre-Training (CLIP) model. With the carefully designed network structures and loss functions, our framework can perform high-quality hair editing in a disentangled manner. Extensive experiments demonstrate the superiority of our approach in terms of manipulation accuracy, visual realism of editing results, and irrelevant attribute preservation. Project repo is https://github.com/wty-ustc/HairCLIP.
CLIP-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fields
Dec 09, 2021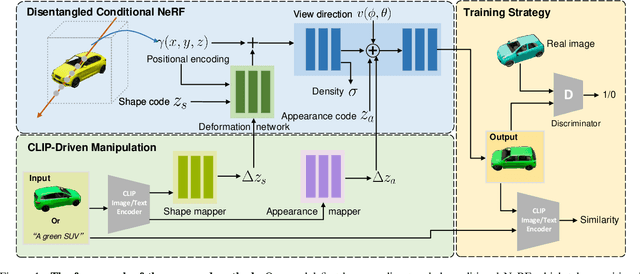
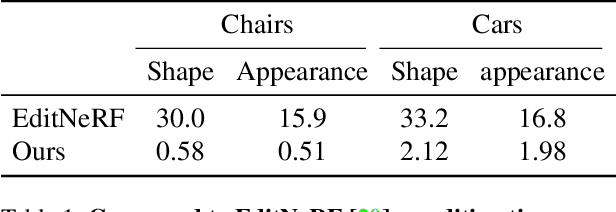
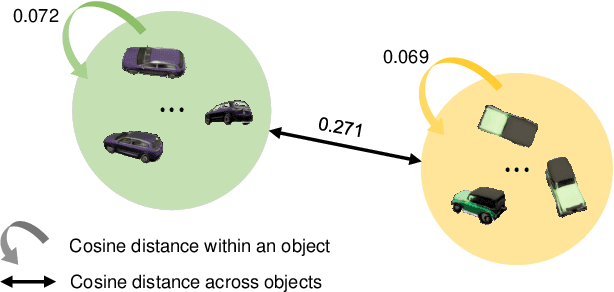
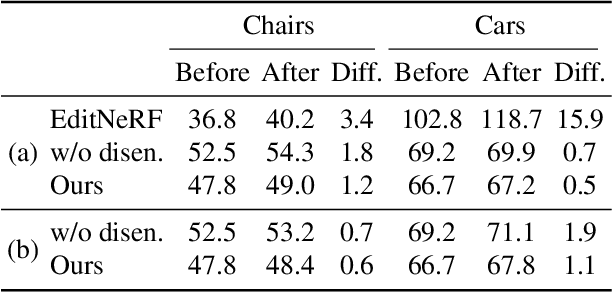
We present CLIP-NeRF, a multi-modal 3D object manipulation method for neural radiance fields (NeRF). By leveraging the joint language-image embedding space of the recent Contrastive Language-Image Pre-Training (CLIP) model, we propose a unified framework that allows manipulating NeRF in a user-friendly way, using either a short text prompt or an exemplar image. Specifically, to combine the novel view synthesis capability of NeRF and the controllable manipulation ability of latent representations from generative models, we introduce a disentangled conditional NeRF architecture that allows individual control over both shape and appearance. This is achieved by performing the shape conditioning via applying a learned deformation field to the positional encoding and deferring color conditioning to the volumetric rendering stage. To bridge this disentangled latent representation to the CLIP embedding, we design two code mappers that take a CLIP embedding as input and update the latent codes to reflect the targeted editing. The mappers are trained with a CLIP-based matching loss to ensure the manipulation accuracy. Furthermore, we propose an inverse optimization method that accurately projects an input image to the latent codes for manipulation to enable editing on real images. We evaluate our approach by extensive experiments on a variety of text prompts and exemplar images and also provide an intuitive interface for interactive editing. Our implementation is available at https://cassiepython.github.io/clipnerf/
General Facial Representation Learning in a Visual-Linguistic Manner
Dec 06, 2021
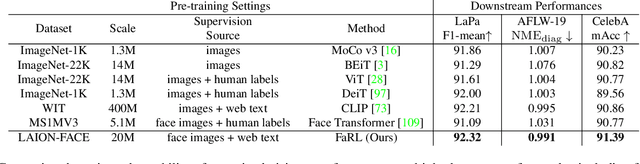
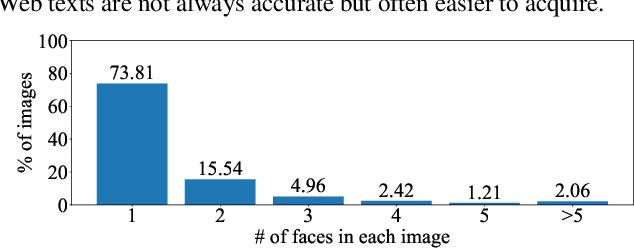

How to learn a universal facial representation that boosts all face analysis tasks? This paper takes one step toward this goal. In this paper, we study the transfer performance of pre-trained models on face analysis tasks and introduce a framework, called FaRL, for general Facial Representation Learning in a visual-linguistic manner. On one hand, the framework involves a contrastive loss to learn high-level semantic meaning from image-text pairs. On the other hand, we propose exploring low-level information simultaneously to further enhance the face representation, by adding a masked image modeling. We perform pre-training on LAION-FACE, a dataset containing large amount of face image-text pairs, and evaluate the representation capability on multiple downstream tasks. We show that FaRL achieves better transfer performance compared with previous pre-trained models. We also verify its superiority in the low-data regime. More importantly, our model surpasses the state-of-the-art methods on face analysis tasks including face parsing and face alignment.
BEVT: BERT Pretraining of Video Transformers
Dec 02, 2021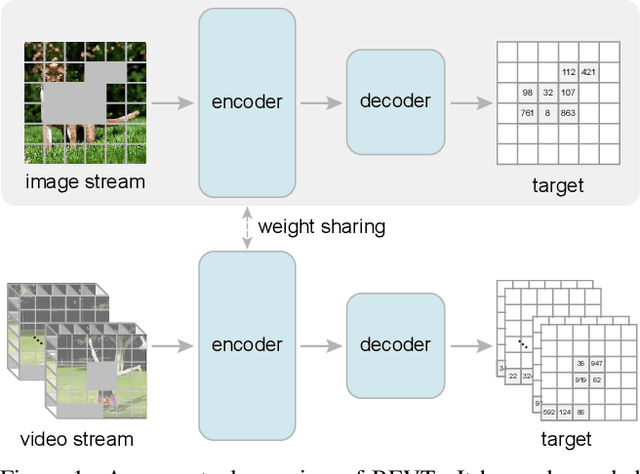
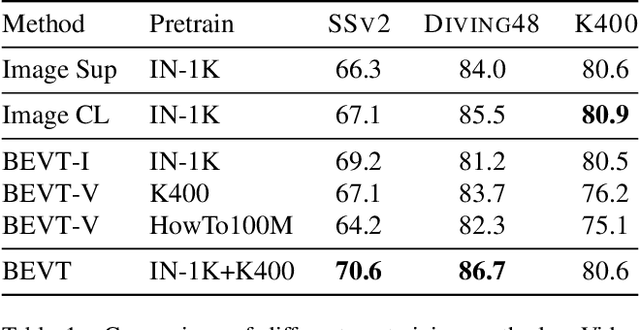
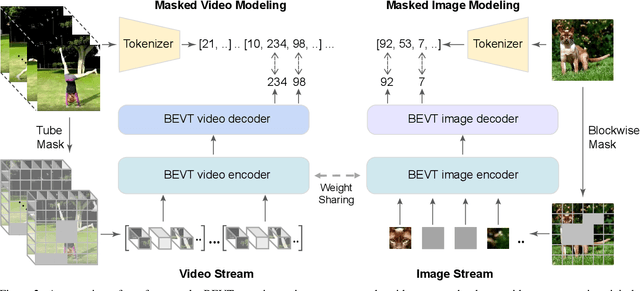

This paper studies the BERT pretraining of video transformers. It is a straightforward but worth-studying extension given the recent success from BERT pretraining of image transformers. We introduce BEVT which decouples video representation learning into spatial representation learning and temporal dynamics learning. In particular, BEVT first performs masked image modeling on image data, and then conducts masked image modeling jointly with masked video modeling on video data. This design is motivated by two observations: 1) transformers learned on image datasets provide decent spatial priors that can ease the learning of video transformers, which are often times computationally-intensive if trained from scratch; 2) discriminative clues, i.e., spatial and temporal information, needed to make correct predictions vary among different videos due to large intra-class and inter-class variations. We conduct extensive experiments on three challenging video benchmarks where BEVT achieves very promising results. On Kinetics 400, for which recognition mostly relies on discriminative spatial representations, BEVT achieves comparable results to strong supervised baselines. On Something-Something-V2 and Diving 48, which contain videos relying on temporal dynamics, BEVT outperforms by clear margins all alternative baselines and achieves state-of-the-art performance with a 70.6% and 86.7% Top-1 accuracy respectively.
Robust Equivariant Imaging: a fully unsupervised framework for learning to image from noisy and partial measurements
Nov 25, 2021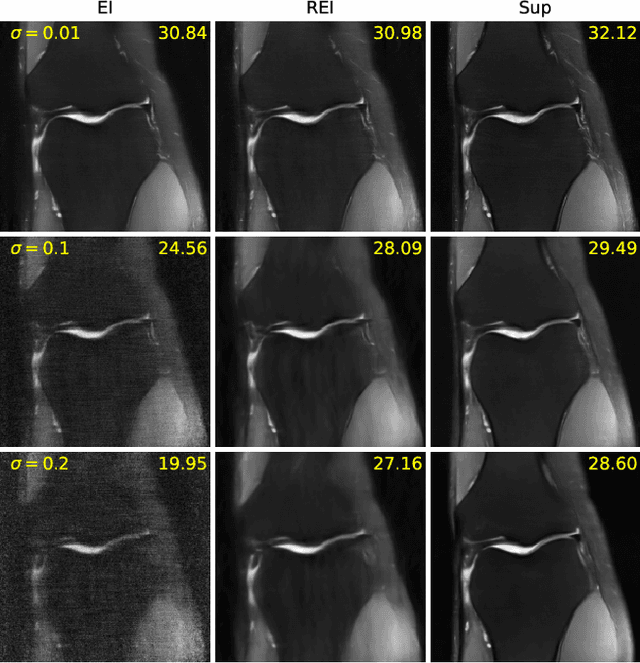
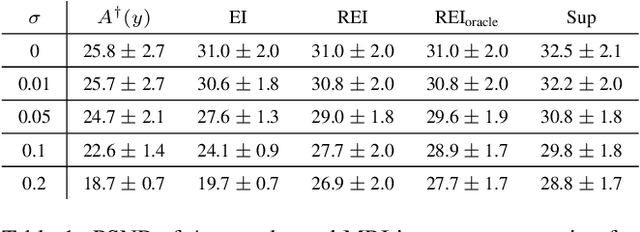
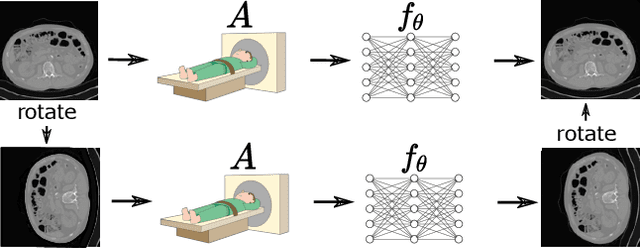
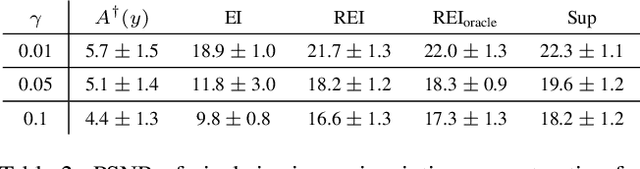
Deep networks provide state-of-the-art performance in multiple imaging inverse problems ranging from medical imaging to computational photography. However, most existing networks are trained with clean signals which are often hard or impossible to obtain. Equivariant imaging (EI) is a recent self-supervised learning framework that exploits the group invariance present in signal distributions to learn a reconstruction function from partial measurement data alone. While EI results are impressive, its performance degrades with increasing noise. In this paper, we propose a Robust Equivariant Imaging (REI) framework which can learn to image from noisy partial measurements alone. The proposed method uses Stein's Unbiased Risk Estimator (SURE) to obtain a fully unsupervised training loss that is robust to noise. We show that REI leads to considerable performance gains on linear and nonlinear inverse problems, thereby paving the way for robust unsupervised imaging with deep networks. Code will be available at: https://github.com/edongdongchen/REI.
PeCo: Perceptual Codebook for BERT Pre-training of Vision Transformers
Nov 24, 2021
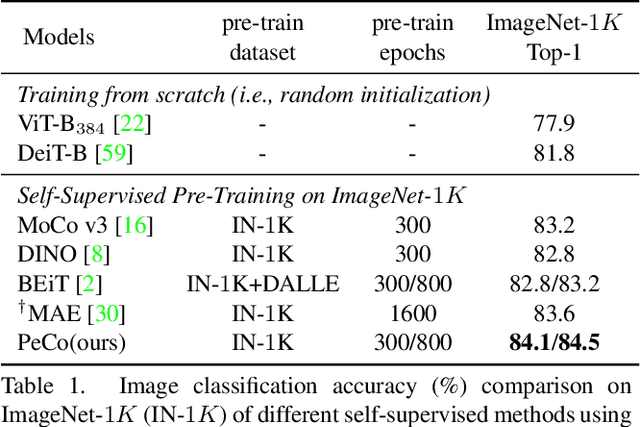
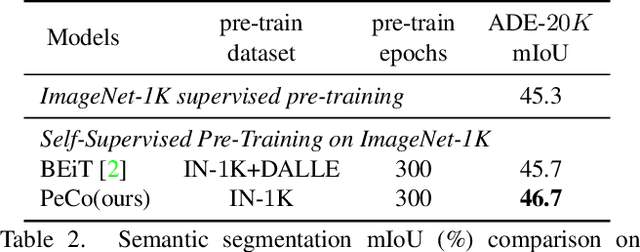

This paper explores a better codebook for BERT pre-training of vision transformers. The recent work BEiT successfully transfers BERT pre-training from NLP to the vision field. It directly adopts one simple discrete VAE as the visual tokenizer, but has not considered the semantic level of the resulting visual tokens. By contrast, the discrete tokens in NLP field are naturally highly semantic. This difference motivates us to learn a perceptual codebook. And we surprisingly find one simple yet effective idea: enforcing perceptual similarity during the dVAE training. We demonstrate that the visual tokens generated by the proposed perceptual codebook do exhibit better semantic meanings, and subsequently help pre-training achieve superior transfer performance in various downstream tasks. For example, we achieve 84.5 Top-1 accuracy on ImageNet-1K with ViT-B backbone, outperforming the competitive method BEiT by +1.3 with the same pre-training epochs. It can also improve the performance of object detection and segmentation tasks on COCO val by +1.3 box AP and +1.0 mask AP, semantic segmentation on ADE20k by +1.0 mIoU, The code and models will be available at \url{https://github.com/microsoft/PeCo}.
Florence: A New Foundation Model for Computer Vision
Nov 22, 2021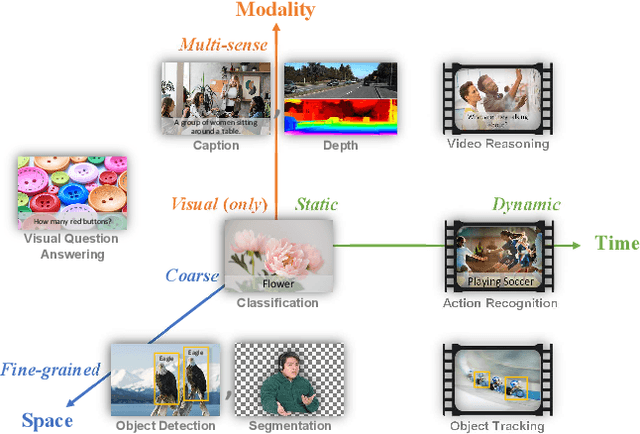
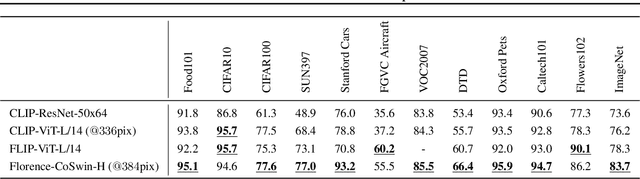
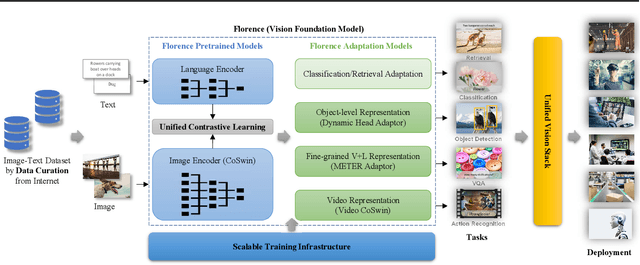
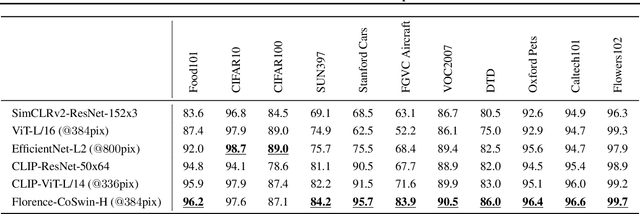
Automated visual understanding of our diverse and open world demands computer vision models to generalize well with minimal customization for specific tasks, similar to human vision. Computer vision foundation models, which are trained on diverse, large-scale dataset and can be adapted to a wide range of downstream tasks, are critical for this mission to solve real-world computer vision applications. While existing vision foundation models such as CLIP, ALIGN, and Wu Dao 2.0 focus mainly on mapping images and textual representations to a cross-modal shared representation, we introduce a new computer vision foundation model, Florence, to expand the representations from coarse (scene) to fine (object), from static (images) to dynamic (videos), and from RGB to multiple modalities (caption, depth). By incorporating universal visual-language representations from Web-scale image-text data, our Florence model can be easily adapted for various computer vision tasks, such as classification, retrieval, object detection, VQA, image caption, video retrieval and action recognition. Moreover, Florence demonstrates outstanding performance in many types of transfer learning: fully sampled fine-tuning, linear probing, few-shot transfer and zero-shot transfer for novel images and objects. All of these properties are critical for our vision foundation model to serve general purpose vision tasks. Florence achieves new state-of-the-art results in majority of 44 representative benchmarks, e.g., ImageNet-1K zero-shot classification with top-1 accuracy of 83.74 and the top-5 accuracy of 97.18, 62.4 mAP on COCO fine tuning, 80.36 on VQA, and 87.8 on Kinetics-600.