 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Repulsive Force Unit for Garment Collision Handling in Neural Networks
Jul 28, 2022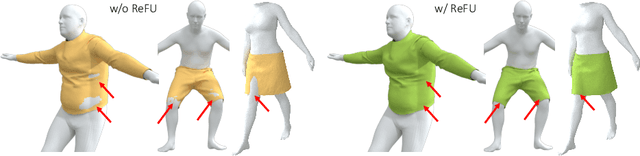
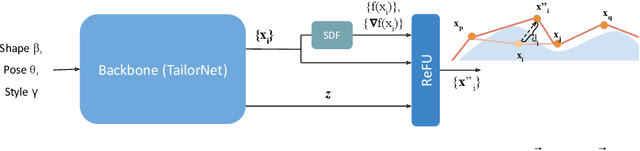
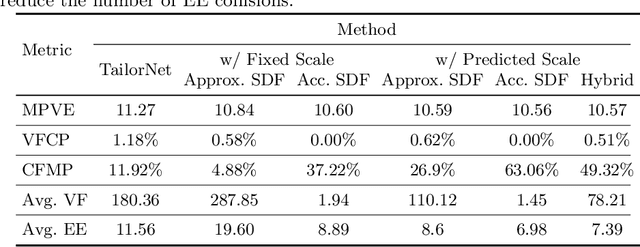
Despite recent success, deep learning-based methods for predicting 3D garment deformation under body motion suffer from interpenetration problems between the garment and the body. To address this problem, we propose a novel collision handling neural network layer called Repulsive Force Unit (ReFU). Based on the signed distance function (SDF) of the underlying body and the current garment vertex positions, ReFU predicts the per-vertex offsets that push any interpenetrating vertex to a collision-free configuration while preserving the fine geometric details. We show that ReFU is differentiable with trainable parameters and can be integrated into different network backbones that predict 3D garment deformations. Our experiments show that ReFU significantly reduces the number of collisions between the body and the garment and better preserves geometric details compared to prior methods based on collision loss or post-processing optimization.
Video Manipulations Beyond Faces: A Dataset with Human-Machine Analysis
Jul 27, 2022


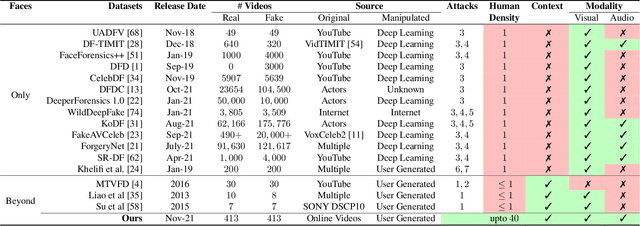
As tools for content editing mature, and artificial intelligence (AI) based algorithms for synthesizing media grow, the presence of manipulated content across online media is increasing. This phenomenon causes the spread of misinformation, creating a greater need to distinguish between "real" and "manipulated" content. To this end, we present VideoSham, a dataset consisting of 826 videos (413 real and 413 manipulated). Many of the existing deepfake datasets focus exclusively on two types of facial manipulations -- swapping with a different subject's face or altering the existing face. VideoSham, on the other hand, contains more diverse, context-rich, and human-centric, high-resolution videos manipulated using a combination of 6 different spatial and temporal attacks. Our analysis shows that state-of-the-art manipulation detection algorithms only work for a few specific attacks and do not scale well on VideoSham. We performed a user study on Amazon Mechanical Turk with 1200 participants to understand if they can differentiate between the real and manipulated videos in VideoSham. Finally, we dig deeper into the strengths and weaknesses of performances by humans and SOTA-algorithms to identify gaps that need to be filled with better AI algorithms.
Human Trajectory Prediction via Neural Social Physics
Jul 21, 2022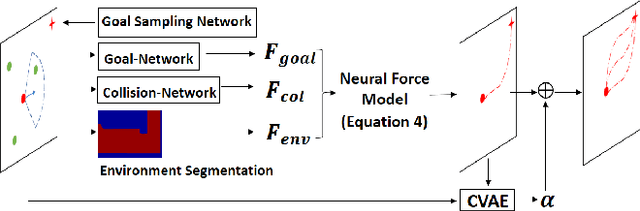
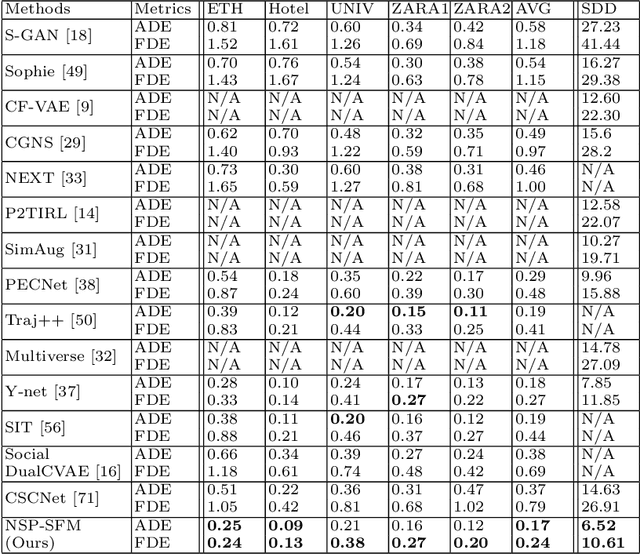
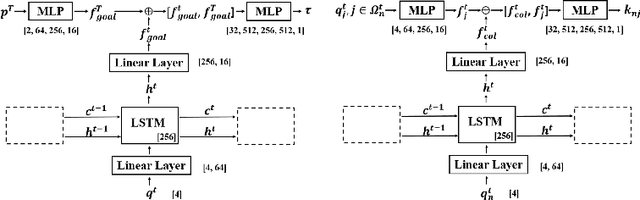
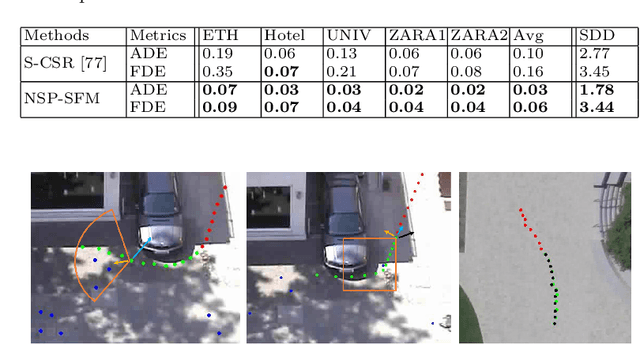
Trajectory prediction has been widely pursued in many fields, and many model-based and model-free methods have been explored. The former include rule-based, geometric or optimization-based models, and the latter are mainly comprised of deep learning approaches. In this paper, we propose a new method combining both methodologies based on a new Neural Differential Equation model. Our new model (Neural Social Physics or NSP) is a deep neural network within which we use an explicit physics model with learnable parameters. The explicit physics model serves as a strong inductive bias in modeling pedestrian behaviors, while the rest of the network provides a strong data-fitting capability in terms of system parameter estimation and dynamics stochasticity modeling. We compare NSP with 15 recent deep learning methods on 6 datasets and improve the state-of-the-art performance by 5.56%-70%. Besides, we show that NSP has better generalizability in predicting plausible trajectories in drastically different scenarios where the density is 2-5 times as high as the testing data. Finally, we show that the physics model in NSP can provide plausible explanations for pedestrian behaviors, as opposed to black-box deep learning. Code is available: https://github.com/realcrane/Human-Trajectory-Prediction-via-Neural-Social-Physics.
D2-TPred: Discontinuous Dependency for Trajectory Prediction under Traffic Lights
Jul 21, 2022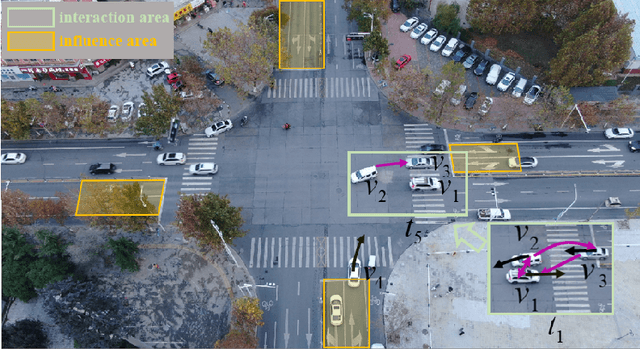
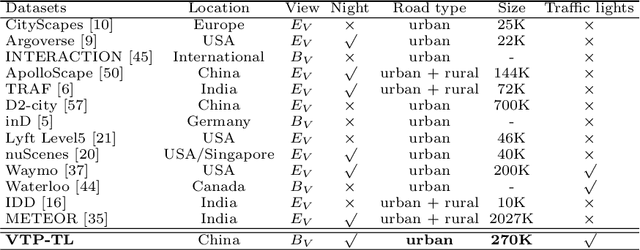
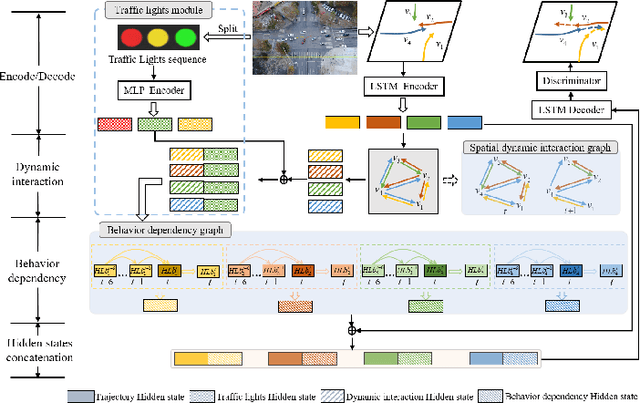
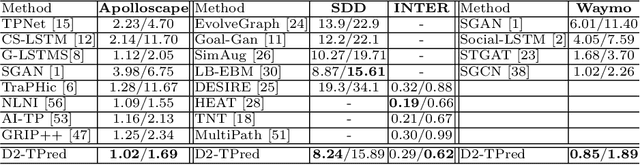
A profound understanding of inter-agent relationships and motion behaviors is important to achieve high-quality planning when navigating in complex scenarios, especially at urban traffic intersections. We present a trajectory prediction approach with respect to traffic lights, D2-TPred, which uses a spatial dynamic interaction graph (SDG) and a behavior dependency graph (BDG) to handle the problem of discontinuous dependency in the spatial-temporal space. Specifically, the SDG is used to capture spatial interactions by reconstructing sub-graphs for different agents with dynamic and changeable characteristics during each frame. The BDG is used to infer motion tendency by modeling the implicit dependency of the current state on priors behaviors, especially the discontinuous motions corresponding to acceleration, deceleration, or turning direction. Moreover, we present a new dataset for vehicle trajectory prediction under traffic lights called VTP-TL. Our experimental results show that our model achieves more than {20.45% and 20.78% }improvement in terms of ADE and FDE, respectively, on VTP-TL as compared to other trajectory prediction algorithms. The dataset and code are available at: https://github.com/VTP-TL/D2-TPred.
Show Me What I Like: Detecting User-Specific Video Highlights Using Content-Based Multi-Head Attention
Jul 19, 2022We propose a method to detect individualized highlights for users on given target videos based on their preferred highlight clips marked on previous videos they have watched. Our method explicitly leverages the contents of both the preferred clips and the target videos using pre-trained features for the objects and the human activities. We design a multi-head attention mechanism to adaptively weigh the preferred clips based on their object- and human-activity-based contents, and fuse them using these weights into a single feature representation for each user. We compute similarities between these per-user feature representations and the per-frame features computed from the desired target videos to estimate the user-specific highlight clips from the target videos. We test our method on a large-scale highlight detection dataset containing the annotated highlights of individual users. Compared to current baselines, we observe an absolute improvement of 2-4% in the mean average precision of the detected highlights. We also perform extensive ablation experiments on the number of preferred highlight clips associated with each user as well as on the object- and human-activity-based feature representations to validate that our method is indeed both content-based and user-specific.
* 14 pages, 5 figures, 7 tables
HTRON:Efficient Outdoor Navigation with Sparse Rewards via Heavy Tailed Adaptive Reinforce Algorithm
Jul 08, 2022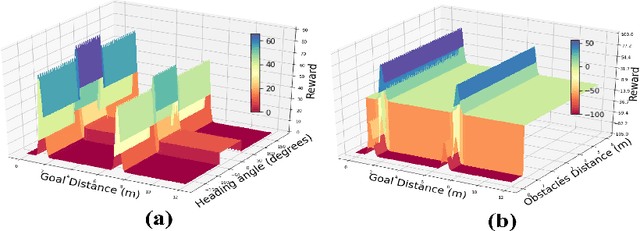
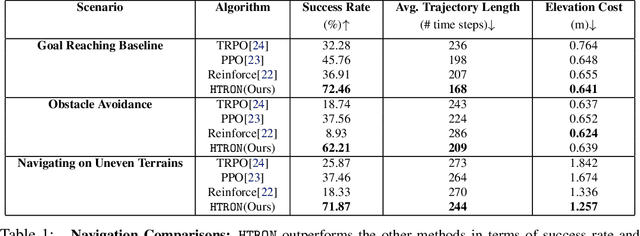
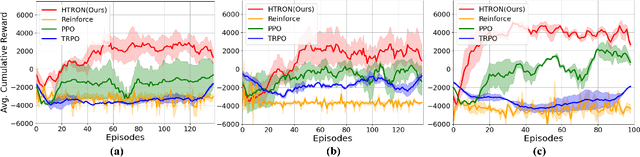
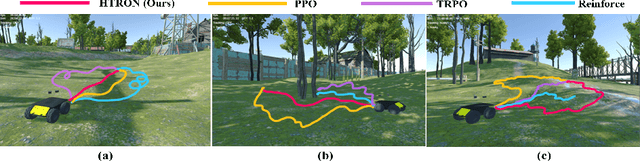
We present a novel approach to improve the performance of deep reinforcement learning (DRL) based outdoor robot navigation systems. Most, existing DRL methods are based on carefully designed dense reward functions that learn the efficient behavior in an environment. We circumvent this issue by working only with sparse rewards (which are easy to design), and propose a novel adaptive Heavy-Tailed Reinforce algorithm for Outdoor Navigation called HTRON. Our main idea is to utilize heavy-tailed policy parametrizations which implicitly induce exploration in sparse reward settings. We evaluate the performance of HTRON against Reinforce, PPO and TRPO algorithms in three different outdoor scenarios: goal-reaching, obstacle avoidance, and uneven terrain navigation. We observe in average an increase of 34.41% in terms of success rate, a 15.15% decrease in the average time steps taken to reach the goal, and a 24.9% decrease in the elevation cost compared to the navigation policies obtained by the other methods. Further, we demonstrate that our algorithm can be transferred directly into a Clearpath Husky robot to perform outdoor terrain navigation in real-world scenarios.
FedBC: Calibrating Global and Local Models via Federated Learning Beyond Consensus
Jun 26, 2022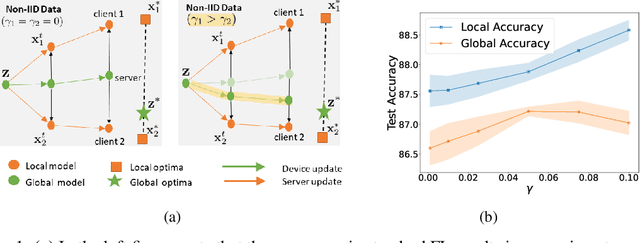
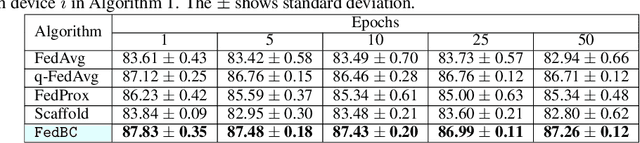
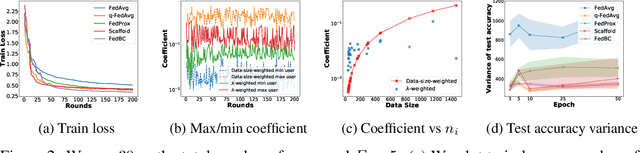
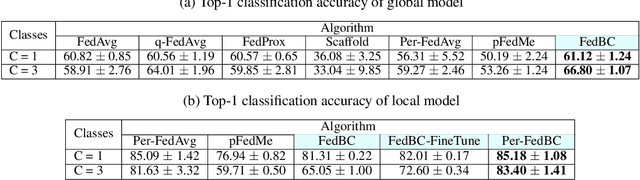
In federated learning (FL), the objective of collaboratively learning a global model through aggregation of model updates across devices tends to oppose the goal of personalization via local information. In this work, we calibrate this tradeoff in a quantitative manner through a multi-criterion optimization-based framework, which we cast as a constrained program: the objective for a device is its local objective, which it seeks to minimize while satisfying nonlinear constraints that quantify the proximity between the local and the global model. By considering the Lagrangian relaxation of this problem, we develop an algorithm that allows each node to minimize its local component of Lagrangian through queries to a first-order gradient oracle. Then, the server executes Lagrange multiplier ascent steps followed by a Lagrange multiplier-weighted averaging step. We call this instantiation of the primal-dual method Federated Learning Beyond Consensus ($\texttt{FedBC}$). Theoretically, we establish that $\texttt{FedBC}$ converges to a first-order stationary point at rates that matches the state of the art, up to an additional error term that depends on the tolerance parameter that arises due to the proximity constraints. Overall, the analysis is a novel characterization of primal-dual methods applied to non-convex saddle point problems with nonlinear constraints. Finally, we demonstrate that $\texttt{FedBC}$ balances the global and local model test accuracy metrics across a suite of datasets (Synthetic, MNIST, CIFAR-10, Shakespeare), achieving competitive performance with the state of the art.
Dealing with Sparse Rewards in Continuous Control Robotics via Heavy-Tailed Policies
Jun 12, 2022
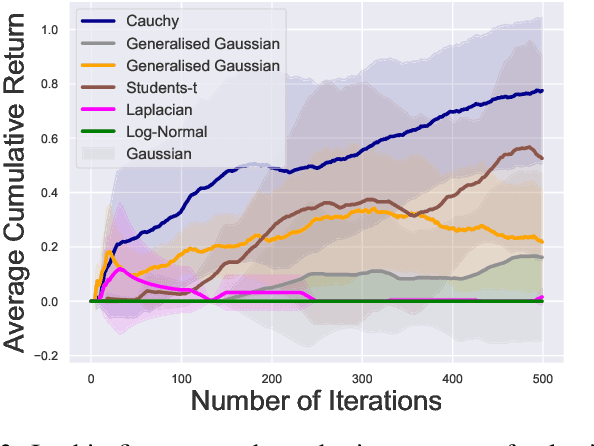
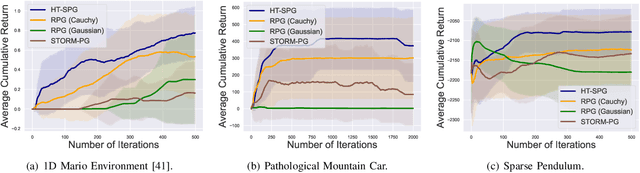
In this paper, we present a novel Heavy-Tailed Stochastic Policy Gradient (HT-PSG) algorithm to deal with the challenges of sparse rewards in continuous control problems. Sparse reward is common in continuous control robotics tasks such as manipulation and navigation, and makes the learning problem hard due to non-trivial estimation of value functions over the state space. This demands either reward shaping or expert demonstrations for the sparse reward environment. However, obtaining high-quality demonstrations is quite expensive and sometimes even impossible. We propose a heavy-tailed policy parametrization along with a modified momentum-based policy gradient tracking scheme (HT-SPG) to induce a stable exploratory behavior to the algorithm. The proposed algorithm does not require access to expert demonstrations. We test the performance of HT-SPG on various benchmark tasks of continuous control with sparse rewards such as 1D Mario, Pathological Mountain Car, Sparse Pendulum in OpenAI Gym, and Sparse MuJoCo environments (Hopper-v2). We show consistent performance improvement across all tasks in terms of high average cumulative reward. HT-SPG also demonstrates improved convergence speed with minimum samples, thereby emphasizing the sample efficiency of our proposed algorithm.
Posterior Coreset Construction with Kernelized Stein Discrepancy for Model-Based Reinforcement Learning
Jun 02, 2022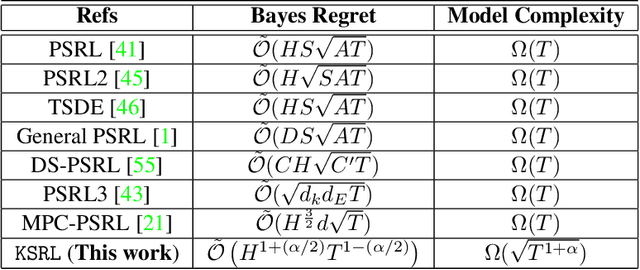
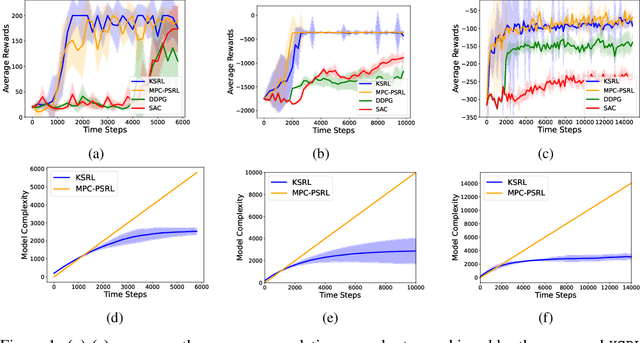
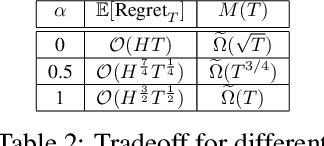
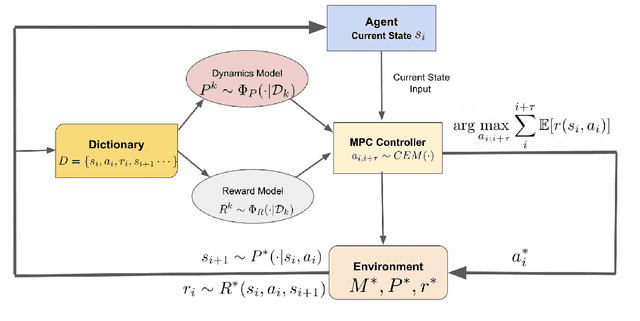
In this work, we propose a novel ${\bf K}$ernelized ${\bf S}$tein Discrepancy-based Posterior Sampling for ${\bf RL}$ algorithm (named $\texttt{KSRL}$) which extends model-based RL based upon posterior sampling (PSRL) in several ways: we (i) relax the need for any smoothness or Gaussian assumptions, allowing for complex mixture models; (ii) ensure it is applicable to large-scale training by incorporating a compression step such that the posterior consists of a \emph{Bayesian coreset} of only statistically significant past state-action pairs; and (iii) develop a novel regret analysis of PSRL based upon integral probability metrics, which, under a smoothness condition on the constructed posterior, can be evaluated in closed form as the kernelized Stein discrepancy (KSD). Consequently, we are able to improve the $\mathcal{O}(H^{3/2}d\sqrt{T})$ {regret} of PSRL to $\mathcal{O}(H^{3/2}\sqrt{T})$, where $d$ is the input dimension, $H$ is the episode length, and $T$ is the total number of episodes experienced, alleviating a linear dependence on $d$ . Moreover, we theoretically establish a trade-off between regret rate with posterior representational complexity via introducing a compression budget parameter $\epsilon$ based on KSD, and establish a lower bound on the required complexity for consistency of the model. Experimentally, we observe that this approach is competitive with several state of the art RL methodologies, with substantive improvements in computation time. Experimentally, we observe that this approach is competitive with several state of the art RL methodologies, and can achieve up-to $50\%$ reduction in wall clock time in some continuous control environments.
DistillAdapt: Source-Free Active Visual Domain Adaptation
May 24, 2022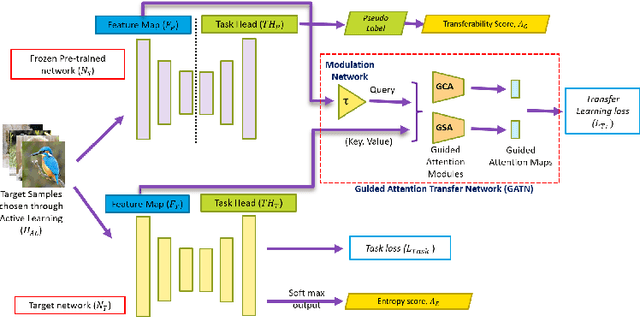

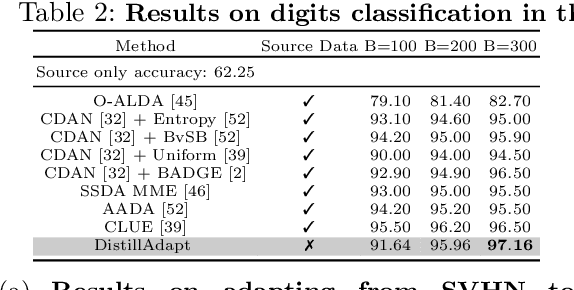
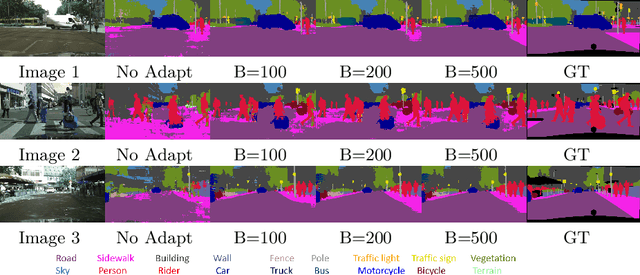
We present a novel method, DistillAdapt, for the challenging problem of Source-Free Active Domain Adaptation (SF-ADA). The problem requires adapting a pretrained source domain network to a target domain, within a provided budget for acquiring labels in the target domain, while assuming that the source data is not available for adaptation due to privacy concerns or otherwise. DistillAdapt is one of the first approaches for SF-ADA, and holistically addresses the challenges of SF-ADA via a novel Guided Attention Transfer Network (GATN) and an active learning heuristic, H_AL. The GATN enables selective distillation of features from the pre-trained network to the target network using a small subset of annotated target samples mined by H_AL. H_AL acquires samples at batch-level and balances transfer-ability from the pre-trained network and uncertainty of the target network. DistillAdapt is task-agnostic, and can be applied across visual tasks such as classification, segmentation and detection. Moreover, DistillAdapt can handle shifts in output label space. We conduct experiments and extensive ablation studies across 3 visual tasks, viz. digits classification (MNIST, SVHN), synthetic (GTA5) to real (CityScapes) image segmentation, and document layout detection (PubLayNet to DSSE). We show that our source-free approach, DistillAdapt, results in an improvement of 0.5% - 31.3% (across datasets and tasks) over prior adaptation methods that assume access to large amounts of annotated source data for adaptation.