 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Dataset Distillation for Classification: Do Distilled Sets Outperform Coresets?
Jun 16, 2026Dataset distillation (DD) has emerged as a prominent approach in data centric machine learning, aiming to synthesize compact training sets for efficient training by compressing the information in large datasets into a small number of synthetic samples. However, DD methods are often evaluated under inconsistent evaluation protocols, ranging from standard ERM to single/multi-teacher supervision, making it difficult to isolate the effectiveness of distilled data from evaluation. Moreover, many prior methods claim that DD outperforms data pruning approaches such as coreset selection (CS), based on the assumption that restricting condensed datasets to subsets of real samples fundamentally limits their expressiveness. In this work, we critically evaluate DD methods through large-scale experiments using standardized datasets and evaluation protocols to assess their intrinsic effectiveness. We benchmark seven state-of-the-art (SOTA) DD methods on ImageNet-1K, ImageNet100, and ImageNette, using three widely adopted training protocols against three CS strategies. Our results show that while some DD methods fail to outperform even simple random subsets, the SOTA DD approaches are comparable to or worse than coresets on large-scale datasets and incur a substantially higher cost for construction. Beyond accuracy, we also evaluate the representativeness, diversity, and quality of condensed sets, and find that coresets consistently achieve better coverage of the original data distribution. These findings highlight the limited practical advantages of current DD methods and show that coresets remain competitive and are often a more computationally efficient alternative for data-centric learning.
A robust PPG foundation model using multimodal physiological supervision
Jun 05, 2026Photoplethysmography (PPG), a non-invasive measure of changes in blood volume, is widely used in both wearable devices and clinical settings. Recent PPG foundation models either use open-source ICU datasets with pretraining paradigms that require curated data and thus complicate generalization to field-like data, or use closed-source field-like PPG data. In contrast, we propose a PPG foundation model that does not require high-quality or field-like pretraining data, and instead leverages accompanying electrocardiogram and respiratory signals in ICU datasets to select contrastive samples during pretraining. Our approach allows the model to retain and learn from noisy PPG segments, improving robustness at inference. Our model, pretrained on 3x fewer subjects than existing state-of-the-art approaches, achieves performance improvements on 14 out of 15 diverse downstream tasks, including field-like daily activity and heart rate prediction. Our results demonstrate that multimodal supervision can integrate complementary physiological information to improve the robustness of PPG foundation models and enhance their generalization to consumer-grade data.
MCAD: Multimodal Context-Aware Audio Description Generation For Soccer
Nov 12, 2025Audio Descriptions (AD) are essential for making visual content accessible to individuals with visual impairments. Recent works have shown a promising step towards automating AD, but they have been limited to describing high-quality movie content using human-annotated ground truth AD in the process. In this work, we present an end-to-end pipeline, MCAD, that extends AD generation beyond movies to the domain of sports, with a focus on soccer games, without relying on ground truth AD. To address the absence of domain-specific AD datasets, we fine-tune a Video Large Language Model on publicly available movie AD datasets so that it learns the narrative structure and conventions of AD. During inference, MCAD incorporates multimodal contextual cues such as player identities, soccer events and actions, and commentary from the game. These cues, combined with input prompts to the fine-tuned VideoLLM, allow the system to produce complete AD text for each video segment. We further introduce a new evaluation metric, ARGE-AD, designed to accurately assess the quality of generated AD. ARGE-AD evaluates the generated AD for the presence of five characteristics: (i) usage of people's names, (ii) mention of actions and events, (iii) appropriate length of AD, (iv) absence of pronouns, and (v) overlap from commentary or subtitles. We present an in-depth analysis of our approach on both movie and soccer datasets. We also validate the use of this metric to quantitatively comment on the quality of generated AD using our metric across domains. Additionally, we contribute audio descriptions for 100 soccer game clips annotated by two AD experts.
Model-agnostic Coreset Selection via LLM-based Concept Bottlenecks
Feb 23, 2025



Coreset Selection (CS) identifies a subset of training data that achieves model performance comparable to using the entire dataset. Many state-of-the-art CS methods, select coresets using scores whose computation requires training the downstream model on the entire dataset and recording changes in its behavior on samples as it trains (training dynamics). These scores are inefficient to compute and hard to interpret as they do not indicate whether a sample is difficult to learn in general or only for a specific model. Our work addresses these challenges by proposing an interpretable score that gauges a sample's difficulty using human-understandable textual attributes (concepts) independent of any downstream model. Specifically, we measure the alignment between a sample's visual features and concept bottlenecks, derived via large language models, by training a linear concept bottleneck layer and compute the sample's difficulty score using it. We then use this score and a stratified sampling strategy to identify the coreset. Crucially, our score is efficiently computable without training the downstream model on the full dataset even once, leads to high-performing coresets for various downstream models, and is computable even for an unlabeled dataset. Through experiments on CIFAR-10, CIFAR-100, and ImageNet-1K, we show our coresets outperform random subsets, even at high pruning rates, and achieve model performance comparable to or better than coresets found by training dynamics-based methods.
Naturalistic Head Motion Generation from Speech
Oct 26, 2022



Synthesizing natural head motion to accompany speech for an embodied conversational agent is necessary for providing a rich interactive experience. Most prior works assess the quality of generated head motion by comparing them against a single ground-truth using an objective metric. Yet there are many plausible head motion sequences to accompany a speech utterance. In this work, we study the variation in the perceptual quality of head motions sampled from a generative model. We show that, despite providing more diverse head motions, the generative model produces motions with varying degrees of perceptual quality. We finally show that objective metrics commonly used in previous research do not accurately reflect the perceptual quality of generated head motions. These results open an interesting avenue for future work to investigate better objective metrics that correlate with human perception of quality.
Video Manipulations Beyond Faces: A Dataset with Human-Machine Analysis
Jul 27, 2022


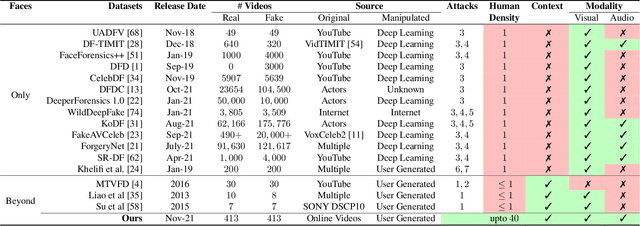
As tools for content editing mature, and artificial intelligence (AI) based algorithms for synthesizing media grow, the presence of manipulated content across online media is increasing. This phenomenon causes the spread of misinformation, creating a greater need to distinguish between "real" and "manipulated" content. To this end, we present VideoSham, a dataset consisting of 826 videos (413 real and 413 manipulated). Many of the existing deepfake datasets focus exclusively on two types of facial manipulations -- swapping with a different subject's face or altering the existing face. VideoSham, on the other hand, contains more diverse, context-rich, and human-centric, high-resolution videos manipulated using a combination of 6 different spatial and temporal attacks. Our analysis shows that state-of-the-art manipulation detection algorithms only work for a few specific attacks and do not scale well on VideoSham. We performed a user study on Amazon Mechanical Turk with 1200 participants to understand if they can differentiate between the real and manipulated videos in VideoSham. Finally, we dig deeper into the strengths and weaknesses of performances by humans and SOTA-algorithms to identify gaps that need to be filled with better AI algorithms.
3MASSIV: Multilingual, Multimodal and Multi-Aspect dataset of Social Media Short Videos
Mar 28, 2022
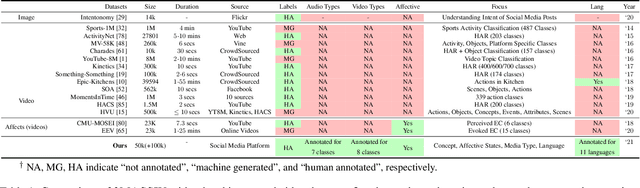

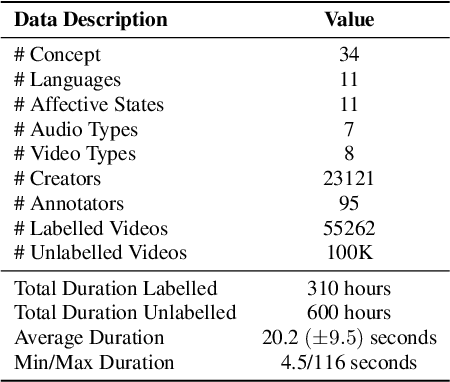
We present 3MASSIV, a multilingual, multimodal and multi-aspect, expertly-annotated dataset of diverse short videos extracted from short-video social media platform - Moj. 3MASSIV comprises of 50k short videos (20 seconds average duration) and 100K unlabeled videos in 11 different languages and captures popular short video trends like pranks, fails, romance, comedy expressed via unique audio-visual formats like self-shot videos, reaction videos, lip-synching, self-sung songs, etc. 3MASSIV presents an opportunity for multimodal and multilingual semantic understanding on these unique videos by annotating them for concepts, affective states, media types, and audio language. We present a thorough analysis of 3MASSIV and highlight the variety and unique aspects of our dataset compared to other contemporary popular datasets with strong baselines. We also show how the social media content in 3MASSIV is dynamic and temporal in nature, which can be used for semantic understanding tasks and cross-lingual analysis.
Affect2MM: Affective Analysis of Multimedia Content Using Emotion Causality
Mar 11, 2021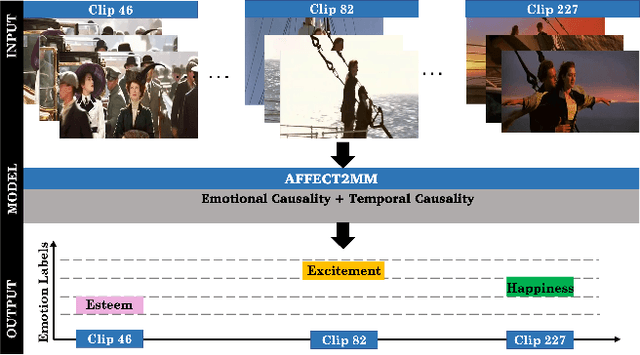

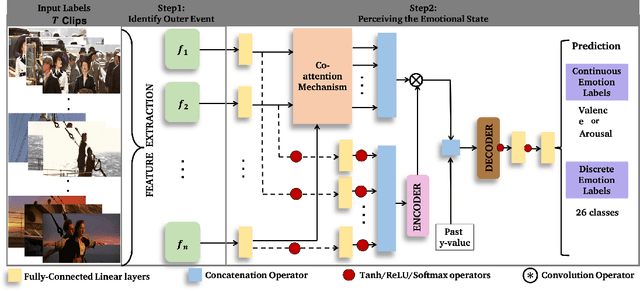
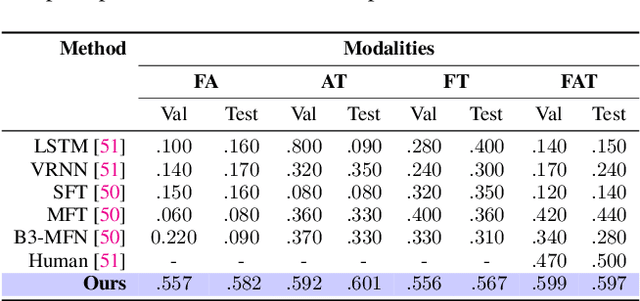
We present Affect2MM, a learning method for time-series emotion prediction for multimedia content. Our goal is to automatically capture the varying emotions depicted by characters in real-life human-centric situations and behaviors. We use the ideas from emotion causation theories to computationally model and determine the emotional state evoked in clips of movies. Affect2MM explicitly models the temporal causality using attention-based methods and Granger causality. We use a variety of components like facial features of actors involved, scene understanding, visual aesthetics, action/situation description, and movie script to obtain an affective-rich representation to understand and perceive the scene. We use an LSTM-based learning model for emotion perception. To evaluate our method, we analyze and compare our performance on three datasets, SENDv1, MovieGraphs, and the LIRIS-ACCEDE dataset, and observe an average of 10-15% increase in the performance over SOTA methods for all three datasets.
Dynamic Graph Modeling of Simultaneous EEG and Eye-tracking Data for Reading Task Identification
Feb 21, 2021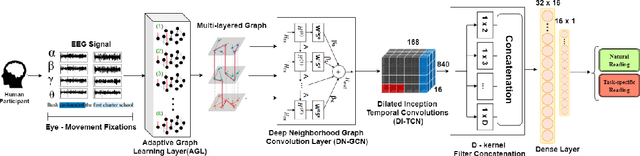
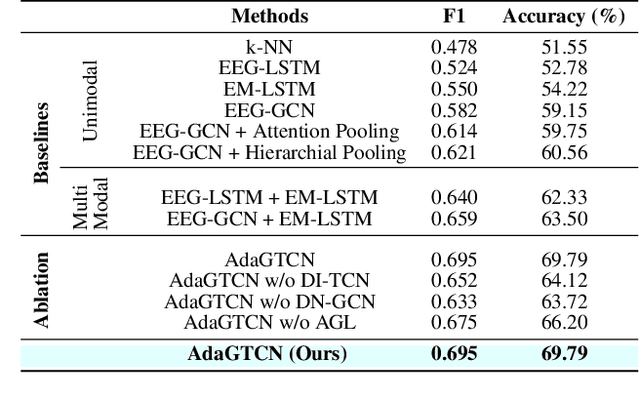
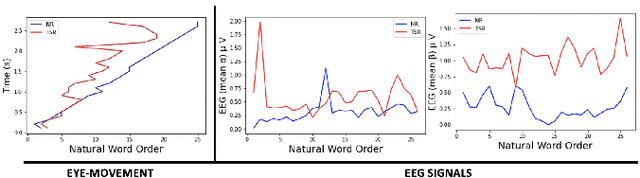
We present a new approach, that we call AdaGTCN, for identifying human reader intent from Electroencephalogram~(EEG) and Eye movement~(EM) data in order to help differentiate between normal reading and task-oriented reading. Understanding the physiological aspects of the reading process~(the cognitive load and the reading intent) can help improve the quality of crowd-sourced annotated data. Our method, Adaptive Graph Temporal Convolution Network (AdaGTCN), uses an Adaptive Graph Learning Layer and Deep Neighborhood Graph Convolution Layer for identifying the reading activities using time-locked EEG sequences recorded during word-level eye-movement fixations. Adaptive Graph Learning Layer dynamically learns the spatial correlations between the EEG electrode signals while the Deep Neighborhood Graph Convolution Layer exploits temporal features from a dense graph neighborhood to establish the state of the art in reading task identification over other contemporary approaches. We compare our approach with several baselines to report an improvement of 6.29% on the ZuCo 2.0 dataset, along with extensive ablation experiments
MCQA: Multimodal Co-attention Based Network for Question Answering
Apr 25, 2020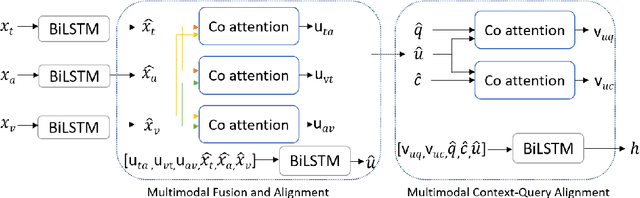
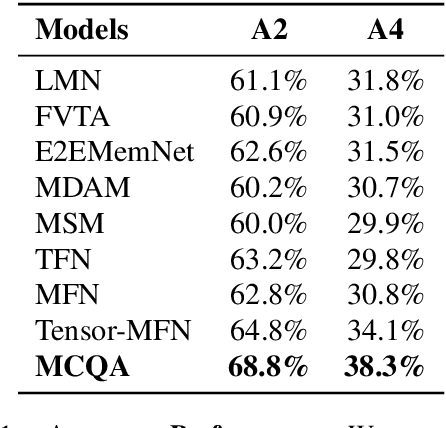


We present MCQA, a learning-based algorithm for multimodal question answering. MCQA explicitly fuses and aligns the multimodal input (i.e. text, audio, and video), which forms the context for the query (question and answer). Our approach fuses and aligns the question and the answer within this context. Moreover, we use the notion of co-attention to perform cross-modal alignment and multimodal context-query alignment. Our context-query alignment module matches the relevant parts of the multimodal context and the query with each other and aligns them to improve the overall performance. We evaluate the performance of MCQA on Social-IQ, a benchmark dataset for multimodal question answering. We compare the performance of our algorithm with prior methods and observe an accuracy improvement of 4-7%.