 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Vision-and-Language Navigation with Image-Text Pairs from the Web
May 01, 2020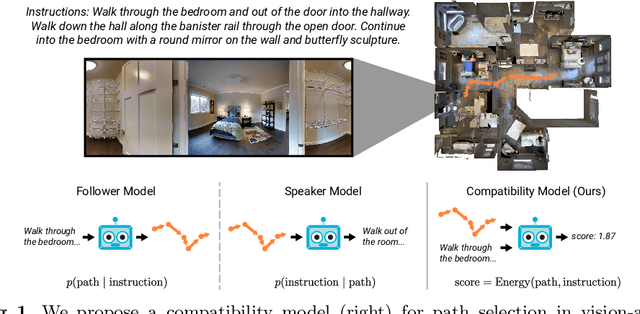
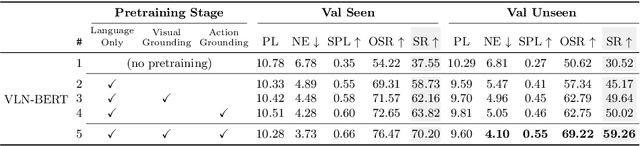

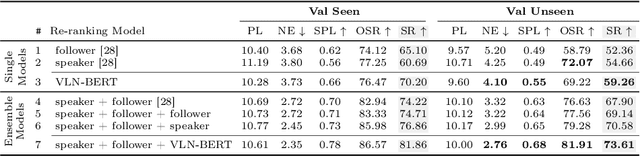
Following a navigation instruction such as 'Walk down the stairs and stop at the brown sofa' requires embodied AI agents to ground scene elements referenced via language (e.g. 'stairs') to visual content in the environment (pixels corresponding to 'stairs'). We ask the following question -- can we leverage abundant 'disembodied' web-scraped vision-and-language corpora (e.g. Conceptual Captions) to learn visual groundings (what do 'stairs' look like?) that improve performance on a relatively data-starved embodied perception task (Vision-and-Language Navigation)? Specifically, we develop VLN-BERT, a visiolinguistic transformer-based model for scoring the compatibility between an instruction ('...stop at the brown sofa') and a sequence of panoramic RGB images captured by the agent. We demonstrate that pretraining VLN-BERT on image-text pairs from the web before fine-tuning on embodied path-instruction data significantly improves performance on VLN -- outperforming the prior state-of-the-art in the fully-observed setting by 4 absolute percentage points on success rate. Ablations of our pretraining curriculum show each stage to be impactful -- with their combination resulting in further positive synergistic effects.
Beyond the Nav-Graph: Vision-and-Language Navigation in Continuous Environments
Apr 06, 2020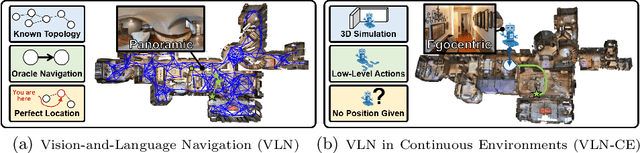


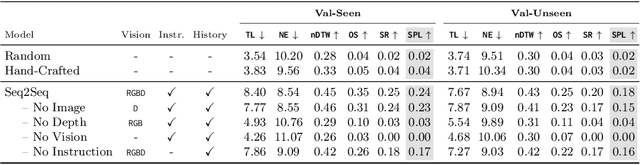
We develop a language-guided navigation task set in a continuous 3D environment where agents must execute low-level actions to follow natural language navigation directions. By being situated in continuous environments, this setting lifts a number of assumptions implicit in prior work that represents environments as a sparse graph of panoramas with edges corresponding to navigability. Specifically, our setting drops the presumptions of known environment topologies, short-range oracle navigation, and perfect agent localization. To contextualize this new task, we develop models that mirror many of the advances made in prior settings as well as single-modality baselines. While some of these techniques transfer, we find significantly lower absolute performance in the continuous setting -- suggesting that performance in prior `navigation-graph' settings may be inflated by the strong implicit assumptions.
Analyzing Visual Representations in Embodied Navigation Tasks
Mar 12, 2020
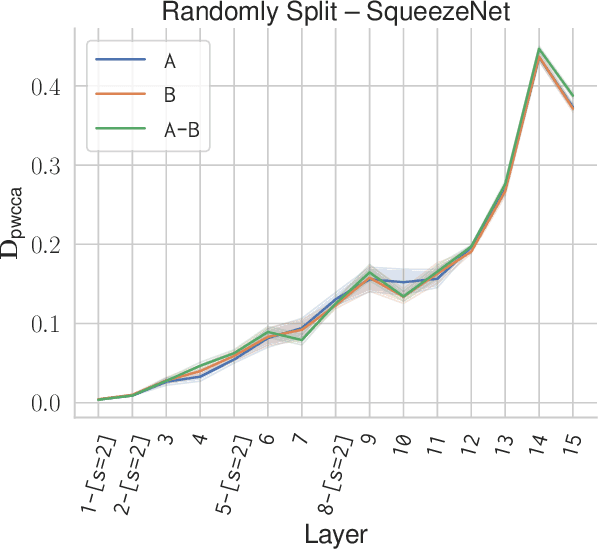
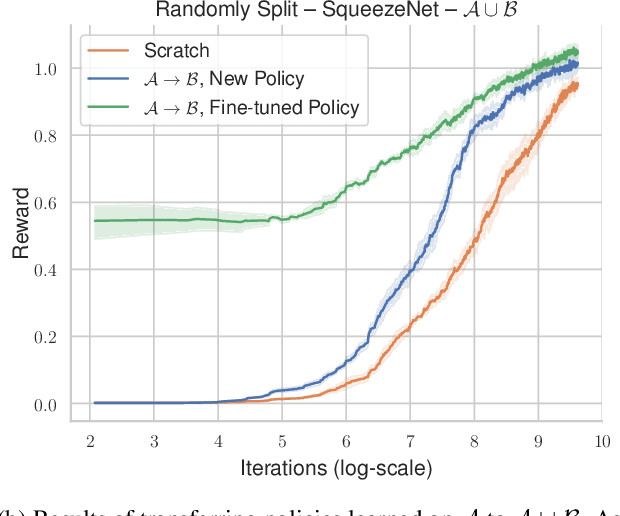
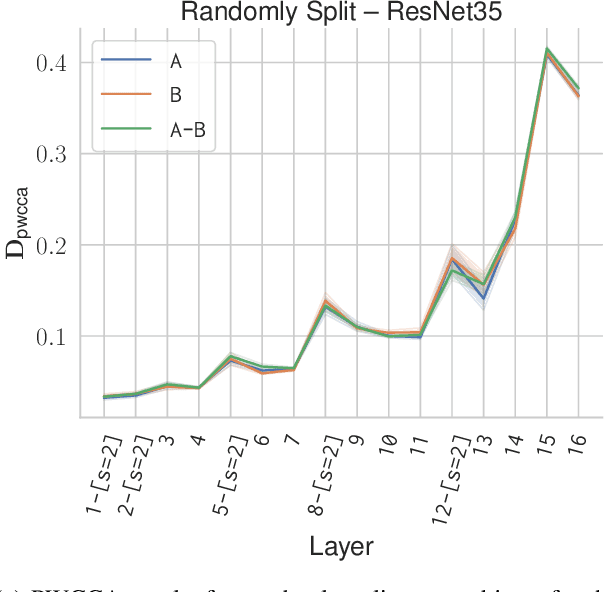
Recent advances in deep reinforcement learning require a large amount of training data and generally result in representations that are often over specialized to the target task. In this work, we present a methodology to study the underlying potential causes for this specialization. We use the recently proposed projection weighted Canonical Correlation Analysis (PWCCA) to measure the similarity of visual representations learned in the same environment by performing different tasks. We then leverage our proposed methodology to examine the task dependence of visual representations learned on related but distinct embodied navigation tasks. Surprisingly, we find that slight differences in task have no measurable effect on the visual representation for both SqueezeNet and ResNet architectures. We then empirically demonstrate that visual representations learned on one task can be effectively transferred to a different task.
Are We Making Real Progress in Simulated Environments? Measuring the Sim2Real Gap in Embodied Visual Navigation
Dec 13, 2019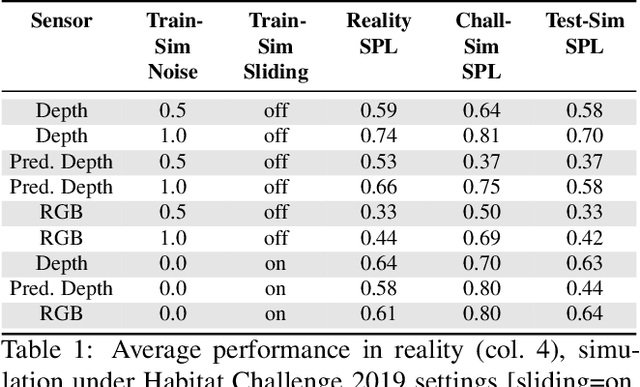

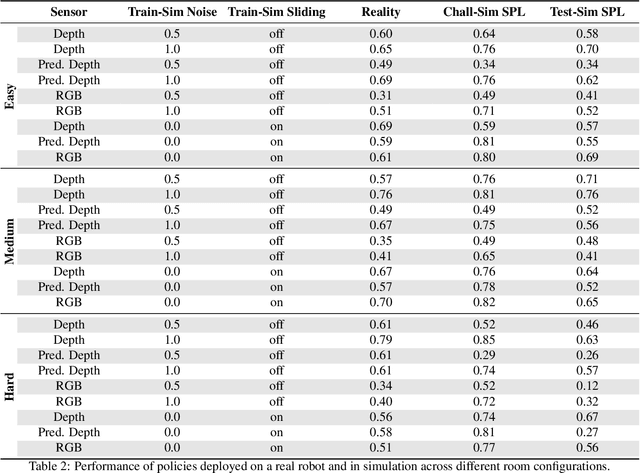

Does progress in simulation translate to progress in robotics? Specifically, if method A outperforms method B in simulation, how likely is the trend to hold in reality on a robot? We examine this question for embodied (PointGoal) navigation, developing engineering tools and a research paradigm for evaluating a simulator by its sim2real predictivity, revealing surprising findings about prior work. First, we develop Habitat-PyRobot Bridge (HaPy), a library for seamless execution of identical code on a simulated agent and a physical robot. Habitat-to-Locobot transfer with HaPy involves just one line change in config, essentially treating reality as just another simulator! Second, we investigate sim2real predictivity of Habitat-Sim for PointGoal navigation. We 3D-scan a physical lab space to create a virtualized replica, and run parallel tests of 9 different models in reality and simulation. We present a new metric called Sim-vs-Real Correlation Coefficient (SRCC) to quantify sim2real predictivity. Our analysis reveals several important findings. We find that SRCC for Habitat as used for the CVPR19 challenge is low (0.18 for the success metric), which suggests that performance improvements for this simulator-based challenge would not transfer well to a physical robot. We find that this gap is largely due to AI agents learning to 'cheat' by exploiting simulator imperfections: specifically, the way Habitat allows for 'sliding' along walls on collision. Essentially, the virtual robot is capable of cutting corners, leading to unrealistic shortcuts through non-navigable spaces. Naturally, such exploits do not work in the real world where the robot stops on contact with walls. Our experiments show that it is possible to optimize simulation parameters to enable robots trained in imperfect simulators to generalize learned skills to reality (e.g. improving $SRCC_{Succ}$ from 0.18 to 0.844).
Large-scale Pretraining for Visual Dialog: A Simple State-of-the-Art Baseline
Dec 05, 2019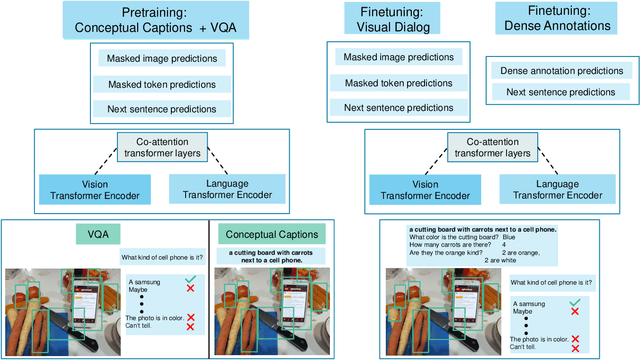

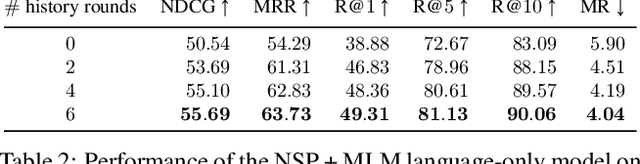
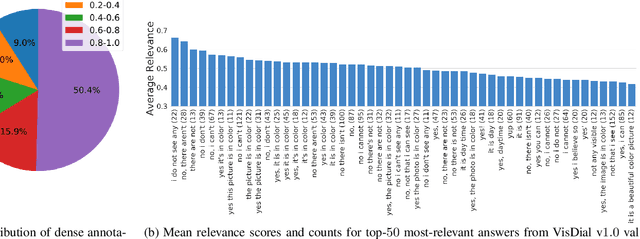
Prior work in visual dialog has focused on training deep neural models on the VisDial dataset in isolation, which has led to great progress, but is limiting and wasteful. In this work, following recent trends in representation learning for language, we introduce an approach to leverage pretraining on related large-scale vision-language datasets before transferring to visual dialog. Specifically, we adapt the recently proposed ViLBERT (Lu et al., 2019) model for multi-turn visually-grounded conversation sequences. Our model is pretrained on the Conceptual Captions and Visual Question Answering datasets, and finetuned on VisDial with a VisDial-specific input representation and the masked language modeling and next sentence prediction objectives (as in BERT). Our best single model achieves state-of-the-art on Visual Dialog, outperforming prior published work (including model ensembles) by more than 1% absolute on NDCG and MRR. Next, we carefully analyse our model and find that additional finetuning using 'dense' annotations i.e. relevance scores for all 100 answer options corresponding to each question on a subset of the training set, leads to even higher NDCG -- more than 10% over our base model -- but hurts MRR -- more than 17% below our base model! This highlights a stark trade-off between the two primary metrics for this task -- NDCG and MRR. We find that this is because dense annotations in the dataset do not correlate well with the original ground-truth answers to questions, often rewarding the model for generic responses (e.g. "can't tell").
Decentralized Distributed PPO: Solving PointGoal Navigation
Nov 01, 2019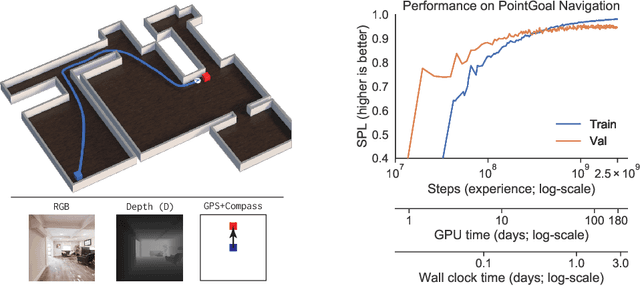

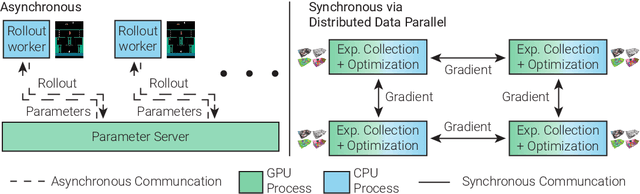
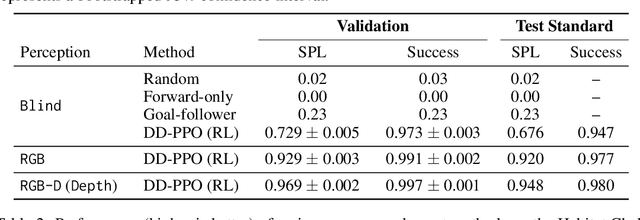
We present Decentralized Distributed Proximal Policy Optimization (DD-PPO), a method for distributed reinforcement learning in resource-intensive simulated environments. DD-PPO is distributed (uses multiple machines), decentralized (lacks a centralized server), and synchronous (no computation is ever "stale"), making it conceptually simple and easy to implement. In our experiments on training virtual robots to navigate in Habitat-Sim, DD-PPO exhibits near-linear scaling -- achieving a speedup of 107x on 128 GPUs over a serial implementation. We leverage this scaling to train an agent for 2.5 Billion steps of experience (the equivalent of 80 years of human experience) -- over 6 months of GPU-time training in under 3 days of wall-clock time with 64 GPUs. This massive-scale training not only sets the state of art on Habitat Autonomous Navigation Challenge 2019, but essentially "solves" the task -- near-perfect autonomous navigation in an unseen environment without access to a map, directly from an RGB-D camera and a GPS+Compass sensor. Fortuitously, error vs computation exhibits a power-law-like distribution; thus, 90% of peak performance is obtained relatively early (at 100 million steps) and relatively cheaply (under 1 day with 8 GPUs). Finally, we show that the scene understanding and navigation policies learned can be transferred to other navigation tasks -- the analog of "ImageNet pre-training + task-specific fine-tuning" for embodied AI. Our model outperforms ImageNet pre-trained CNNs on these transfer tasks and can serve as a universal resource (all models + code will be publicly available).
Improving Generative Visual Dialog by Answering Diverse Questions
Oct 03, 2019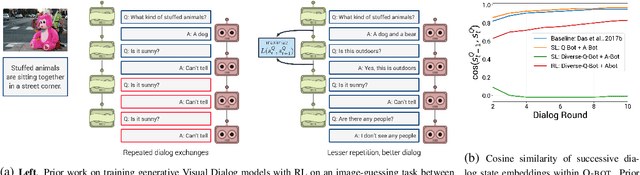

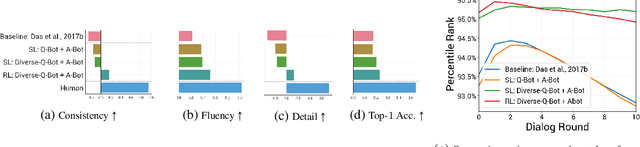

Prior work on training generative Visual Dialog models with reinforcement learning(Das et al.) has explored a Qbot-Abot image-guessing game and shown that this 'self-talk' approach can lead to improved performance at the downstream dialog-conditioned image-guessing task. However, this improvement saturates and starts degrading after a few rounds of interaction, and does not lead to a better Visual Dialog model. We find that this is due in part to repeated interactions between Qbot and Abot during self-talk, which are not informative with respect to the image. To improve this, we devise a simple auxiliary objective that incentivizes Qbot to ask diverse questions, thus reducing repetitions and in turn enabling Abot to explore a larger state space during RL ie. be exposed to more visual concepts to talk about, and varied questions to answer. We evaluate our approach via a host of automatic metrics and human studies, and demonstrate that it leads to better dialog, ie. dialog that is more diverse (ie. less repetitive), consistent (ie. has fewer conflicting exchanges), fluent (ie. more human-like),and detailed, while still being comparably image-relevant as prior work and ablations.
Sequential Latent Spaces for Modeling the Intention During Diverse Image Captioning
Aug 22, 2019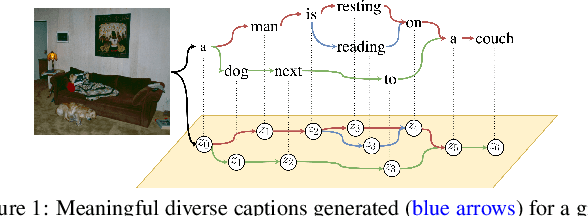
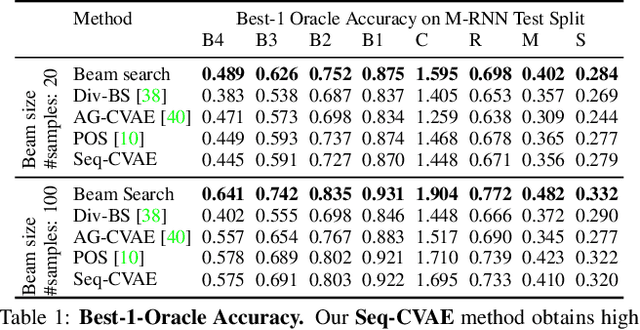
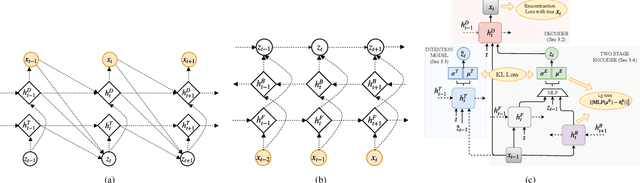
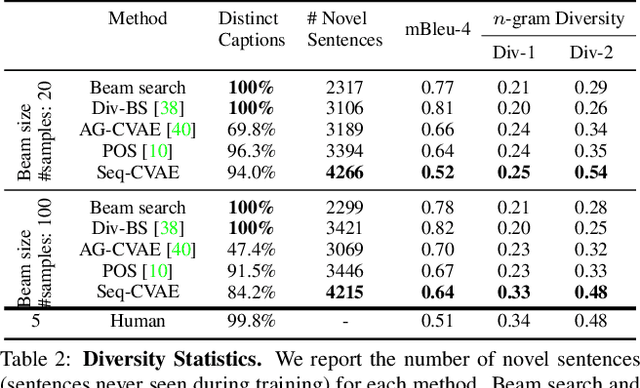
Diverse and accurate vision+language modeling is an important goal to retain creative freedom and maintain user engagement. However, adequately capturing the intricacies of diversity in language models is challenging. Recent works commonly resort to latent variable models augmented with more or less supervision from object detectors or part-of-speech tags. Common to all those methods is the fact that the latent variable either only initializes the sentence generation process or is identical across the steps of generation. Both methods offer no fine-grained control. To address this concern, we propose Seq-CVAE which learns a latent space for every word position. We encourage this temporal latent space to capture the 'intention' about how to complete the sentence by mimicking a representation which summarizes the future. We illustrate the efficacy of the proposed approach to anticipate the sentence continuation on the challenging MSCOCO dataset, significantly improving diversity metrics compared to baselines while performing on par w.r.t sentence quality.
Unsupervised Discovery of Decision States for Transfer in Reinforcement Learning
Aug 15, 2019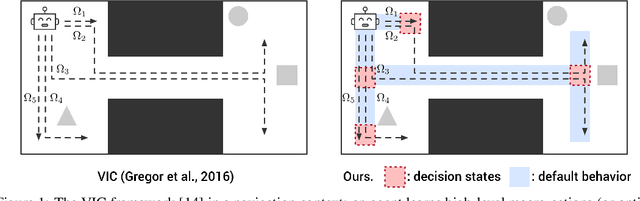
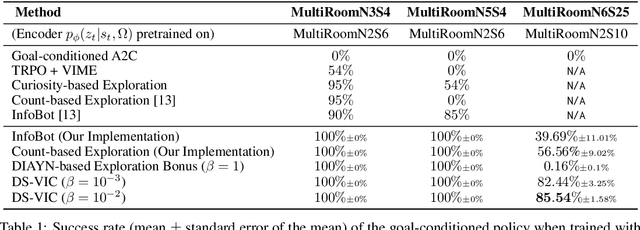
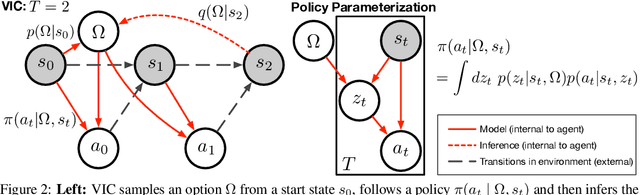
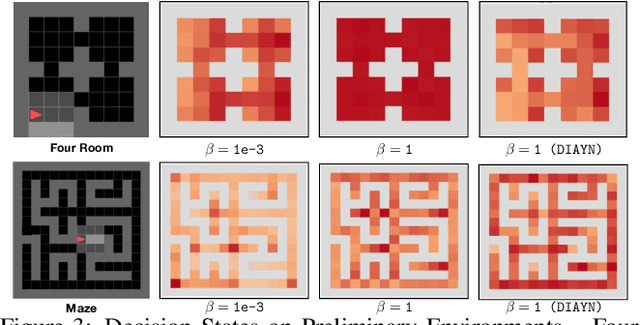
We present a hierarchical reinforcement learning (HRL) or options framework for identifying decision states. Informally speaking, these are states considered important by the agent's policy e.g. , for navigation, decision states would be crossroads or doors where an agent needs to make strategic decisions. While previous work (most notably Goyal et. al., 2019) discovers decision states in a task/goal specific (or 'supervised') manner, we do so in a goal-independent (or 'unsupervised') manner, i.e. entirely without any goal or extrinsic rewards. Our approach combines two hitherto disparate ideas - 1) \emph{intrinsic control} (Gregor et. al., 2016, Eysenbach et. al., 2018): learning a set of options that allow an agent to reliably reach a diverse set of states, and 2) \emph{information bottleneck} (Tishby et. al., 2000): penalizing mutual information between the option $\Omega$ and the states $s_t$ visited in the trajectory. The former encourages an agent to reliably explore the environment; the latter allows identification of decision states as the ones with high mutual information $I(\Omega; a_t | s_t)$ despite the bottleneck. Our results demonstrate that 1) our model learns interpretable decision states in an unsupervised manner, and 2) these learned decision states transfer to goal-driven tasks in new environments, effectively guide exploration, and improve performance.
ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
Aug 06, 2019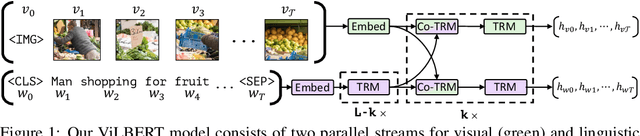
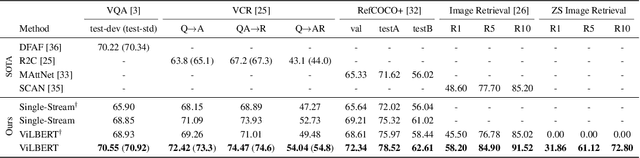
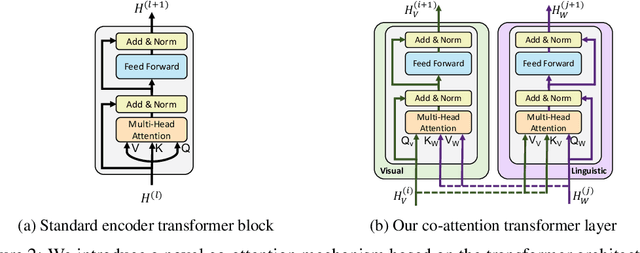

We present ViLBERT (short for Vision-and-Language BERT), a model for learning task-agnostic joint representations of image content and natural language. We extend the popular BERT architecture to a multi-modal two-stream model, pro-cessing both visual and textual inputs in separate streams that interact through co-attentional transformer layers. We pretrain our model through two proxy tasks on the large, automatically collected Conceptual Captions dataset and then transfer it to multiple established vision-and-language tasks -- visual question answering, visual commonsense reasoning, referring expressions, and caption-based image retrieval -- by making only minor additions to the base architecture. We observe significant improvements across tasks compared to existing task-specific models -- achieving state-of-the-art on all four tasks. Our work represents a shift away from learning groundings between vision and language only as part of task training and towards treating visual grounding as a pretrainable and transferable capability.